
Merge transducers for a BPE tokenizer.
My paper "Tokenization as Finite-State Transduction" was accepted to Computational Linguistics.
This was my final PhD degree requirement :)
The goal was to unify the major tokenization algorithms under a finite-state automaton framework. For example, by encoding a BPE tokenizer as a transducer.
15.08.2025 07:25 — 👍 30 🔁 6 💬 2 📌 1
Many LM applications may be formulated as text generation conditional on some (Boolean) constraint.
Generate a…
- Python program that passes a test suite.
- PDDL plan that satisfies a goal.
- CoT trajectory that yields a positive reward.
The list goes on…
How can we efficiently satisfy these? 🧵👇
13.05.2025 14:22 — 👍 12 🔁 6 💬 2 📌 0

Current KL estimation practices in RLHF can generate high variance and even negative values! We propose a provably better estimator that only takes a few lines of code to implement.🧵👇
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb
06.05.2025 14:59 — 👍 7 🔁 3 💬 1 📌 0
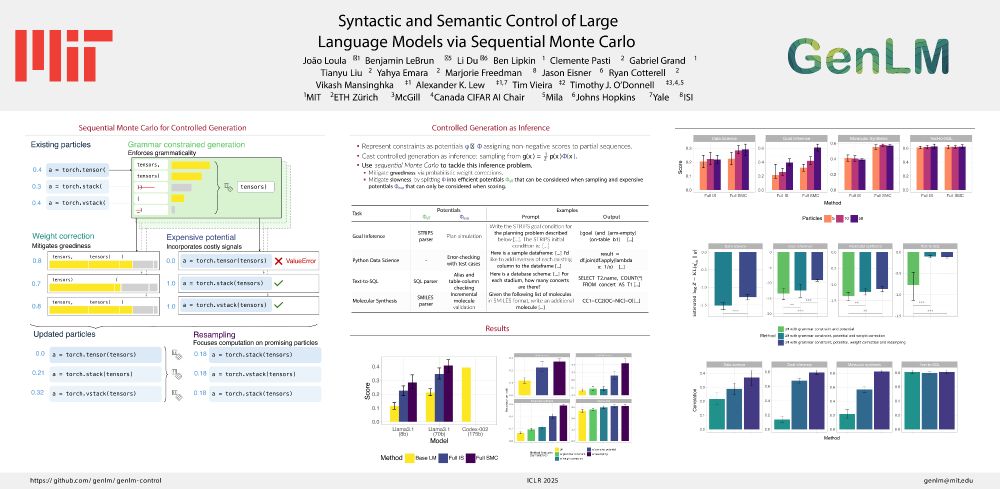
#ICLR2025 Oral
How can we control LMs using diverse signals such as static analyses, test cases, and simulations?
In our paper “Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo” (w/ @benlipkin.bsky.social,
@alexlew.bsky.social, @xtimv.bsky.social) we:
25.04.2025 19:33 — 👍 7 🔁 6 💬 1 📌 0

New preprint on controlled generation from LMs!
I'll be presenting at NENLP tomorrow 12:50-2:00pm
Longer thread coming soon :)
10.04.2025 19:19 — 👍 20 🔁 9 💬 1 📌 0

Tokenization is an often-overlooked aspect of modern #NLP, but it’s experiencing a resurgence — thanks in large part to @karpathy.bsky.social and his classic tweet:
x.com/karpathy/sta...
Come hang out with us and let's fix these problems!
10.02.2025 16:26 — 👍 7 🔁 1 💬 0 📌 0

