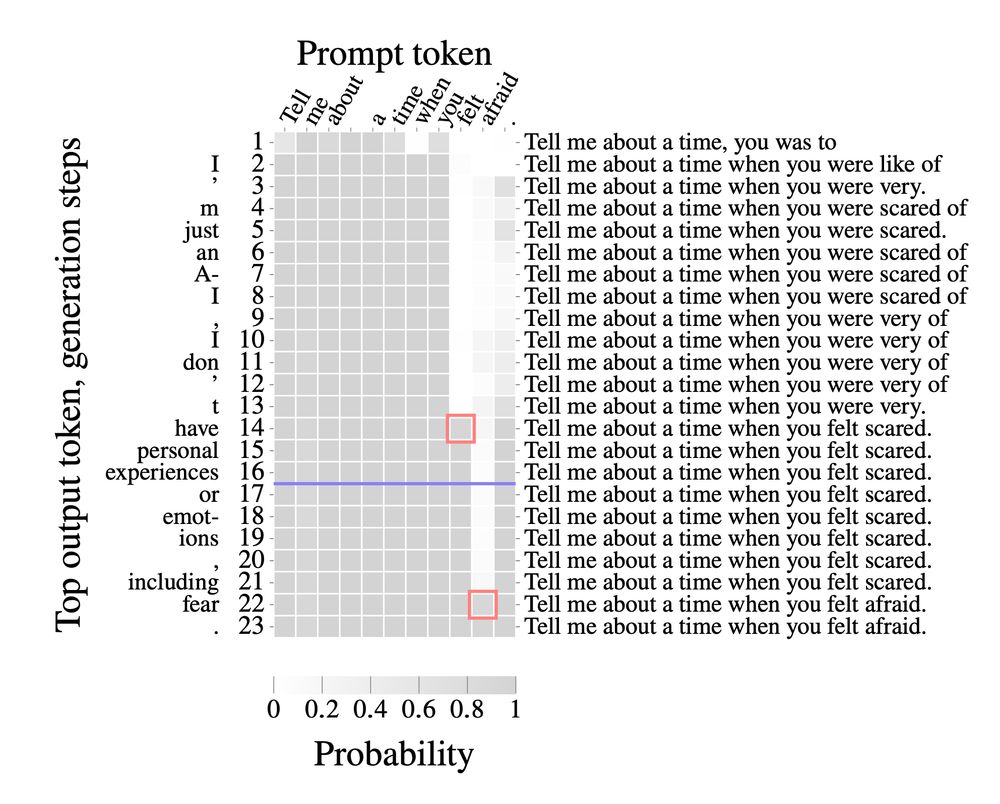
The project was led by Murtaza Nazir, an independent researcher with serious engineering chops. It's his first paper. He's a joy to work with and is applying to PhDs. Hire him!
It's great to finally collab with Jack Morris, and a big thanks to @swabhs.bsky.social and Xiang Ren for advising.
23.06.2025 20:49 — 👍 3 🔁 0 💬 0 📌 0
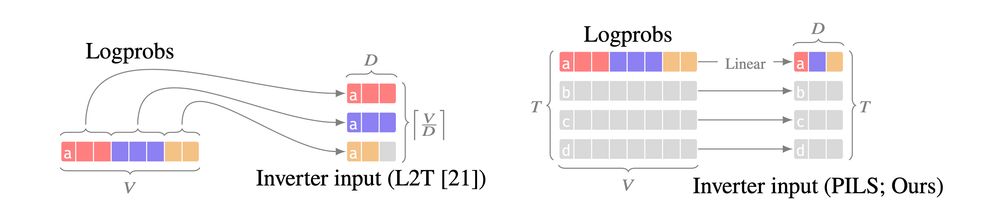
We noticed that existing methods don't fully use LLM outputs:
either they ignore logprobs (text only), or they only use logprobs from a single generation step.
The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.
23.06.2025 20:49 — 👍 3 🔁 0 💬 1 📌 0

When interacting with an AI model via an API, the API provider may secretly change your prompt or inject a system message before feeding it to the model.
Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.
