Apply - Interfolio
{{$ctrl.$state.data.pageTitle}} - Apply - Interfolio
The University of Notre Dame is hiring 5 tenure or tenure-track professors in Neuroscience, including Computational Neuroscience, across 4 departments.
Come join me at ND! Feel free to reach out with any questions.
And please share!
apply.interfolio.com/173031
03.09.2025 17:26 — 👍 39 🔁 33 💬 0 📌 2

I am very happy to finally share something I have been working on and off for the past year:
"The Information Dynamics of Generative Diffusion"
This paper connects entropy production, divergence of vector fields and spontaneous symmetry breaking
link: arxiv.org/abs/2508.19897
02.09.2025 16:40 — 👍 21 🔁 3 💬 0 📌 0
Many when the number of steps in the puzzle is in the thousands and any error leads to a wrong solution
12.06.2025 15:46 — 👍 0 🔁 0 💬 0 📌 0
Have you ever asked your child to solve a simple puzzle in 60.000 easy steps?
11.06.2025 18:19 — 👍 0 🔁 0 💬 1 📌 0
Students using AI to write their reports is like me going to the gym and getting a robot to lift my weights
11.06.2025 17:09 — 👍 58 🔁 16 💬 2 📌 3

Generative decisions in diffusion models can be detected locally as symmetry breaking in the energy and globally as peaks in the conditional entropy rate.
The both corresponds to a (local or global) suppression of the quadratic potential (Hessian trace).
16.05.2025 09:12 — 👍 7 🔁 0 💬 0 📌 0
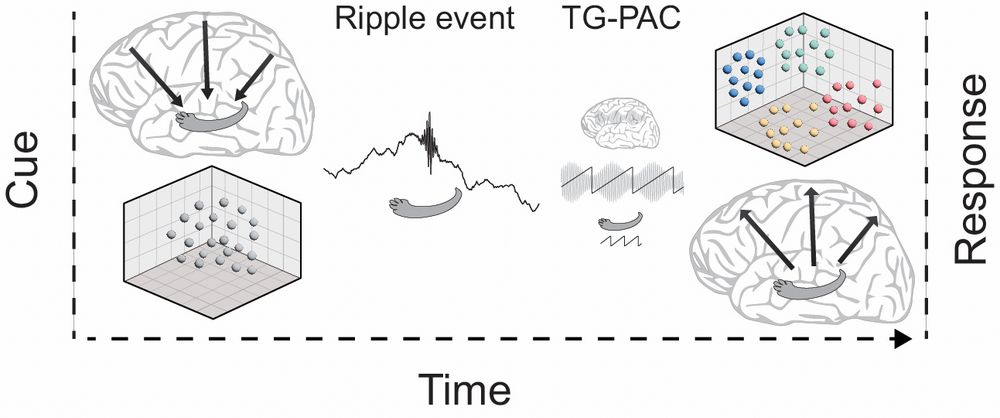
🧠✨How do we rebuild our memories? In our new study, we show that hippocampal ripples kickstart a coordinated expansion of cortical activity that helps reconstruct past experiences.
We recorded iEEG from patients during memory retrieval... and found something really cool 👇(thread)
29.04.2025 05:59 — 👍 167 🔁 63 💬 5 📌 5
Why? You can just mute out politics and owner's antics and it becomes perfecly fine again
03.05.2025 09:24 — 👍 3 🔁 0 💬 4 📌 0
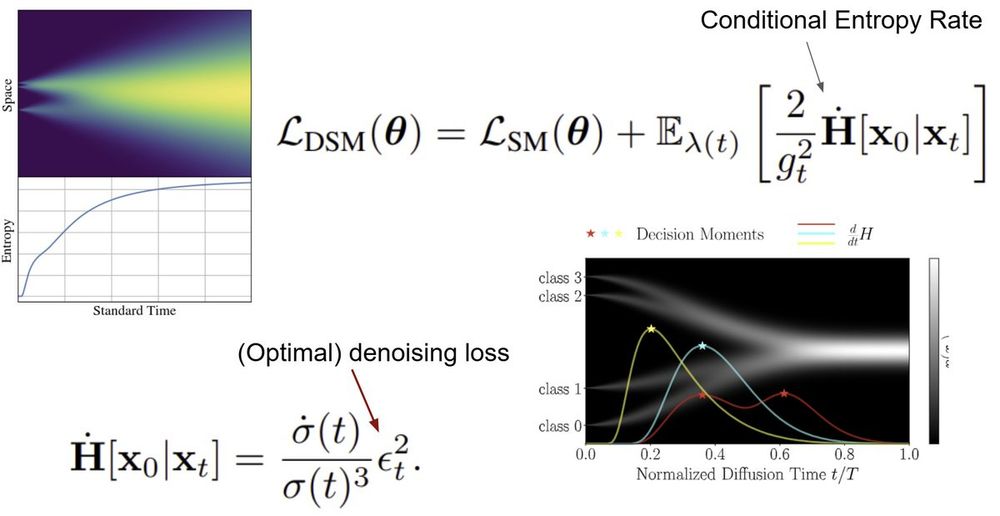
In continuous generative diffusion, the conditional entropy rate is the constant term that separates the score matching and the denoising score matching loss
This can be directly interpreted as the information transfer (bit rate) from the state x_t and the final generation x_0.
