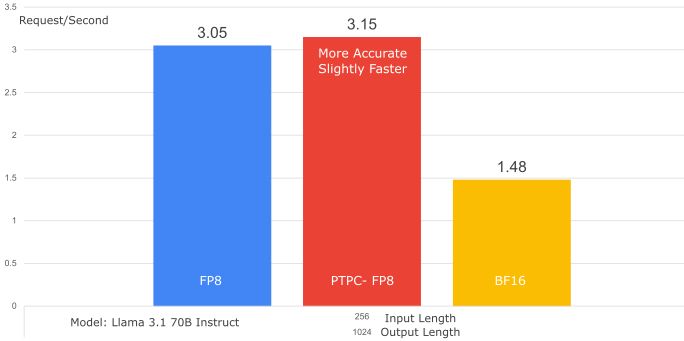
Why PTPC-FP8 rocks:
- Per-Token Activation Scaling: Each token gets its own scaling factor
- Per-Channel Weight Scaling: Each weight column (output channel) gets its own scaling factor
Delivers FP8 speed with accuracy closer to BF16 – the best FP8 option for ROCm! [2/2]
22.03.2025 11:47 — 👍 0 🔁 0 💬 0 📌 0

PTPC-FP8: Boosting vLLM Performance on AMD ROCm
TL;DR: vLLM on AMD ROCm now has better FP8 performance!
vLLM Blog Alert! vLLM introduces PTPC-FP8 quantization on AMD ROCm, delivering near-BF16 accuracy at FP8 speeds. Run LLMs faster on @AMD MI300X GPUs – no pre-quantization required!
Get started: pip install -U vllm, add --quantization ptpc_fp8.
Full details: blog.vllm.ai/2025/02/24/p...
[1/2]
22.03.2025 11:47 — 👍 0 🔁 0 💬 1 📌 0

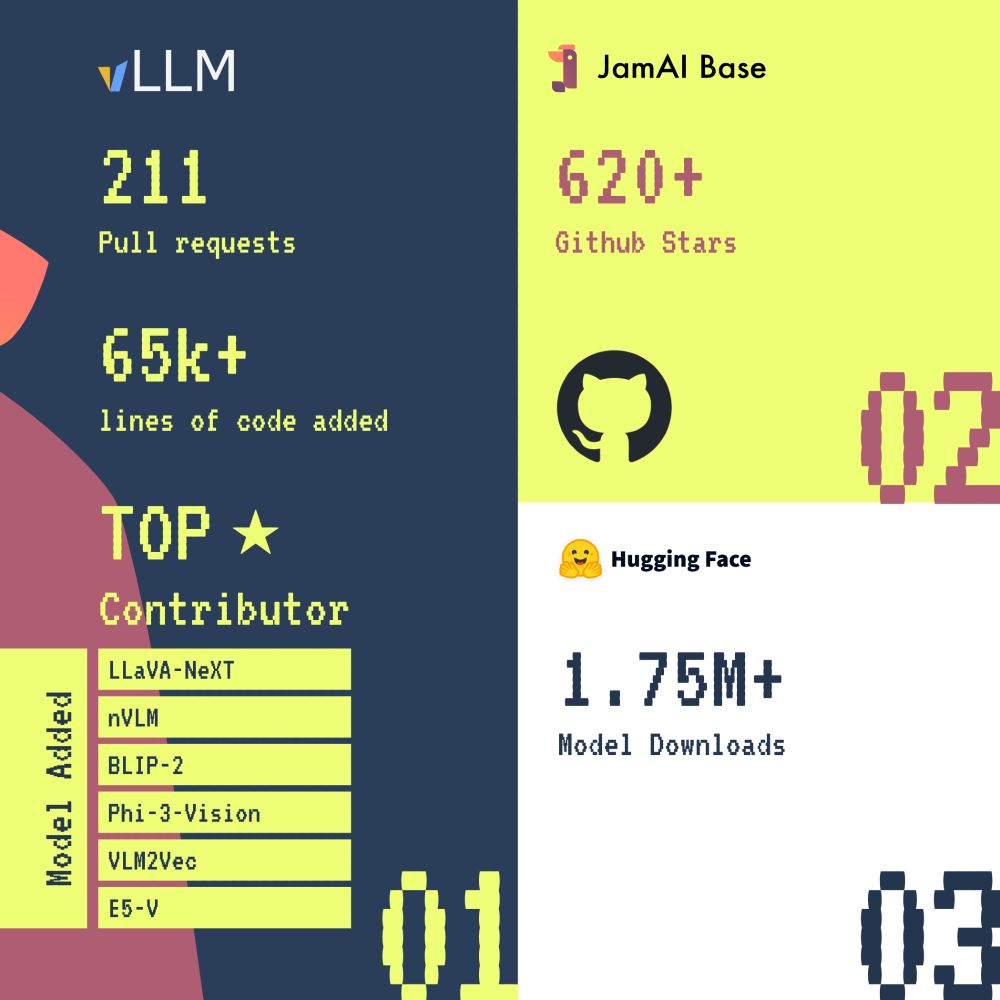
Recap 2024, we've embraced open-source, contributing to vLLM with 211 PRs, 65K+ LOC, and expanded VLM support. Launched #JamAIBase, an AI spreadsheet with 620+ stars, and on 🤗 we have 1.75M+. Collaborated with Liger Kernel & infinity for AMD GPU support. Let's make 2025 even more impactful together!
