

Qwen3-next-80B-A3B 👀
Only 3B active parameters and almost as good (in benchmarks) as Qwen3-235B-A22B and Qwen3-32B.

@axelgarciak.bsky.social
👨💻 Software Engineer 💾 Software minimalist/retro 🤖 AI tinkerer 🏗️ Building tech communities 🇪🇺 UK 🇬🇧🇩🇪🇻🇪 | Check bio: axelgarciak.com/bio
Qwen3-next-80B-A3B 👀
Only 3B active parameters and almost as good (in benchmarks) as Qwen3-235B-A22B and Qwen3-32B.
LoRA: ai.google.dev/gemma/docs/c...
16.08.2025 19:31 — 👍 1 🔁 0 💬 0 📌 0
Gemma 3 270M (Million not Billion) released.
I keep a close-eye to small models, and this one is a great win.
I've seen some tests and it is clever enough despite its size, but the main purpose is to fine-tune it to do specialized tasks.
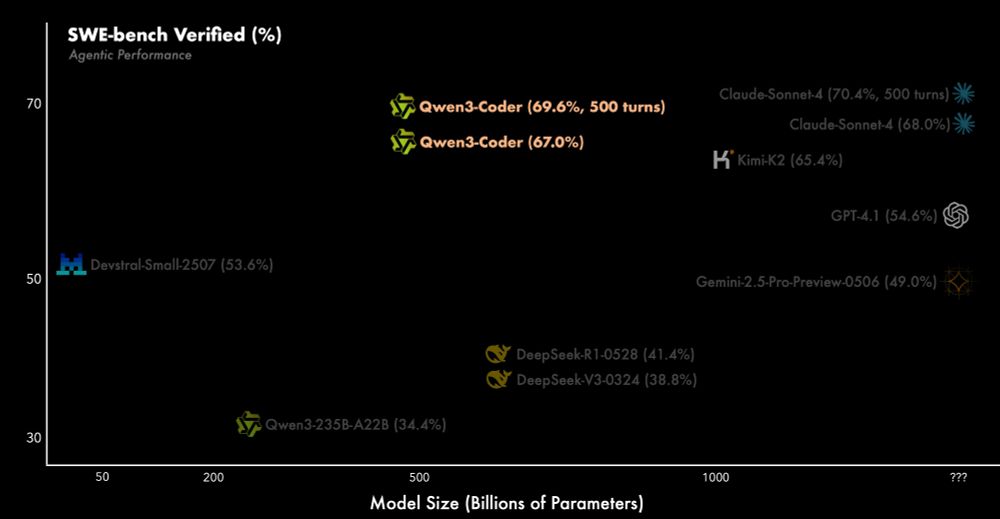
Qwen3-coder seems to be great 👀
22.07.2025 22:40 — 👍 6 🔁 2 💬 1 📌 0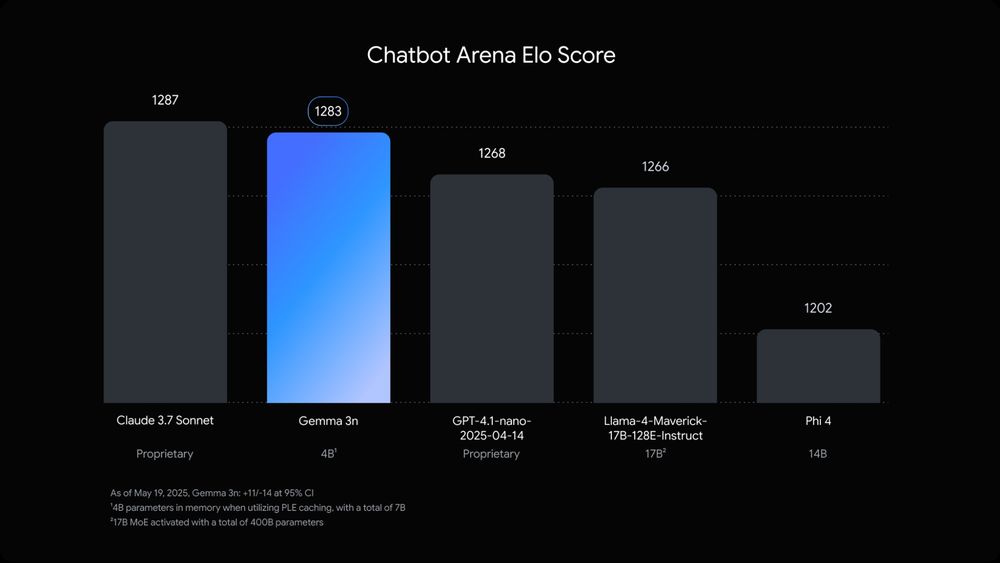
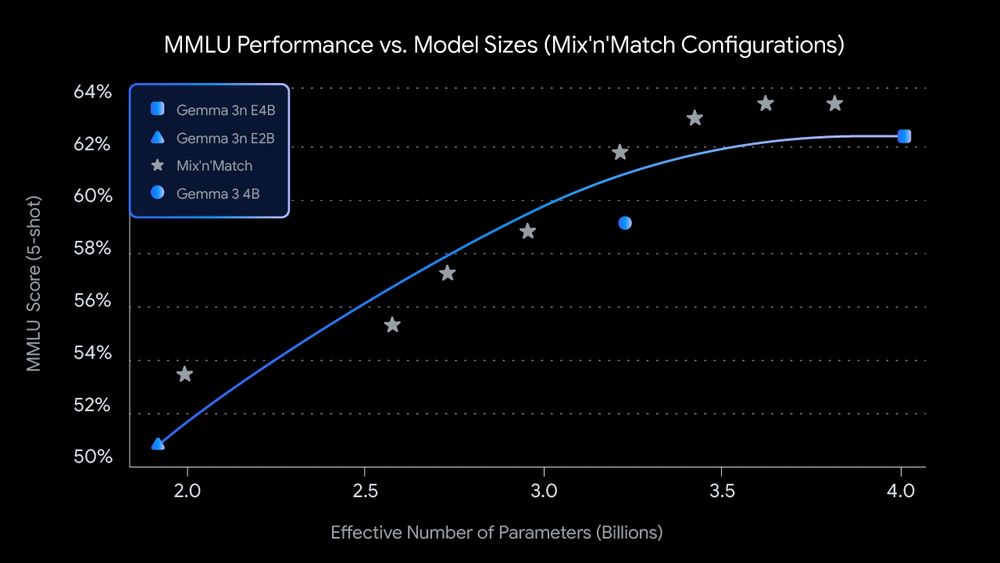
So many great announcements at Google I/O that is hard to put on a list.