02.05.2025 13:32 — 👍 21 🔁 5 💬 0 📌 0
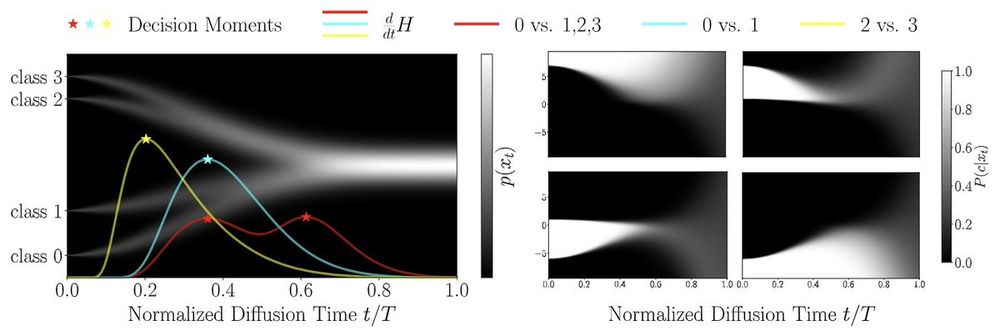
Decisions during generative diffusion are analogous to phase transitions in physics. They can be identified as peaks in the conditional entropy rate curve!
30.04.2025 13:37 — 👍 10 🔁 3 💬 0 📌 0
I'd put these on the NeuroAI vision board:
@tyrellturing.bsky.social's Deep learning framework
www.nature.com/articles/s41...
@tonyzador.bsky.social's Next-gen AI through neuroAI
www.nature.com/articles/s41...
@adriendoerig.bsky.social's Neuroconnectionist framework
www.nature.com/articles/s41...
28.04.2025 23:15 — 👍 34 🔁 10 💬 2 📌 1
Very excited that our work (together with my PhD student @gbarto.bsky.social and our collaborator Dmitry Vetrov) was recognized with a Best Paper Award at #AABI2025!
#ML #SDE #Diffusion #GenAI 🤖🧠
30.04.2025 00:02 — 👍 19 🔁 2 💬 1 📌 0
Indeed. We are currently doing a lot of work on guidance, so we will likely try to use entropic time there as well soon
29.04.2025 15:03 — 👍 2 🔁 0 💬 1 📌 0
The largest we have tried so far is EDM2 XL on 512 ImageNet. It works very well there!