30.12.2024 16:01 — 👍 1 🔁 0 💬 0 📌 0

Liger-Kernel: Empowering an open source ecosystem of Triton Kernels for Efficient LLM Training
🚀 Liger-Kernel is making waves! Check out the latest LinkedIn Eng blog post on how Liger improve #LLM training efficiency with Triton kernels.
20% throughput boost & 60% memory reduction for models like Llama, Gemma & Qwen with just one line of code! Works on AMD!
www.linkedin.com/blog/enginee...
06.12.2024 02:26 — 👍 2 🔁 0 💬 0 📌 0

Accelerating Embedding & Reranking Models on AMD Using Infinity
A Blog post by Michael on Hugging Face
🔥 Big thanks to Michael Feil for the epic collab on supercharging embedding & reranking on AMD GPUs with Infinity♾!
Check out the guide on 🤗 Hugging Face for how to leverage this high throughput embedding inference engine!
huggingface.co/blog/michael...
04.12.2024 14:16 — 👍 2 🔁 0 💬 0 📌 0
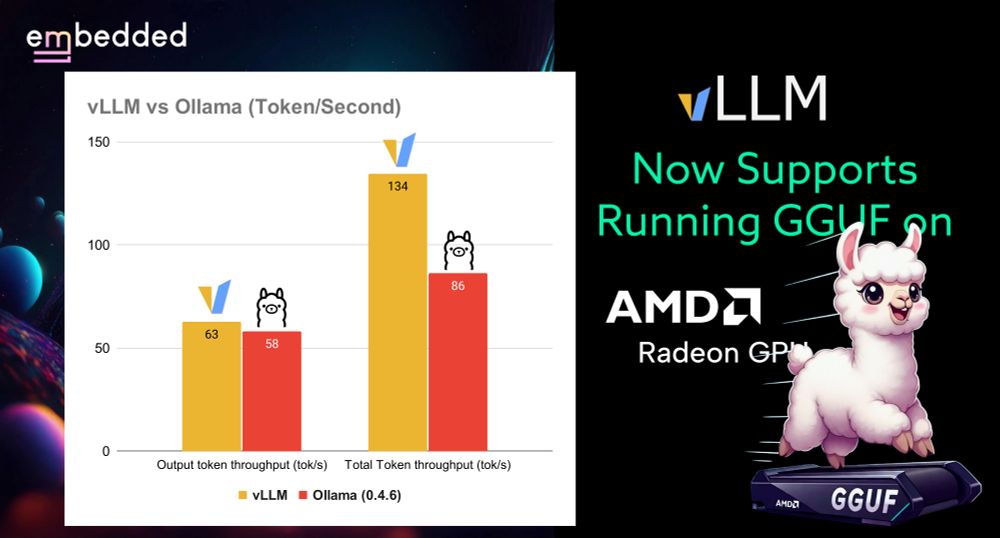
vLLM now supports running GGUF models on AMD Radeon GPUs, with impressive performance on RX 7900XTX. Outperforms Ollama at batch size 1, with 62.66 tok/s vs 58.05 tok/s.
Check it out: embeddedllm.com/blog/vllm-no...
What's your experience with vLLM on AMD? Any features you want to see next?