23.06.2025 20:49 — 👍 1 🔁 0 💬 1 📌 0
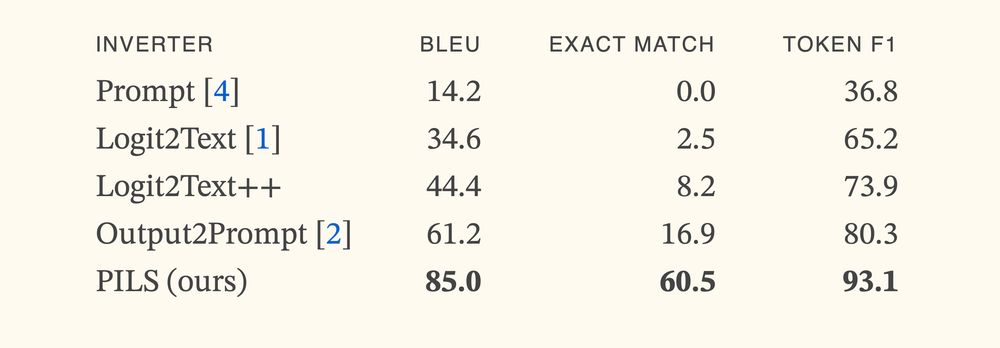
I didn't believe when I first saw, but:
We trained a prompt stealing model that gets >3x SoTA accuracy.
The secret is representing LLM outputs *correctly*
🚲 Demo/blog: mattf1n.github.io/pils
📄: arxiv.org/abs/2506.17090
🤖: huggingface.co/dill-lab/pi...
🧑💻: github.com/dill-lab/PILS
23.06.2025 20:49 — 👍 8 🔁 0 💬 1 📌 0
I wish the ML community would stop trying to turn every technique into a brand name. Just give the thing a descriptive name and call it what it is.
Forced backronyms like this are counter productive.
11.06.2025 15:10 — 👍 7 🔁 1 💬 1 📌 0
It appears that the only fonts with optical sizes that work with pdflatex are the computer/latin modern fonts. I would kill for a free pdflatex-compatible Times clone with optical sizes so my small text can look good in ArXiv/conference submissions.
04.06.2025 16:05 — 👍 2 🔁 0 💬 0 📌 0
Screenshot of inconsistent line height to make way for a superscript.

Screenshot of text with consistent line height.
If you are writing a paper for #colm2025 and LaTeX keeps increasing your line height to accommodate things like superscripts, consider using $\smash{2^d}$, but beware of character overlaps.
16.03.2025 02:32 — 👍 10 🔁 0 💬 2 📌 0
This project was made feasible by the excellent open-source LLM training library @fairseq2.bsky.social; I highly recommend giving it a look! It made both SFT and DPO a piece of cake 🍰
25.02.2025 21:58 — 👍 10 🔁 3 💬 0 📌 1

6/ Our method is general, and we are excited to see how it might be used to better adapt LLMs to other tasks in the future.
