Keynote at #COLM2025: Nicholas Carlini from Anthropic
"Are language models worth it?"
Explains that the prior decade of his work on adversarial images, while it taught us a lot, isn't very applied; it's unlikely anyone is actually altering images of cats in scary ways.
09.10.2025 13:12 — 👍 78 🔁 22 💬 2 📌 2
📢 New #COLM2025 paper 📢
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
16.09.2025 17:16 — 👍 39 🔁 10 💬 3 📌 1
What are your favorite recent papers on using LMs for annotation (especially in a loop with human annotators), synthetic data for task-specific prediction, active learning, and similar?
Looking for practical methods for settings where human annotations are costly.
A few examples in thread ↴
23.07.2025 08:10 — 👍 76 🔁 23 💬 13 📌 3
I see this work as our answer to the "cultural alignment" and "cultural benchmarking" trends in NLP research. Instead of making decisions for people, we consider "culture" in a specific setting with specific people for a specific task, and we ask people directly about their cultural adaptations.
10.06.2025 07:48 — 👍 38 🔁 6 💬 1 📌 0

GitHub - chtmp223/Frankentext: Frankentext: Stitching random text fragments into long-form narratives
Frankentext: Stitching random text fragments into long-form narratives - chtmp223/Frankentext
We release code to facilitate future research on fine-grained detection of mixed-origin texts and human-AI cowriting.
Github: github.com/chtmp223/Fra...
Paper: arxiv.org/abs/2505.18128
Work done with @jennajrussell, @dzungvietpham, and @MohitIyyer!
03.06.2025 15:09 — 👍 2 🔁 0 💬 0 📌 0

Room for improvement:
🔧 Frankentexts struggle with smooth narrative transitions and grammar, as noted by human annotators.
🔩 Non-fiction versions are coherent and faithful but tend to be overly anecdotal and lack factual accuracy.
03.06.2025 15:09 — 👍 1 🔁 0 💬 1 📌 0

Takeaway 2: Our controllable generation process provides a sandbox for human-AI co-writing research, with adjustable proportion, length, and diversity of human excerpts.
👫 Models can follow copy constraints, which is a proxy for % of human writing in co-authored texts.
03.06.2025 15:09 — 👍 1 🔁 0 💬 1 📌 0

Takeaway 1: Frankentexts don’t fit into the "AI vs. human" binary.
📉 Binary detectors misclassify them as human-written
👨👩👧 Humans can detect AI involvement more often
🔍 Mixed-authorship tools (Pangram) help, but still catch only 59%
We need better tools for this gray zone.
03.06.2025 15:09 — 👍 1 🔁 0 💬 1 📌 0

Automatic evaluation on 100 Frankentexts using LLM judges, text detectors, and a ROUGE-L-based metric shows that:
💪 Gemini-2.5-Pro, Claude-3.5-Sonnet, and R1 can generate Frankentexts that are up to 90% relevant, 70% coherent, and 75% traceable to the original human writings.
03.06.2025 15:09 — 👍 2 🔁 0 💬 1 📌 0

Frankentext generation presents an instruction-following task that challenges the limits of controllable generation, requiring each model to:
1️⃣ Produce a draft by selecting & combining human-written passages.
2️⃣ Iteratively revise the draft while maintaining a copy ratio.
03.06.2025 15:09 — 👍 3 🔁 0 💬 1 📌 0

🤔 What if you gave an LLM thousands of random human-written paragraphs and told it to write something new -- while copying 90% of its output from those texts?
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
03.06.2025 15:09 — 👍 33 🔁 7 💬 1 📌 1
We find that LLMs (e.g. GPT-4o, LLaMA-3.1) consistently recall book content across languages, even for texts without official translation in pre-training data!
Great work led by undergrads at UMass NLP 🥳
30.05.2025 15:53 — 👍 2 🔁 0 💬 0 📌 0

A visualization of the generator-validator gap, where the LM likelihoods of for the generator and discriminator forms of questions are poorly correlated.