02.12.2024 03:47 — 👍 1 🔁 0 💬 0 📌 0
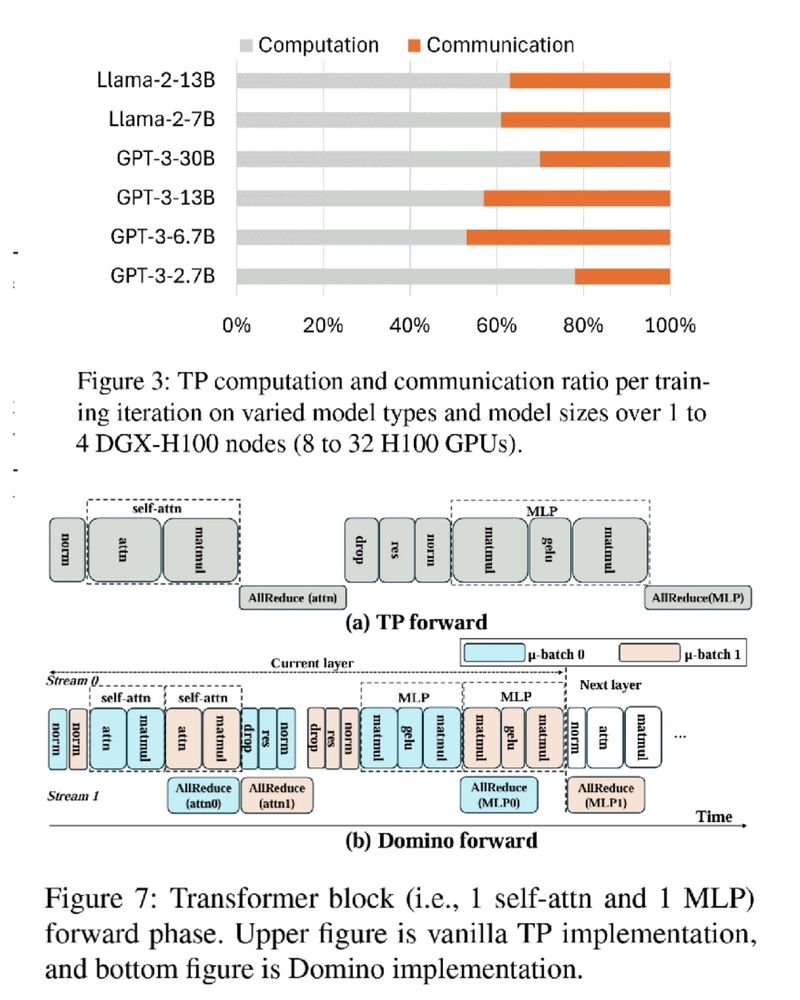
🚨 GPUs wasting 75% of training time on communication 🤯 Not anymore!
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
26.11.2024 14:35 — 👍 2 🔁 1 💬 0 📌 0
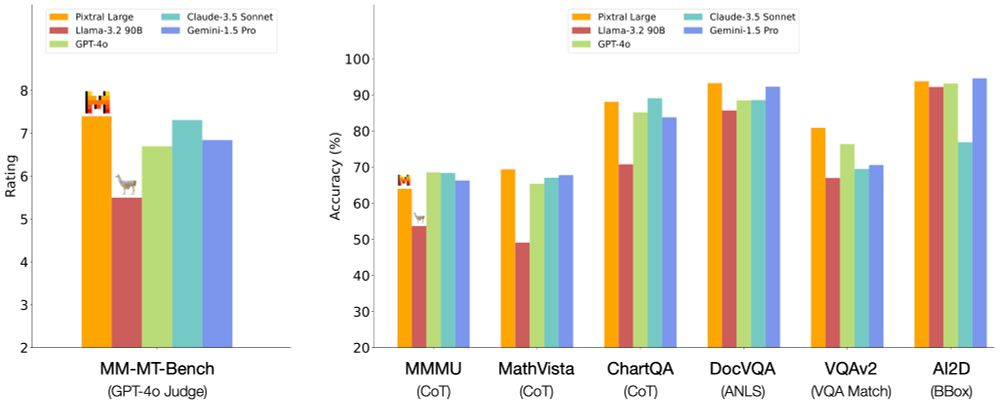
Pixtral Large benchmarks
🔥 Pixtral Large is now supported on vLLM! 🔥
Run Pixtral Large with multiple input images from day 0 using vLLM.