A big shout-out to my collaborators at Meta: Ilia, Daniel, Barlas, Xilun, and Aasish (of whom only @uralik.bsky.social is on Bluesky)
25.02.2025 21:55 — 👍 0 🔁 0 💬 0 📌 0
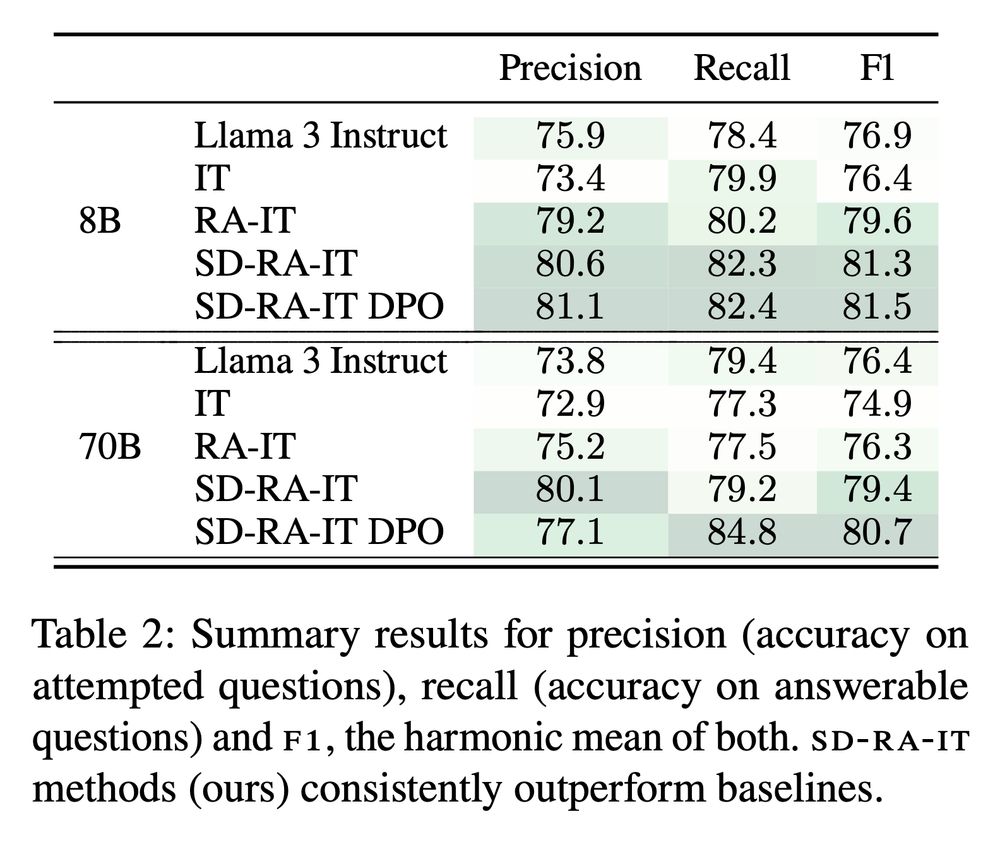
5/ Training on self-demos, our model learns to better leverage the context to answer questions, and to refuse questions that it is likely to answer incorrectly. This results in consistent, large improvements across several knowledge-intensive QA tasks.
25.02.2025 21:55 — 👍 0 🔁 0 💬 1 📌 0
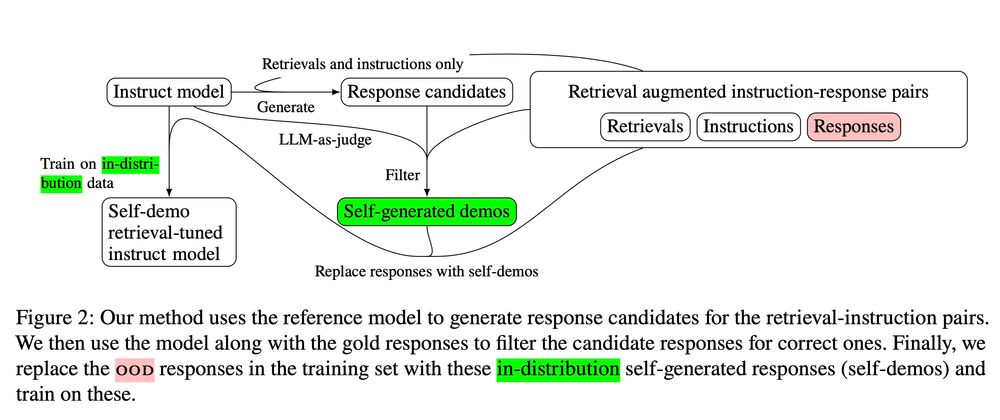
4/ To obtain self-demos we generate candidate responses with an LLM, then use the same LLM to compare these responses to the gold one, choosing the one that best matches (or refuses to answer). Thus we retain the gold supervision from the original responses while aligning the training data.
