On N-dimensional Rotary Positional Embeddings
An exploration of N-dimensional rotary positional embeddings (RoPE) for vision transformers.
Great blog post on rotary position embeddings (RoPE) in more than one dimension, with interactive visualisations, a bunch of experimental results, and code!
28.07.2025 14:51 —
👍 18
🔁 2
💬 0
📌 0
... also very honoured and grateful to see my blog linked in the video description! 🥹🙏🙇
26.07.2025 21:59 —
👍 9
🔁 0
💬 0
📌 0
I blog and give talks to help build people's intuition for diffusion models. YouTubers like @3blue1brown.com and Welch Labs have been a huge inspiration: their ability to make complex ideas in maths and physics approachable is unmatched. Really great to see them tackle this topic!
26.07.2025 21:59 —
👍 31
🔁 0
💬 1
📌 0
Everyone is welcome!
15.07.2025 21:39 —
👍 3
🔁 0
💬 0
📌 0

Hello #ICML2025👋, anyone up for a diffusion circle? We'll just sit down somewhere and talk shop.
🕒Join us at 3PM on Thursday July 17. We'll meet here (see photo, near the west building's west entrance), and venture out from there to find a good spot to sit. Tell your friends!
15.07.2025 21:33 —
👍 14
🔁 1
💬 0
📌 1

Diffusion models have analytical solutions, but they involve sums over the entire training set, and they don't generalise at all. They are mainly useful to help us understand how practical diffusion models generalise.
Nice blog + code by Raymond Fan: rfangit.github.io/blog/2025/op...
05.07.2025 16:01 —
👍 34
🔁 3
💬 2
📌 1
Note also that getting this number slightly wrong isn't that big a deal. Even if you make it 100k instead of 10k, it's not going to change the granularity of the high frequencies that much because of the logarithmic frequency spacing.
24.06.2025 23:39 —
👍 0
🔁 0
💬 1
📌 0
The frequencies are log-spaced, so historically, 10k was plenty to ensure that all positions can be uniquely distinguished. Nowadays of course sequences can be quite a bit longer.
24.06.2025 23:39 —
👍 1
🔁 0
💬 1
📌 0
YouTube video by Bain Capital Ventures
History of Diffusion - Sander Dieleman
Here's the third and final part of Slater Stich's "History of diffusion" interview series!
The other two interviewees' research played a pivotal role in the rise of diffusion models, whereas I just like to yap about them 😬 this was a wonderful opportunity to do exactly that!
14.05.2025 16:11 —
👍 19
🔁 7
💬 0
📌 0
[“Machine Learning for Audio Workshop”]
[“Discover the harmony of AI and sound.”]
The ML for audio 🗣️🎵🔊 workshop is back at ICML 2025 in Vancouver! It will take place on Saturday, July 19. Featuring invited talks from Dan Ellis, Albert Gu, James Betker, Laura Laurenti and Pratyusha Sharma.
Submission deadline: May 23 (Friday next week)
mlforaudioworkshop.github.io
14.05.2025 12:16 —
👍 12
🔁 1
💬 0
📌 0

I am very happy to share our latest work on the information theory of generative diffusion:
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
29.04.2025 13:17 —
👍 25
🔁 5
💬 2
📌 0
One weird trick for better diffusion models: concatenate some DINOv2 features to your latent channels!
Combining latents with PCA components extracted from DINOv2 features yields faster training and better samples. Also enables a new guidance strategy. Simple and effective!
25.04.2025 13:03 —
👍 28
🔁 4
💬 0
📌 0
YouTube video by Bain Capital Ventures
History of Diffusion - Yang Song
Amazing interview with Yang Song, one of the key researchers we have to thank for diffusion models.
The most important lesson: be fearless! The community's view on score matching was quite pessimistic at the time, he went against the grain and made it work at scale!
www.youtube.com/watch?v=ud6z...
14.04.2025 16:47 —
👍 25
🔁 4
💬 0
📌 0
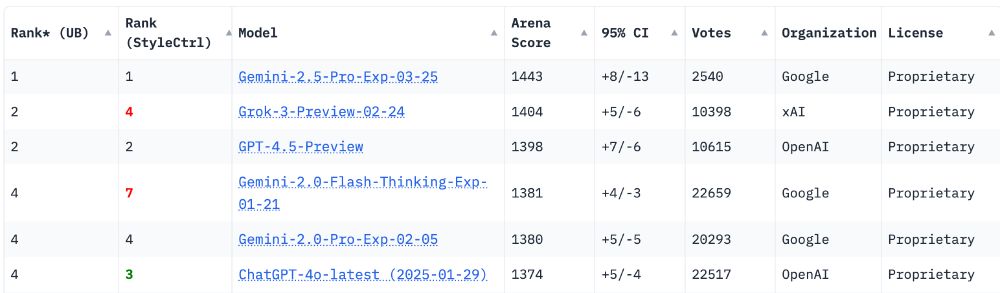

🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
25.03.2025 17:25 —
👍 215
🔁 65
💬 34
📌 11

Research Scientist, Generative Media
London, UK
We are hiring on the Generative Media team in London: boards.greenhouse.io/deepmind/job...
We work on Imagen, Veo, Lyria and all that good stuff. Come work with us! If you're interested, apply before Feb 28.
21.02.2025 19:00 —
👍 35
🔁 12
💬 4
📌 0
YouTube video by Bain Capital Ventures
History of Diffusion - Jascha Sohl-Dickstein
Great interview with @jascha.sohldickstein.com about diffusion models! This is the first in a series: similar interviews with Yang Song and yours truly will follow soon.
(One of these is not like the others -- both of them basically invented the field, and I occasionally write a blog post 🥲)
10.02.2025 22:30 —
👍 43
🔁 11
💬 0
📌 0

Cosmogenesis, by grumusic
8 track album
Yes! Also listen to this and contemplate the universe: grumusic.bandcamp.com/album/cosmog...
28.01.2025 23:55 —
👍 3
🔁 0
💬 1
📌 0
NeurIPS 2024 Schedule
This is just a tiny fraction of what's available, check out the schedule for more: neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 5
🔁 0
💬 0
📌 0
NeurIPS Multimodal Iterative RefinementNeurIPS 2024
10. Last but not least (😎), here's my own workshop talk about multimodal iterative refinement: the methodological tension between language and perceptual modalities, autoregression and diffusion, and how to bring these together 🍸 neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 6
🔁 0
💬 1
📌 0
NeurIPS Colin RaffleNeurIPS 2024
9. A great overview of various strategies for merging multiple models together by Colin Raffel 🪿 neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 3
🔁 0
💬 1
📌 0
NeurIPS Invited Talk 4 (Speker: Ishan Misra)NeurIPS 2024
8. Ishan Misra gives a nice overview of Meta's Movie Gen model 📽️ (I have some questions about the diffusion vs. flow matching comparison though😁) neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 2
🔁 0
💬 1
📌 0
NeurIPS Tom Goldstein: Can transformers solve harder problems than they were trained on? Scaling up test-time computation via recurrenceNeurIPS 2024
7. More on test-time scaling from @tomgoldstein.bsky.social, using a different approach based on recurrence 🐚 neurips.cc/virtual/2024... (some interesting comments on the link with diffusion models in the questions at the end!)
22.01.2025 21:06 —
👍 4
🔁 0
💬 2
📌 0
NeurIPS Invited Speaker: Noam Brown, OpenAINeurIPS 2024
6. @polynoamial.bsky.social talks about scaling compute at inference time, and the trade-offs involved -- in language models, but also in other settings 🧮 neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 4
🔁 0
💬 1
📌 0
NeurIPS Neel Nanda: Sparse Autoencoders - Assessing the evidenceNeurIPS 2024
5. Sparse autoencoders were in vogue well over a decade ago, back when I was doing my PhD. They've recently been revived in the context of mechanistic interpretability of LLMs 🔍 @neelnanda.bsky.social gives a nice overview: neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 6
🔁 0
💬 1
📌 0
NeurIPS Surya Ganguli: An analytic theory of creativity in convolutional diffusion modelsNeurIPS 2024
4. Insights from @suryaganguli.bsky.social on creativity, generalisation and overfitting in diffusion models 🎨 neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 4
🔁 0
💬 1
📌 0
NeurIPS Geometry of the Distribution of Natural ImagesNeurIPS 2024
3. @eerosim.bsky.social provides an in-depth look at the geometry of the distribution of natural images 🖼️ Extremely relevant to anyone trying to understand what diffusion models are really doing. neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 8
🔁 0
💬 1
📌 0
NeurIPS Alexis ConneauNeurIPS 2024
2. A great talk from Alexis Conneau demonstrating the various challenges involved in giving LLMs a voice: neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 3
🔁 0
💬 1
📌 0
NeurIPS Keynote: LLM Posteriors over Functions as a New Output ModalityNeurIPS 2024
1. @davidduvenaud.bsky.social gave an inspiring talk about using language models to learn to represent functions -- the kind of thing people like to use e.g. Gaussian processes for 📈 neurips.cc/virtual/2024...
22.01.2025 21:06 —
👍 5
🔁 0
💬 1
📌 0
📢PSA: #NeurIPS2024 recordings are now publicly available!
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
22.01.2025 21:06 —
👍 128
🔁 33
💬 1
📌 1