I like Gemma 3n. They are decent lightweight models to run offline on smartphones.
They have 5B and 8B raw parameters but are comparable with the memory footprint of 2B to 4B models!
Many good releases from open and closed-source providers. I'm eagerly waiting for what DeepSeek is going to release.
01.05.2025 16:45 — 👍 2 🔁 0 💬 0 📌 0Companies should release their AI models/LLM as soon as possible.
That way they don't have to compare themselves to Qwen3 or DeepSeek r2 and distill versions.
The more they wait, the more embarrassing it will be when they don't compare their model to those two. 😅
They are good! Obviously not what you get from models like O4-mini, Claude 3.7 or Gemini 2.5 Pro.
But they are great for local use cases.
It's nice that they are hybrid, i.e: thinking can be deactivated.
Qwen2.5 was already the best in its class for a while! Hopefully we'll get a Coder fine-tune!
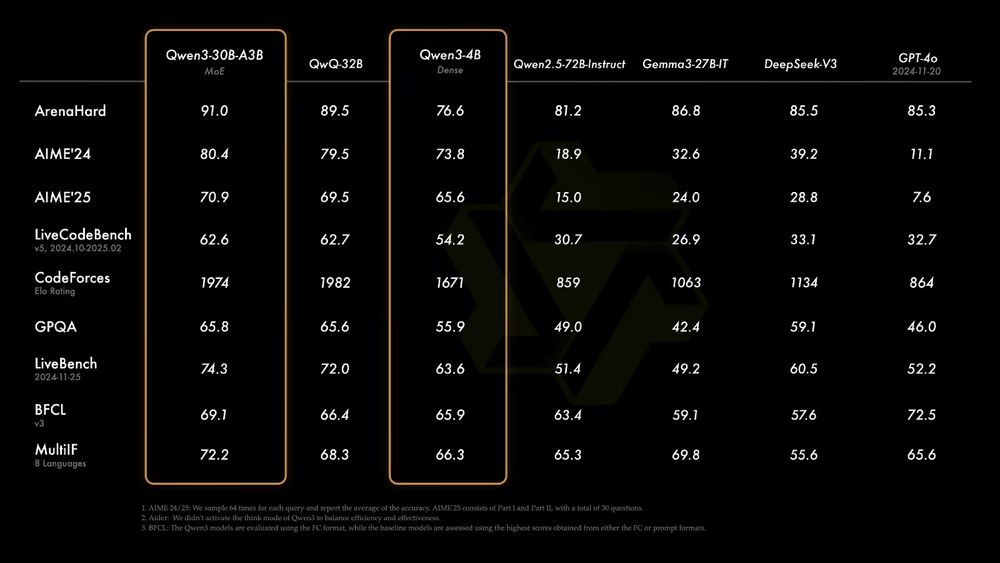
Qwen3 is the ultimate GPU-Poor LLM!