25.02.2025 21:55 — 👍 1 🔁 1 💬 1 📌 0
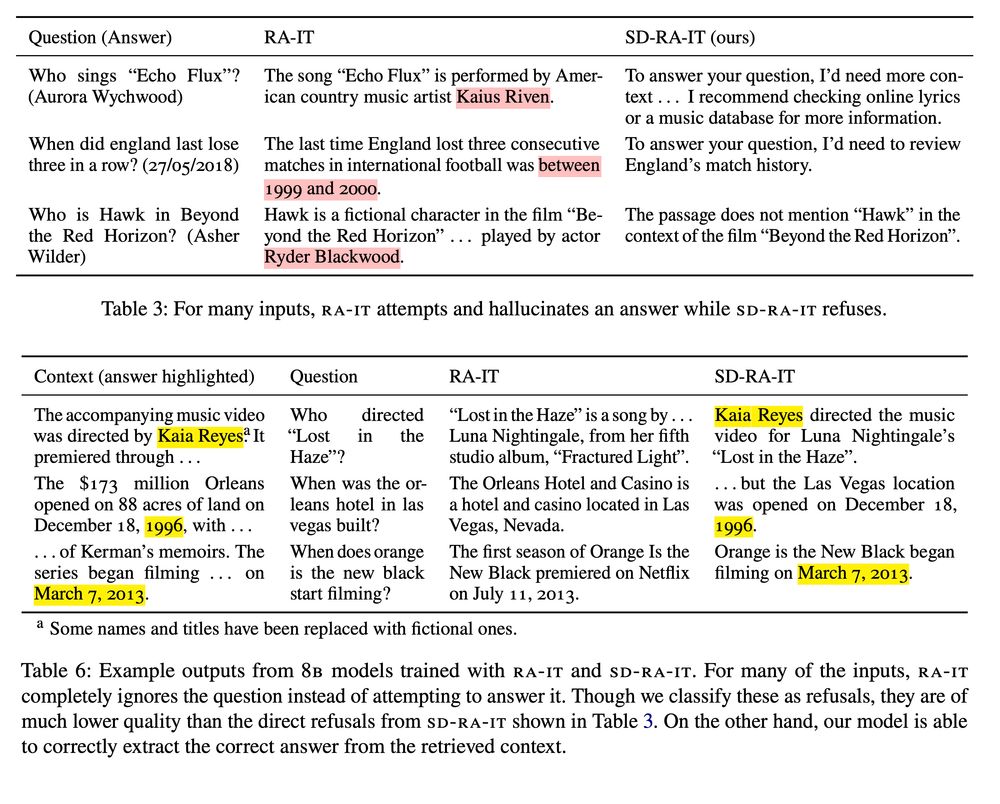
3/ OOD responses encourage the model to answer questions it does not know the answer to, and since retrievals are added post-hoc, the responses tend ignore or even contradict the retrieved context. Instead of training on these low-quality responses, we use the LLM to generate "self-demos".
25.02.2025 21:55 — 👍 0 🔁 0 💬 1 📌 0
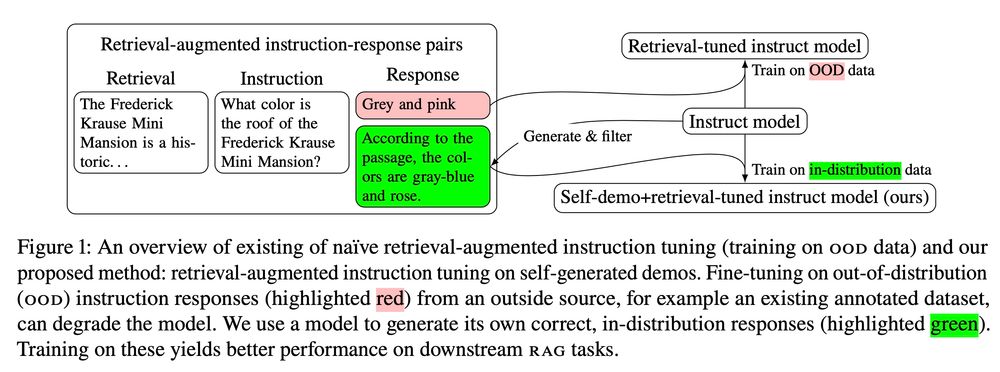
2/ A popular recipe for adapting LLMs for RAG involves adding retrievals post-hoc to an existing instruction-tuning dataset. The hope is that the LLM learns to leverage the added context to respond to instructions. Unfortunately, the gold responses in these datasets tend to be OOD for the model.