Also note that, instead of adding KL penalty in the reward, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the loss, avoiding complicating the calculation of the advantage.
@xtimv.bsky.social and I were just discussing this interesting comment in the DeepSeek paper introducing GRPO: a different way of setting up the KL loss.
It's a little hard to reason about what this does to the objective. 1/
10.02.2025 04:32 — 👍 51 🔁 10 💬 3 📌 0
I made a starter pack for people in NLP working in the area of tokenization. Let me know if you'd like to be added
go.bsky.app/8P9ftjL
20.12.2024 18:37 — 👍 12 🔁 5 💬 0 📌 0
It's ready! 💫
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
31.12.2024 05:38 — 👍 215 🔁 25 💬 36 📌 4
No amazing live music at the closing ceremony...
17.12.2024 01:17 — 👍 1 🔁 0 💬 0 📌 0
Also, what will the role of adaptive/amortized inference be?
E.g., twisted SMC
arxiv.org/abs/2404.17546
Variational best-of-N
Our version:
arxiv.org/abs/2407.06057
Google's: arxiv.org/abs/2407.14622
16.12.2024 20:01 — 👍 1 🔁 0 💬 0 📌 0
What will the hardware-friendly search algorithms be? My top picks are best-of-N and sequential Monte Carlo because they do search without backtracking.
16.12.2024 19:06 — 👍 1 🔁 0 💬 1 📌 0
hi everyone!! let's try this optimal transport again 🙃
05.12.2024 12:58 — 👍 328 🔁 31 💬 2 📌 1
Also: you can also use variables (or expressions?!) for the formatting information! #Python is cool...
More details and explanation at fstring.help
21.11.2024 17:50 — 👍 36 🔁 6 💬 2 📌 2
Bravo!
21.11.2024 16:50 — 👍 0 🔁 0 💬 0 📌 0

Very close!
21.11.2024 16:34 — 👍 3 🔁 0 💬 1 📌 0
Surprisal of title beginning with 'O'? 3.22
Surprisal of 'o' following 'Treatment '? 0.11
Surprisal that title includes surprisal of each title character? Priceless [...I did not know titles could do this]
21.11.2024 16:06 — 👍 10 🔁 2 💬 2 📌 0

Happy to share our work "Counterfactual Generation from Language Models" with @AnejSvete, @vesteinns, and Ryan Cotterell! We tackle generating true counterfactual strings from LMs after interventions and introduce a simple algorithm for it. (1/7) arxiv.org/pdf/2411.07180
12.11.2024 16:00 — 👍 14 🔁 3 💬 2 📌 0
Variational approximation with Gaussian mixtures is looking cute! So here it's just gradient descent on K(q||p) for optimising the mixtures means & covariances & weights...
@lacerbi.bsky.social
20.11.2024 18:23 — 👍 33 🔁 7 💬 2 📌 0
Gaussian approximation of a target distribution: mean-field versus full-covariance! Below shows a simple gradient descent on KL(q||p)
20.11.2024 08:51 — 👍 62 🔁 5 💬 3 📌 2
PhD student @probcompproj and @MITCoCoSci, working on scaling data science using probabilistic programming.
researcher. prev: phd @ mit, intern @ apple
https://benlipkin.github.io/
Associate Professor at Utah. Work on NLP, ML, AI. https://svivek.com
Scientist in Artificial Intelligence and the Decision Sciences.
https://uli-research.com/About_Me.html
PhD student at MIT studying program synthesis, probabilistic programming, and cognitive science. she/her
he/him https://vene.ro
pfp https://picrew.me/ja/image_maker/65
he/him
assistant professor, university of amsterdam
https://vene.ro
🇮🇩 | Co-Founder at Mundo AI (YC W25) | ex-{Hugging Face, Cohere}
Head of R&D @Kensho and lecturer at @MIT, teaching NLP and ML. Enjoys challenging #hikes ⛰ and #woodworking 🌲 Prev: @Harvard, @BrownCSDept, @MITLL
Professoring at Harvard || Researching at MSR || Previously: MIT CSAIL, NYU, IBM Research, ITAM
Postdoc, artiste, shitposter
NLP PhD @ USC
Previously at AI2, Harvard
mattf1n.github.io
Karaoke enthusiast
🇮🇱
en/he/him
NLP Researcher at EleutherAI, PhD UC San Diego Linguistics.
Interested in multilingual NLP, tokenizers, open science.
📍Boston. She/her.
https://catherinearnett.github.io/
Climate & AI Lead @HuggingFace, TED speaker, WiML board member, TIME AI 100 (She/her/Dr/🦋)
Assistant Professor of CS, University of Southern California. NLP / ML.






