Aligning the validator and generator rankings can fix it!
One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
16.04.2025 18:03 — 👍 33 🔁 8 💬 2 📌 3
Racial and Ethnic Representation in Literature Taught in US High Schools | Published in Journal of Cultural Analytics
By Li Lucy, Camilla Griffiths & 7 more. We quantify the representation, or presence, of characters of color in English Language Arts instruction in the United States to better understand possible raci...
📚 Check out the newest JCA article by Li Lucy (@lucy3.bsky.social), Camilla Griffiths, Claire Ying, JJ Kim-Ebio, Sabrina Baur, Sarah Levine, Jennifer L. Eberhardt, David Bamman (@dbamman.bsky.social), and Dorottya Demszky. culturalanalytics.org/article/1316...
09.04.2025 13:06 — 👍 47 🔁 23 💬 1 📌 0

Learning to Reason for Long-Form Story Generation
Generating high-quality stories spanning thousands of tokens requires competency across a variety of skills, from tracking plot and character arcs to keeping a consistent and engaging style. Due to…
A very cool paper shows that you can use the RL loss to improve story generation by some clever setups on training on known texts (e.g. ground predictions versus a next chapter you know). RL starting to generalize already!
08.04.2025 14:13 — 👍 33 🔁 6 💬 0 📌 2
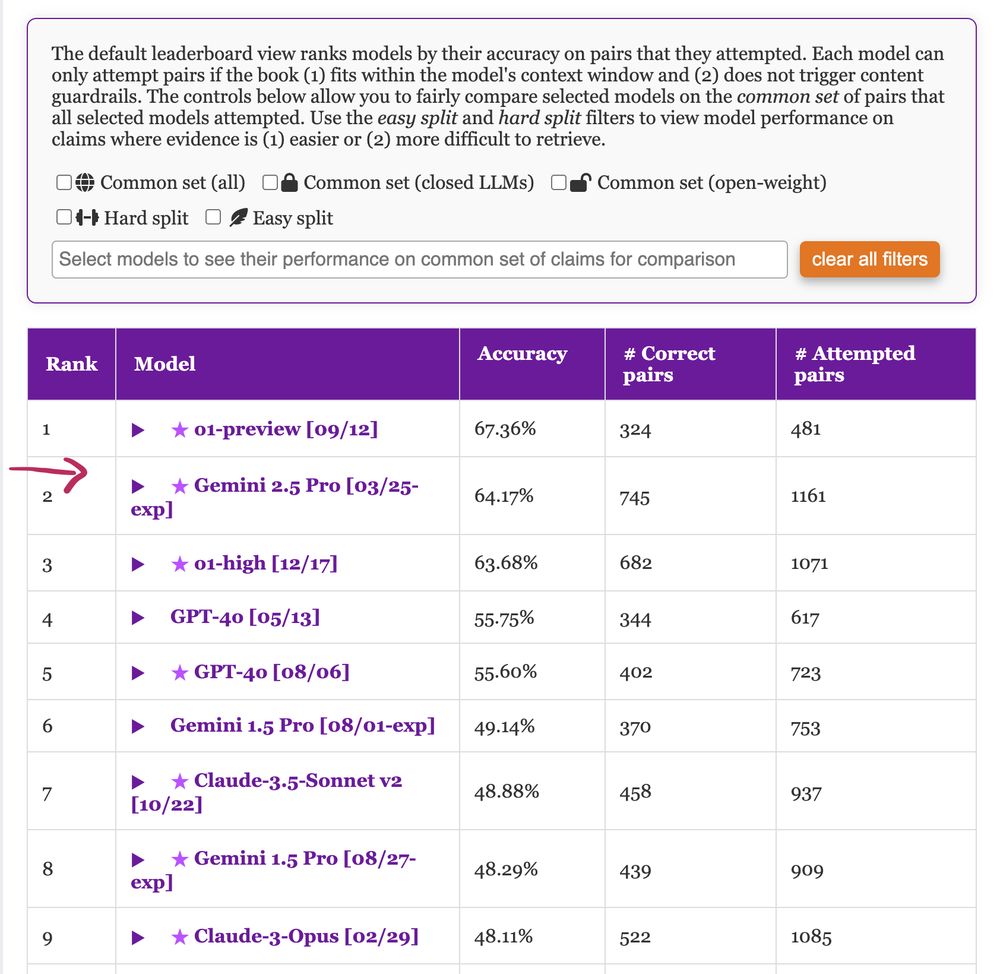
Leaderboard showing performance of language models on claim verification task over book-length input. o1-preview is the best model with 67.36% accuracy followed by Gemini 2.5 Pro with 64.17% accuracy.
We have updated #nocha, a leaderboard for reasoning over long-context narratives 📖, with some new models including #Gemini 2.5 Pro which shows massive improvements over the previous version! Congrats to #Gemini team 🪄 🧙 Check 🔗 novelchallenge.github.io for details :)
02.04.2025 04:30 — 👍 11 🔁 4 💬 0 📌 0
New paper from our team @GoogleDeepMind!
🚨 We've put LLMs to the test as writing co-pilots – how good are they really at helping us write? LLMs are increasingly used for open-ended tasks like writing assistance, but how do we assess their effectiveness? 🤔