We did not try with guidance so far
29.04.2025 14:55 — 👍 2 🔁 0 💬 1 📌 0
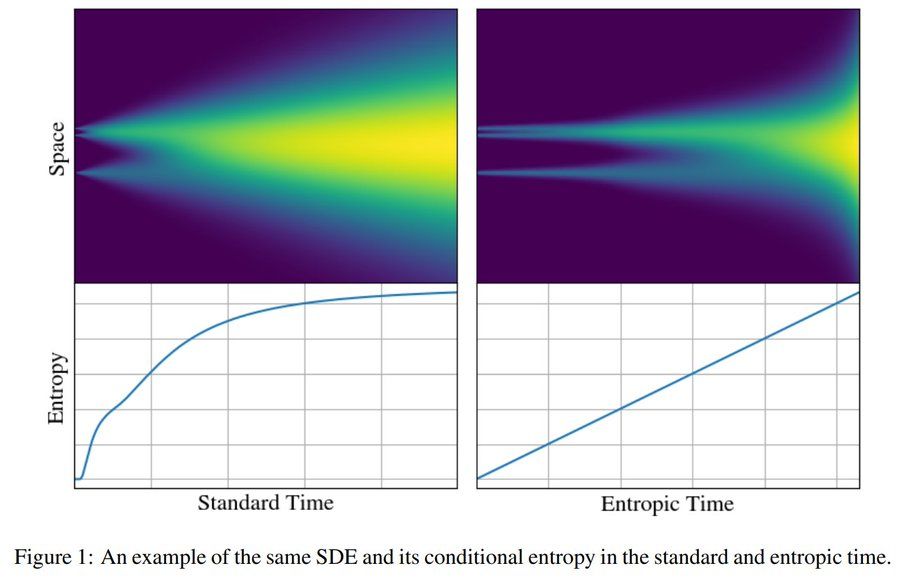
I am very happy to share our latest work on the information theory of generative diffusion:
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
29.04.2025 13:17 — 👍 25 🔁 5 💬 2 📌 0
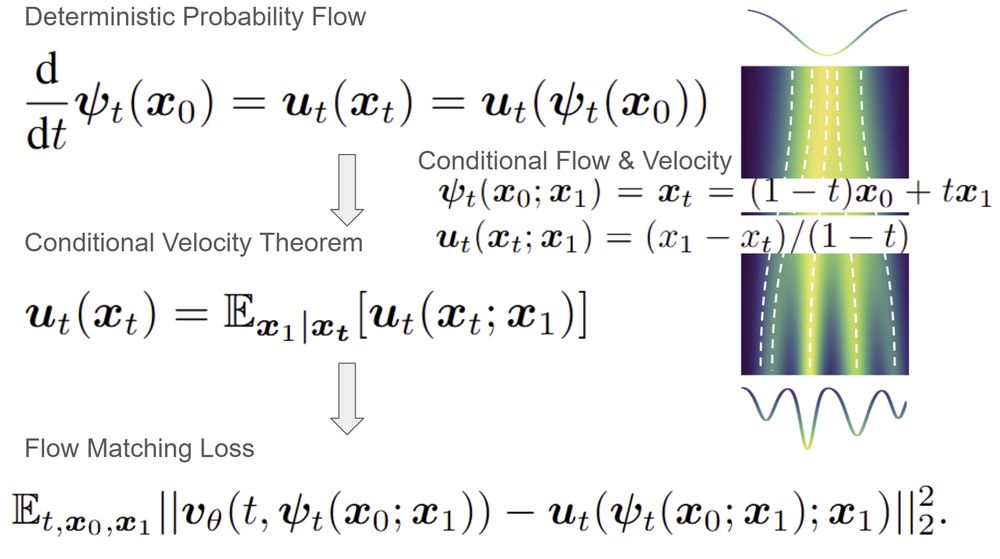
Flow Matching in a nutshell.
27.11.2024 14:07 — 👍 52 🔁 7 💬 1 📌 1
I will be at #NeurIPS2024 in Vancouver. I’m looking for post-docs, and if you want to talk about post-doc opportunities, get in touch. 🤗
Here’s my current team at Aalto University: users.aalto.fi/~asolin/group/
08.12.2024 10:56 — 👍 15 🔁 5 💬 0 📌 0
NeurIPS Poster Rule Extrapolation in Language Modeling: A Study of Compositional Generalization on OOD PromptsNeurIPS 2024
Can language models transcend the limitations of training data?
We train LMs on a formal grammar, then prompt them OUTSIDE of this grammar. We find that LMs often extrapolate logical rules and apply them OOD, too. Proof of a useful inductive bias.
Check it out at NeurIPS:
nips.cc/virtual/2024...
06.12.2024 13:31 — 👍 113 🔁 8 💬 7 📌 1

Photograph of Johannes Margraph and Günter Klambauer introducing the ELLIS ML4Molecules Workshop 2024 in Berlin at the Fritz-Haber Institute in Dahlem.
Excited to speak at the ELLIS ML4Molecules Workshop 2024 in Berlin!
moleculediscovery.github.io/workshop2024/
06.12.2024 08:08 — 👍 46 🔁 4 💬 3 📌 0
Can we please stop sharing posts that legitimate murder? Please.
06.12.2024 11:14 — 👍 1 🔁 0 💬 0 📌 0
Our team at Google DeepMind is hiring Student Researchers for 2025!
🧑🔬 Interested in understanding reasoning capabilities of neural networks from first principles?
🧑🎓 Currently studying for a BS/MS/PhD?
🧑💻 Have solid engineering and research skills?