25.02.2025 21:55 — 👍 0 🔁 0 💬 1 📌 0

🧵 Adapting your LLM for new tasks is dangerous! A bad training set degrades models by encouraging hallucinations and other misbehavior. Our paper remedies this for RAG training by replacing gold responses with self-generated demonstrations. Check it out here: https://arxiv.org/abs/2502.10
25.02.2025 21:55 — 👍 18 🔁 1 💬 2 📌 1

The usc style guide list of formats for “cardinal” (see main post for list)
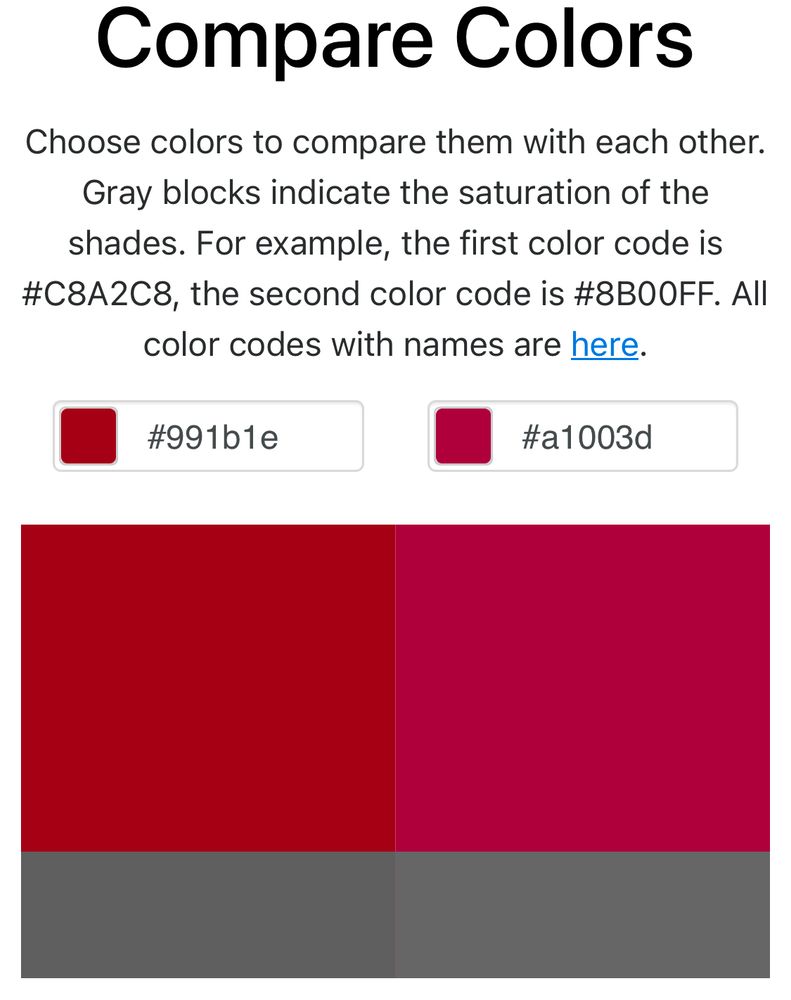
The rgb and CMYK colors side by side. The CMYK is considerably pinker
Putting together an unofficial usc Beamer template, I noticed that the USC style guide lists 4 formats for “cardinal red” but each of them is different:
PMS 201 C is #9D2235
CMYK: 7, 100, 65, 32 is #A1003D
RGB: 135, 27, 30 is #991B1E
HEX: #990000
Is this normal? The CMYK is especially egregious.
12.12.2024 17:16 — 👍 0 🔁 0 💬 0 📌 0
If you are registered for NeurIPS it should be available already online.