arxiv.org/pdf/2503.19711
02.04.2025 09:51 — 👍 20 🔁 8 💬 1 📌 1
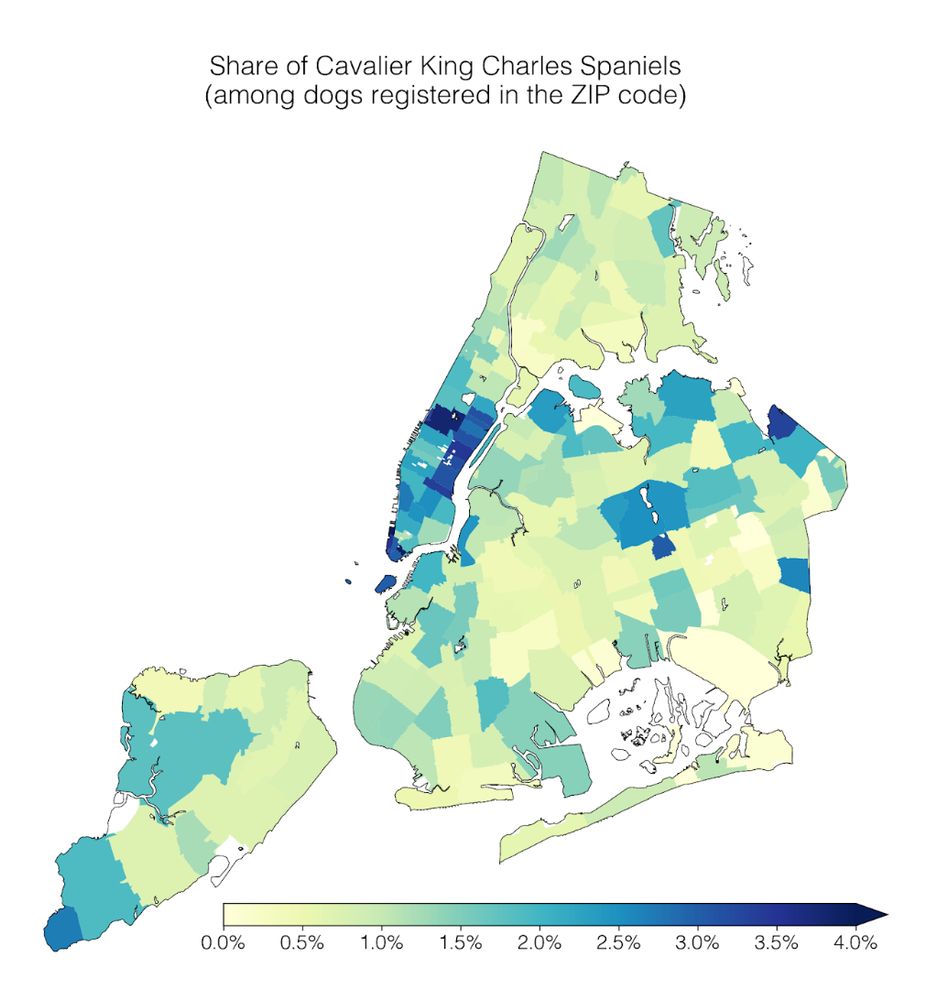
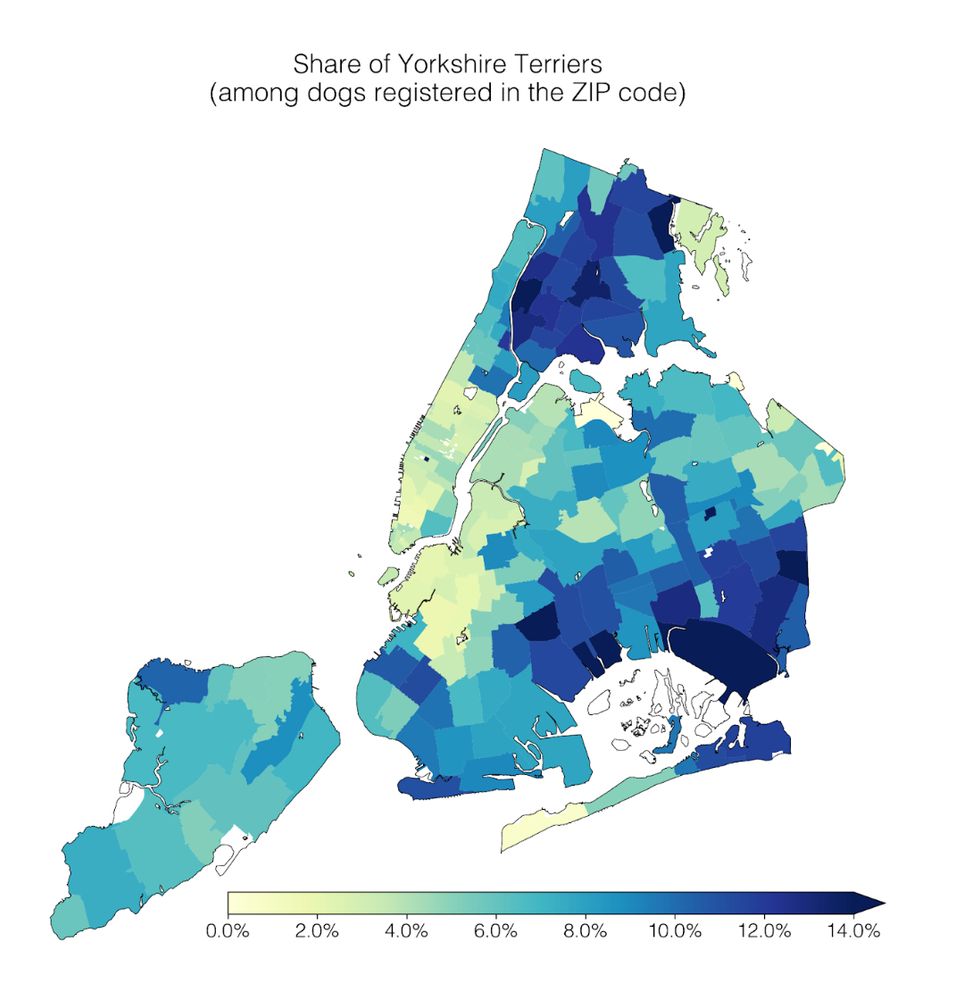
Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
02.04.2025 14:16 — 👍 55 🔁 14 💬 2 📌 13
ArXiv Paper Feed
The high effort solution is to use an LLM to make a browser extension which tracks your academic reading and logs every paper you interact with to github, which builds and publishes a webapp to expose the data.
Which, clearly only a crazy weirdo would do.
dmarx.github.io/papers-feed/
27.03.2025 03:18 — 👍 39 🔁 9 💬 3 📌 5
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
18.03.2025 15:17 — 👍 40 🔁 13 💬 1 📌 3
Ask OpenAI Operator for bus routes from your home in Vietnam to a university and it likely fails because it refuses to use Google Maps! Our new BEARCUBS 🐻 benchmark shows CU agents still struggle with seemingly straightforward multimodal questions.
12.03.2025 14:58 — 👍 1 🔁 0 💬 0 📌 0

Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
05.03.2025 17:06 — 👍 14 🔁 5 💬 1 📌 3

Screenshot of the first page of preprint, "Provocations from the Humanities for Generative AI Research," by Lauren Klein, Meredith Martin, Andre Brock, Maria Antoniak, Melanie Walsh, Jessica Marie Johnson, Lauren Tilton, and David Mimno
Excited to share our preprint "Provocations from the Humanities for Generative AI Research”
We're open to feedback—read & share thoughts!
@laurenfklein.bsky.social @mmvty.bsky.social @docdre.distributedblackness.net @mariaa.bsky.social @jmjafrx.bsky.social @nolauren.bsky.social @dmimno.bsky.social
28.02.2025 01:34 — 👍 143 🔁 48 💬 8 📌 3

🚨 New Position Paper 🚨
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
24.02.2025 21:03 — 👍 45 🔁 13 💬 2 📌 0

Areas for improvement:
🔩 Larger models (>=70B) may benefit from book-level reasoning—our chapter-level model outperforms the book-level version, indicating that smaller models might struggle with book-level reasoning.
🔩 Fine-tuned models struggle to verify False claims.
21.02.2025 16:25 — 👍 1 🔁 0 💬 1 📌 0

Our fine-tuned models produce more informative chain-of-thought reasoning compared to baseline models. Each chain of thoughts has:
📍 Source chapter of each event in the claim
🤝 Relationships between these events
📖 Explanation on how this supports/contradicts the claim.
21.02.2025 16:25 — 👍 0 🔁 0 💬 1 📌 0

🔧 We fine-tune Qwen2.5-7B-Instruct, LLaMA-3.1-8B-Instruct, and Prolong-512K-8B-Instruct on our dataset.
📈 The fine-tuned LLaMA model boosts test performance from 28% to 76% and set a new state-of-the-art for <10B on NoCha, a long-form claim verification benchmark!
21.02.2025 16:25 — 👍 0 🔁 0 💬 1 📌 0

💽 We use CLIPPER to create a dataset of 19K synthetic book claims paired with chain-of-thought explanations.
✅ Our claims suffer from fewer errors like misattributions, duplications, and invalid claims compared to naïve approaches.
21.02.2025 16:25 — 👍 0 🔁 0 💬 1 📌 0
Promoting authorship for the public good by supporting authors who write to be read. authorsalliance.org and authorsalliance.substack.com for updates.
An interdisciplinary digital humanities research and teaching centre at the University of Cambridge.
Visit our website: www.cdh.cam.ac.uk
Subscribe to our newsletter: https://bit.ly/NewsCDH
Unofficial bot by @vele.bsky.social w/ http://github.com/so-okada/bXiv https://arxiv.org/list/cs.CL/new
List https://bsky.app/profile/vele.bsky.social/lists/3lim7ccweqo2j
ModList https://bsky.app/profile/vele.bsky.social/lists/3lim3qnexsw2g
A peer-reviewed venue for literary and cultural datasets 📚 🎬 🎮 — with a focus on data from 1945 to the present. Always open-access.
Use our data or submit a new dataset! https://data.post45.org/
The free and flexible app for your private thoughts. For help and deeper discussions, join our community: http://obsidian.md/community
The 2025 Conference on Language Modeling will take place at the Palais des Congrès in Montreal, Canada from October 7-10, 2025
The Stanford Literary Lab is a research collective that applies computational criticism to the study of literature.
It is directed by Mark Algee-Hewitt and Associate Directors Nichole Nomura and Matt Warner.
https://litlab.stanford.edu/about
Rare Book & Manuscript Library at University of Illinois Urbana-Champaign | Main Library 346 | https://www.library.illinois.edu/rbx/
Follow us on Instagram (illinois_rbml) and Facebook (IllinoisRBML)!
An experiential research & pedagogy studio for the history & art of the book at UIUC. We are housed in the CU Community FabLab & sponsored by the iSchool and English Department. Directed by @ryancordell.org
Cultural Analytics is a platinum open-access journal dedicated to the computational study of culture.
Probabilistic ML, Learning Theory, Philosophy of Science,
Complex Systems, Nonlinear Dynamics, Disinformation Intervention
YIMBY
Research MLE, CoreWeave + EleutherAI
xStabilityai | xMSFT | xAMZN
What I'm reading: https://dmarx.github.io/papers-feed/
Researcher @Microsoft; PhD @Harvard; Incoming Assistant Professor @MIT (Fall 2026); Human-AI Interaction, Worker-Centric AI
zbucinca.github.io
Research Scientist at Ai2, PhD in NLP 🤖 UofA. Ex
GoogleDeepMind, MSFTResearch, MilaQuebec
https://nouhadziri.github.io/
NLP, ML & society, healthcare.
PhD student at Berkeley, previously CS at MIT.
https://rajivmovva.com/
Cs @UMass
NLP researcher
Currently working on LLM safety and factuality and hate speech moderation
Information and updates about RLC 2025 at the University of Alberta from Aug. 5th to 8th!
https://rl-conference.cc






