🌟 We want to hear from you! Details in thread.
05.12.2024 23:08 — 👍 59 🔁 5 💬 2 📌 0
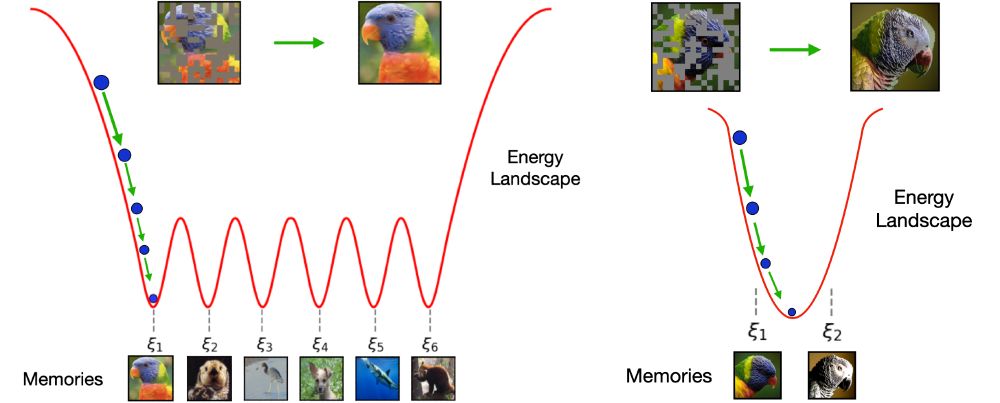
On the left figure, it showcases the behavior of Hopfield models. Given a query (the initial point of energy descent), a Hopfield model will retrieve the closest memory (local minimum) to that query such that it minimizes the energy function. A perfect Hopfield model is able to store patterns in distinct minima (or buckets). In contrast, the right figure illustrates a bad Associative Memory system, where stored patterns share a distinctive bucket. This enables the creation of spurious patterns, which appear like mixture of stored patterns. Spurious patterns will have lower energy than the memories due to this overlapping.
Diffusion models create beautiful novel images, but they can also memorize samples from the training set. How does this blending of features allow creating novel patterns? Our new work in Sci4DL workshop #neurips2024 shows that diffusion models behave like Dense Associative Memory networks.
05.12.2024 17:29 — 👍 39 🔁 5 💬 1 📌 1
The naivete of these takes is always amusing
They could be equally applied to human beings, and they would work as well
04.12.2024 14:12 — 👍 1 🔁 0 💬 0 📌 0
There are indeed cases in which obtaining an SDE equivalence isn't straightforward
04.12.2024 11:10 — 👍 1 🔁 0 💬 0 📌 0
I have always been saying that diffusion = flow matching.
Is it supposed to be some sort of news now??
04.12.2024 10:36 — 👍 4 🔁 0 💬 1 📌 0
However, flow matching theory doesn't provide much guidance on how to do stochastic sampling
It relies on the extra structure of diffusion
03.12.2024 06:33 — 👍 1 🔁 0 💬 1 📌 0
Disagree, religious literacy is important
03.12.2024 06:29 — 👍 0 🔁 0 💬 0 📌 0
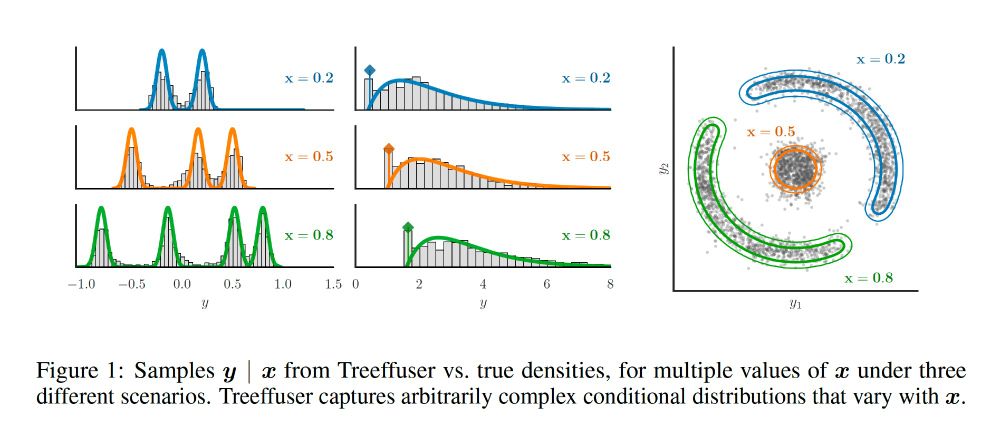
Samples y | x from Treeffuser vs. true densities, for multiple values of x under three different scenarios. Treeffuser captures arbitrarily complex conditional distributions that vary with x.