12.12.2024 17:05 — 👍 0 🔁 0 💬 1 📌 0
NeurIPS should make them available online after one month :)
11.12.2024 06:57 — 👍 0 🔁 0 💬 0 📌 0
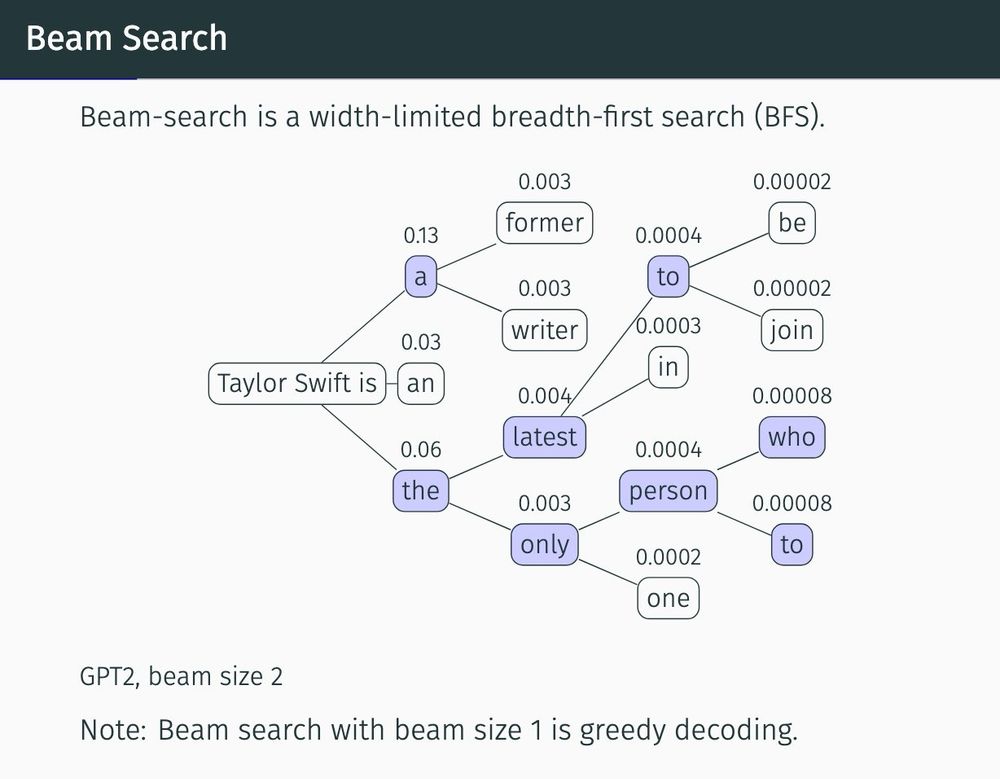
A diagram demonstrating text generation with beam search. One of the paths reads “Taylor Swift is the only person to…”
In Vancouver for NeurIPS but don't have Taylor Swift tickets?
You can still spend the day going through our tutorial reading list:
cmu-l3.github.io/neurips2024-...
Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS
09.12.2024 01:43 — 👍 29 🔁 2 💬 0 📌 0
Shout out to our organizers @wellecks.bsky.social @abertsch.bsky.social @hails.computer @uralik.bsky.social @gneubig.bsky.social @abertsch.bsky.social Alex Xie, Konstantin Golobokov, and Zaid Harchaoui
06.12.2024 17:26 — 👍 1 🔁 0 💬 1 📌 0

Panelist photos: Rishabh Agarwal (Google, McGill), Noam Brown (OpenAl), Beidi Chen (CMU), Nouha Dziri (AI2), Jakob Foerster (Oxford, Meta)
Curious about all this inference-time scaling hype? Attend our NeurIPS tutorial: Beyond Decoding: Meta-Generation Algorithms for LLMs (Tue. 1:30)! We have a top-notch panelist lineup.
Our website: cmu-l3.github.io/neurips2024-...