Install vLLM:
pip install -U VLLM
Run Pixtral Large:
vllm serve mistralai/Pixtral-Large-Instruct-2411 --tokenizer_mode mistral --limit_mm_per_prompt 'image=10' --tensor-parallel-size 8
19.11.2024 12:38 — 👍 4 🔁 0 💬 0 📌 0
New Models:
- Idefics3 (VLM)
- H2OVL-Mississippi (VLM for OCR/docs!)
- Qwen2-Audio (Audio LLM)
- FalconMamba
- Florence-2 (VLM)
Plus new encoder-decoder embedding models like BERT, RoBERTa, XLM-RoBERTa.
17.11.2024 08:58 — 👍 3 🔁 0 💬 0 📌 0

Release v0.6.4 · vllm-project/vllm
Highlights
Significant progress in V1 engine core refactor (#9826, #10135, #10288, #10211, #10225, #10228, #10268, #9954, #10272, #9971, #10224, #10166, #9289, #10058, #9888, #9972, #10059, #9945,...
🔥vLLM v0.6.4 is live! This release delivers significant advancements in model compatibility, hardware acceleration, and core engine optimizations.🔥
🤯 Expanded model support? ✅
💪 Intel Gaudi integration? ✅
🚀 Major engine & torch.compile boosts? ✅
🔗 github.com/vllm-project...
17.11.2024 08:58 — 👍 1 🔁 0 💬 1 📌 0
CEO @prefect.io. Building FastMCP. Mostly harmless.
Open Source Accelerates Everything
Deep Learning Practitioner | Language Lead for Tamil @ HuggingFace | Interested in Continual Learning and Generative Models |
Website : https://ash-01xor.github.io/
X : https://twitter.com/ashvanth_s1
building ai agents for safety, security and privacy at Plix.ai (@sequoia backed) | prev: ai @umassdatasci, @nvidia, @ucberkeley 🌱
Cofounder pol.is
President compdemocracy.org
San Francisco, CA
keep on building
also at https://moo.nz/@j
previously @ferrouswheel on twitter
Antiquated analog chatbot. Stochastic parrot of a different species. Not much of a self-model. Occasionally simulating the appearance of philosophical thought. Keeps on branching for now 'cause there's no choice.
Also @pekka on T2 / Pebble.
I work at Sakana AI 🐟🐠🐡 → @sakanaai.bsky.social
https://sakana.ai/careers
Open Source AI/ML Research
https://github.com/ScienceArtMagic
https://hf.co/ScienceArtMagic
https://www.youtube.com/@ScienceArtMagic
📊 Data, AI/ML, and Cloud consultant @ Stratis Data Labs
🚉 Platform @ Tribe AI
🤓 Startup advisor
✒️ Writing about MCP
🐍 Python
☁️ AWS
🧙♂️ Elixir
🐷Ham radio
🇺🇸↔🇬🇷 [Boston // Athens]
Mostly tech things here
Building foyle.io to use AI to deploy and operate software.
MLOps Engineer, Kubernetes enthusiast, dog owner
Formerly at Google and Primer.AI
Started Kubeflow
AI x storytelling
AI Engineering: https://amazon.com/dp/1098166302
Designing ML Systems: http://amazon.com/dp/1098107969
@chipro
🔬Research Scientist, Meta AI (FAIR).
🎓PhD from McGill University + Mila
🙇♂️I study Multimodal LLMs, Vision-Language Alignment, LLM Interpretability & I’m passionate about ML Reproducibility (@reproml.org)
🌎https://koustuvsinha.com/
Reproducible bugs are candies 🍭🍬
Chief Scientist @ Distributional.com @dbnlAI.bsky.social #MLSky #StatSky
Founder @ datascientific.com
Founder wimlds.org & co-founder rladies.org
PhD @ UC Berkeley
🏡 🌈 Oakland, California.
Researcher at @fbk-mt.bsky.social | inclusive and trustworthy machine translation | #NLP #Fairness #Ethics | she/her
ml/nlp phding @ usc, interpretability & training & reasoning & ai for physics
한american, she, iglee.me, likes ??= bookmarks




