Qwen3 4B and 8B are good for many use cases. Even Qwen3 0.6B seems coherent.
Qwen3-30B-A3 can be run with 4GB VRAM with enough system RAM.
I ran it on 4GB VRAM and got 12tok/s!
Yeah benchmarks don't translate fully to real use cases. Claude is still king for coding.
12.03.2025 20:21 — 👍 2 🔁 0 💬 1 📌 0Of course benchmarks will differ from real life use cases.
However, previous Gemma models were quite good relative to their size, so I'm sure Gemma 3 is really good!
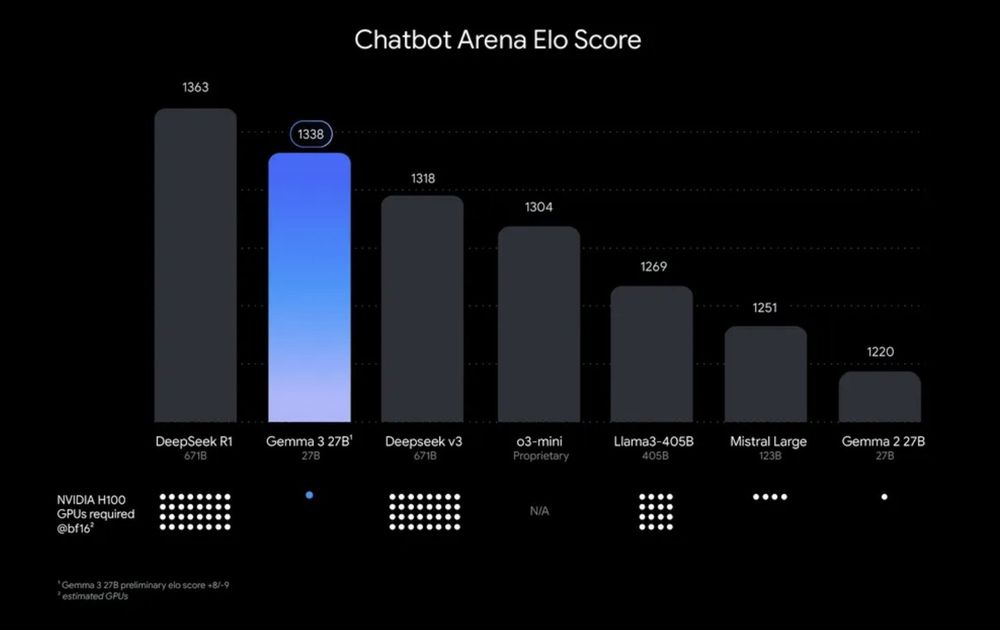
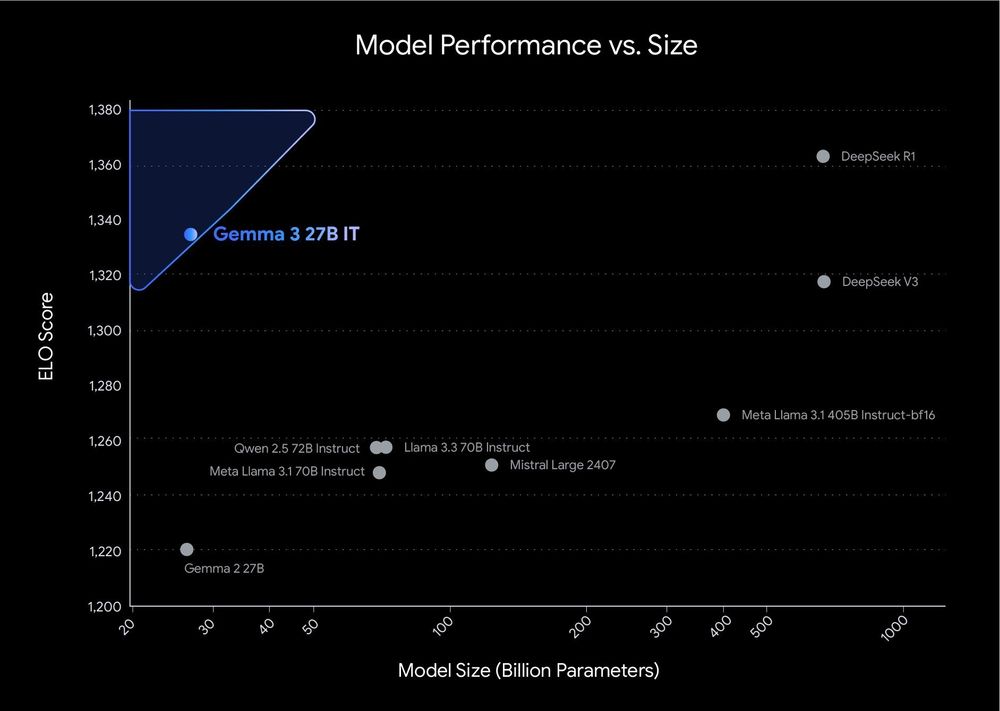
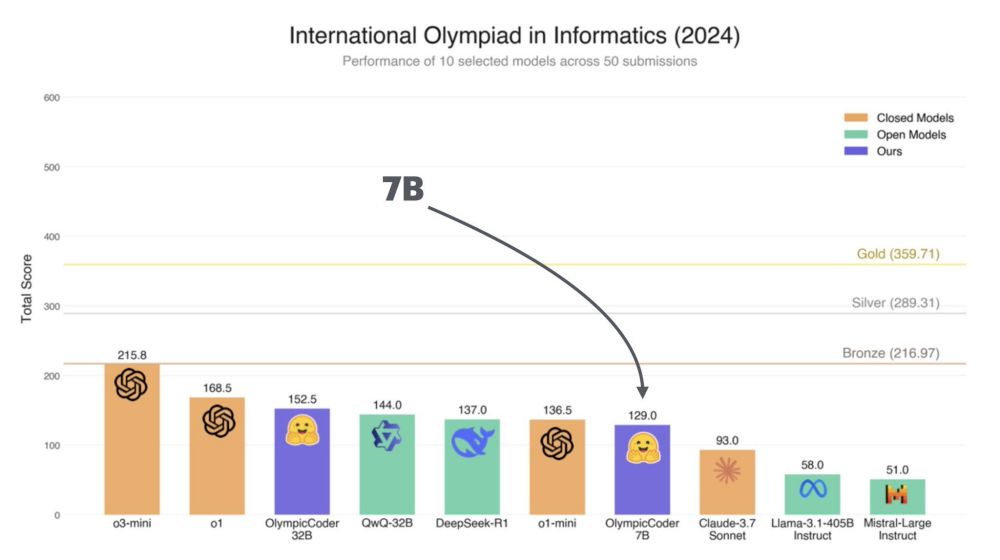
Good to see smaller LLMs pushing the pareto frontier of size vs performance.
Gemma 3 27B by Google DeepMind was released with performance between DeepSeek V3 and R1.
OlympicCoder 7B by Hugging Face with better performance than Claude 3.7 in Olympiad-Level Programming Problems.
It has been happening for a while before ChatGPT came out, but you're right in that it will accelerate.
19.01.2025 20:59 — 👍 3 🔁 0 💬 0 📌 0It is useful indeed, I use it every day, but it's far from being AGI or ASI.
19.01.2025 20:58 — 👍 4 🔁 0 💬 0 📌 0The debate around AI is polarized: either it's taking our jobs tomorrow or it's just hype.
Anyone who's actually used AI for longer than a few minutes knows the truth is far less sensational.
Debian or Fedora if you want mainstream distros.
14.01.2025 04:48 — 👍 4 🔁 0 💬 1 📌 0I like that AMD has technologies that are more widely applicable, such as FSR, but as usual NVIDIA's is on the lead with the DLSS 4 technology.