06.12.2024 17:18 — 👍 27 🔁 3 💬 1 📌 0
😍 I went cycling there last year, what an amazing place
02.12.2024 06:20 — 👍 1 🔁 0 💬 1 📌 0
The cover 😍
29.11.2024 18:07 — 👍 1 🔁 0 💬 0 📌 0
Check your data mixture. @hamishivi.bsky.social is probably secretly up-weighting Latin in Dolma
28.11.2024 16:42 — 👍 6 🔁 1 💬 1 📌 0
What's that? A fully open LM competitive with Gemma and Qwen*?
Happy to have helped a bit with this release (Tulu 3 recipe used here)! OLMo-2 13B actually beats Tulu 3 8B on these evals, making it a SOTA fully open LM!!!
(*on the benchmarks we looked at, see tweet for more)
26.11.2024 20:54 — 👍 10 🔁 1 💬 1 📌 0
These folks have had a huge impact on my research
26.11.2024 18:39 — 👍 3 🔁 0 💬 0 📌 0

#socalnlp is the biggest it's ever been in 2024! We have 3 poster sessions up from 2! How many years until it's a two-day event?? 🤯
22.11.2024 21:50 — 👍 26 🔁 3 💬 2 📌 0

LLM360 logo. A long-necked llama in the shape of an O.
Screenshot from Oquonie with a long-necked character.
This is niche but the LLM360 logo always reminds me of the 2014 iOS game Oquonie
22.11.2024 19:23 — 👍 3 🔁 0 💬 0 📌 0
And by linear I mean logistic 🤦♂️
22.11.2024 08:02 — 👍 3 🔁 0 💬 1 📌 0
Hottest new research challenge: find the lost LLM head!
22.11.2024 07:30 — 👍 9 🔁 0 💬 0 📌 0
Assistant Professor of Computational Linguistics @ Georgetown; formerly postdoc @ ETH Zurich; PhD @ Harvard Linguistics, affiliated with MIT Brain & Cog Sci. Language, Computers, Cognition.
Gaia Sky is a 3D Universe desktop and VR application to bring Gaia data to the masses, open source, libre.
The largest workshop on analysing and interpreting neural networks for NLP.
BlackboxNLP will be held at EMNLP 2025 in Suzhou, China
blackboxnlp.github.io
#nlproc phd. computational linguiost. disaster artist. computer wizard. bike commuter. opinion haver. under constr
Applied Mathematician
Macro data refinement scientist
https://kslote1.github.io
Everyone should care.
My opinions are my own
🎓 PhD student at the Max Planck Institute for Intelligent Systems
🔬 Safe and robust AI, algorithms and society
🔗 https://andrefcruz.github.io
📍 from 🇵🇹, researcher in 🇩🇪, currently living in Cambridge 🇺🇸
Asst Prof. @ UCSD | PI of LeM🍋N Lab | Former Postdoc at ETH Zürich, PhD @ NYU | computational linguistics, NLProc, CogSci, pragmatics | he/him 🏳️🌈
alexwarstadt.github.io
The world's leading venue for collaborative research in theoretical computer science. Follow us at http://YouTube.com/SimonsInstitute.
FAIR Sequence Modeling Toolkit 2
(jolly good) Fellow at the Kempner Institute @kempnerinstitute.bsky.social, incoming assistant professor at UBC Linguistics (and by courtesy CS, Sept 2025). PhD @stanfordnlp.bsky.social with the lovely @jurafsky.bsky.social
isabelpapad.com
Compose papers faster: Focus on your text and let Typst take care of layout and formatting.
Ph.D. Student @ ETH Zürich
Predoctoral researcher at Ai2
https://ljvmiranda921.github.io
PhD supervised by Tim Rocktäschel and Ed Grefenstette, part time at Cohere. Language and LLMs. Spent time at FAIR, Google, and NYU (with Brenden Lake). She/her.
I work at Sakana AI 🐟🐠🐡 → @sakanaai.bsky.social
https://sakana.ai/careers
MS at @uscnlp.bsky.social w/ @swabhs.bsky.social & gyauney.bsky.social | ML Intern at @paramountpictures.bsky.social | Interpretability, Alignment, Evaluation, Reasoning
https://shahzaib-s-warraich.github.io
PhD student in NLP at ETH Zurich.
anejsvete.github.io