I am very excited to share our new Neurips 2024 paper + package, Treeffuser! 🌳 We combine gradient-boosted trees with diffusion models for fast, flexible probabilistic predictions and well-calibrated uncertainty.
paper: arxiv.org/abs/2406.07658
repo: github.com/blei-lab/tre...
🧵(1/8)
02.12.2024 21:48 — 👍 154 🔁 23 💬 4 📌 4
Prof (CS @Stanford), Co-Director @StanfordHAI, Cofounder/CEO @theworldlabs, CoFounder @ai4allorg #AI #computervision #robotics #AI-healthcare
Meet new people
ML Engineer at NVIDIA. Previously: Stealth GPU startup; Stability AI; AMD; Autodesk; CEO of 2 startups (3D + AI). Toronto, Canada
Blog: https://sander.ai/
🐦: https://x.com/sedielem
Research Scientist at Google DeepMind (WaveNet, Imagen 3, Veo, ...). I tweet about deep learning (research + software), music, generative models (personal account).
PhD Student at @compvis.bsky.social & @ellis.eu working on generative computer vision.
Interested in extracting world understanding from models and more controlled generation. 🌐 https://stefan-baumann.eu/
I am a physicist working on neural networks (artificial and biological). Find me on dmitrykrotov.com.
PhD Student at RPI. Interested in Hopfield or Associative Memory models and Energy-based models.
Machine Learning PhD Student
@ Blei Lab & Columbia University.
Working on probabilistic ML | uncertainty quantification | LLM interpretability.
Excited about everything ML, AI and engineering!
NeuroAI, vision, open science. NeuroAI researcher at Amaranth Foundation. Previously engineer @ Google, Meta, Mila. Updates from http://neuroai.science
Senior ML Scientist I at BigHat Biosciences.
Previously: AstraZeneca, Secondmind, PhD student & Gates Cambridge Scholar at CBL in Cambridge.
Views are my own.
Professor of Statistics, Bayesian, computational systems biologist and functional programmer, https://darrenjw.github.io/
Statistician. Bayesian. Professor, Department of Biostatistics, University of California, Los Angeles. Views are my own. He/Him.
https://linktr.ee/micheleguindani
#CS Associate Prof York University, #ComputerVision Scientist Samsung #AI, VectorInst Faculty Affiliate, TPAMI AE, ELLIS4Europe Member, #CVPR2026 #ECCV2026 Publicity Chair
📍Toronto 🇨🇦 🔗 csprofkgd.github.io
🗓️ Joined Nov 2024
Assistant Professor @ Politecnico di Torino, Istituto Italiano di Tecnologia, ELLIS
Prev. ML Genoa Center & University of Genoa
ML&Robotics
🐘 http://sigmoid.social/@raf_camo
🔗 www.linkedin.com/in/raffaellocamoriano
I support a free & independent Ukraine
phd student working on bayesian methods in bioimage analysis; @fz-juelich.de, @hds_lee & @lmu.de; bsc+msc in comp sci @univie.ac.at; based in karlsruhe; ripaul.github.io
Research fellow @OxfordStats @OxCSML, spent time at FAIR and MSR
Former quant 📈 (@GoldmanSachs), former former gymnast 🤸♀️
My opinions are my own
🇧🇬-🇬🇧 sh/ssh
Assistant Prof in ML @ KTH 🇸🇪
WASP Fellow
ELLIS Member
Ex: Aalto Uni 🇫🇮, TU Graz 🇦🇹, originally 🇩🇪.
—
https://trappmartin.github.io/
—
Reliable ML | UQ | Bayesian DL | tractability & PCs
Associate Professor (UHD) at the University of Amsterdam. Probabilistic methods, deep learning, and their applications in science in engineering.
Information theory, probability, statistics. Churchill Professor of Mathematics of Information @UofCambridge: dpmms.cam.ac.uk/person/ik355/ 🧮 #MathSky 🧪 #Science
[used to be @yiannis_entropy at the other place]
Research Fellow @HKU 🇭🇰 | Machine Learning | Generative Models | Bayesian Inference
🌐 https://zhidi-lin.github.io/




