13.01.2025 21:45 — 👍 4 🔁 0 💬 2 📌 0Yeah frame interpolation is also cool. The key difference is that interpolation is reactive (analyzing past frames), DLSS is predictive (anticipating future frames).
13.01.2025 21:41 — 👍 3 🔁 0 💬 1 📌 0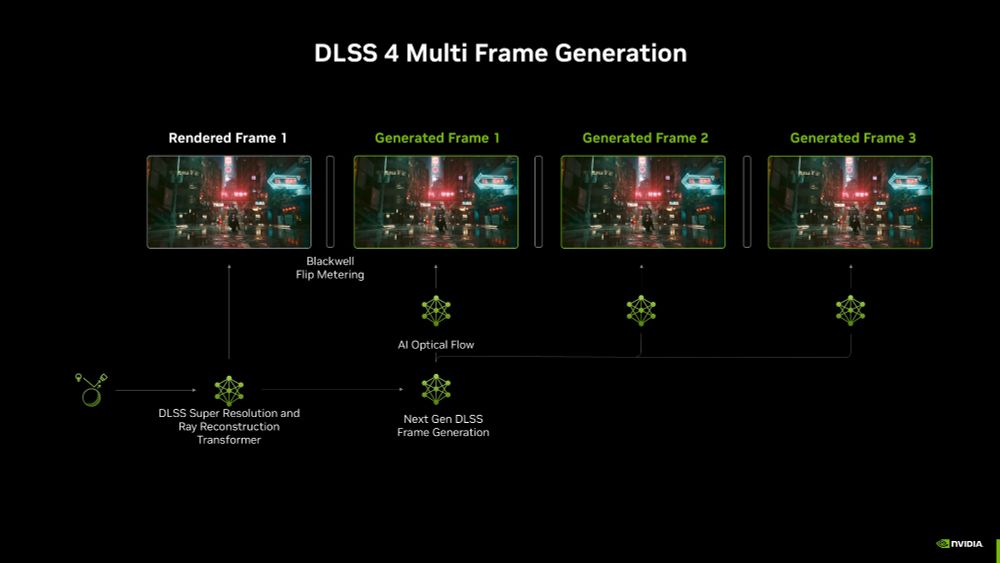
One of the coolest AI use cases I've read about recently is DLSS 4 for NVIDIA GPUs.
DLSS stands for Deep Learning Super Sampling.
Games use DLSS AI to predict multiple frames and improve image quality/upscaling.
That allows lower-spec GPUs to play at higher resolutions/FPS!
ncdu ftw!
13.01.2025 02:58 — 👍 3 🔁 0 💬 1 📌 0Gotta account for those days when the OpenAI API is down 😏
12.01.2025 15:18 — 👍 3 🔁 0 💬 0 📌 0Dave is a 10xer.
12.01.2025 09:46 — 👍 4 🔁 0 💬 0 📌 0Made-up tech news headline #1:
Tech CEO Replaces Dev Team with AI, Only to Be Ousted by Ex-Employee's AI-Powered SAAS One Month Later.
Interesting text-to-video model preserving transparency: TransPixar.
10.01.2025 10:05 — 👍 23 🔁 2 💬 0 📌 0Agreed. To their credit, these newer GPUs have fp4 support whereas before you had to run at fp8 even when running fp4 calculations.
If you were to use fp4 exclusively, there is an advantage in speed from these newer GPUs.
If you use fp8 there is still an improvement but far less than advertised.
Yeah, misleading marketing unfortunately.
07.01.2025 13:43 — 👍 0 🔁 0 💬 1 📌 0
Nvidia announced Project Digits, a personal AI supercomputer launching in May for $3K:
- Powered by GB10 Grace Blackwell Superchip.
- 128GB of unified memory.
- Can be linked to run bigger models.
It's kind of the Linux version of Mac Mini with 2x memory but 1.5x price.
Hired!
04.01.2025 17:58 — 👍 0 🔁 0 💬 0 📌 0Made-up tech role #27:
Senior Overengineer.
Why use one line of code when you can use 100?
- Turns simple tasks into complex microservices.
- Believes every app needs AI, blockchain, and a custom-built framework.
- Thinks “scalability” is more important than functionality.

Made-up tech role #26:
Agile Stand-Up Philosopher.
Turns 15-minute meetings into existential debates.















