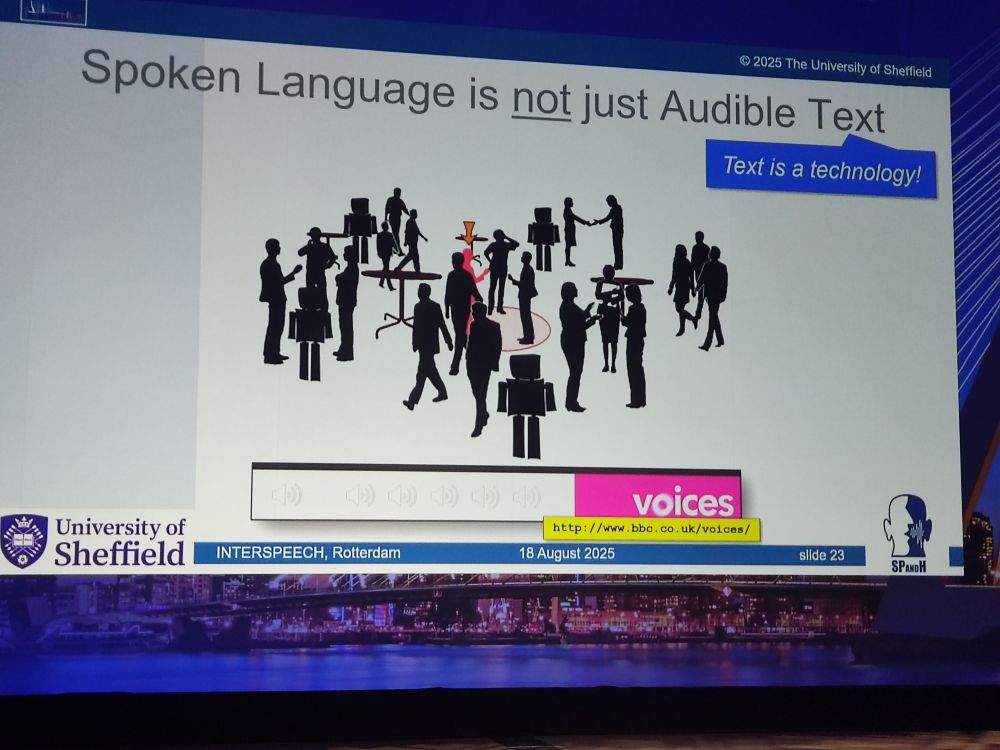
Roger Moore reminds Interspeech audience that speech is not audible text. Text is a technology.
18.08.2025 08:18 — 👍 14 🔁 1 💬 0 📌 0
@geiongallego.bsky.social
Roger Moore reminds Interspeech audience that speech is not audible text. Text is a technology.
18.08.2025 08:18 — 👍 14 🔁 1 💬 0 📌 0
Excited to share that this work was accepted to Interspeech 2025. See you in Rotterdam!
Preprint: arxiv.org/abs/2505.24691
By adding phoneme recognition as an intermediate step, we improve cross-lingual transfer, even for languages with no labeled speech. The method boosts low-resource performance, with only a slight drop in high-resource scenarios.
03.06.2025 20:53 — 👍 0 🔁 0 💬 1 📌 0In my first project at BSC, we worked on improving speech-to-text translation for low-resource languages. Our paper, "Speech-to-Text Translation with Phoneme-Augmented CoT", presents an LLM-based model that integrates phoneme recognition into the CoT approach.
03.06.2025 20:53 — 👍 0 🔁 0 💬 1 📌 0A quick (and slightly late) career update: I joined the Barcelona Supercomputing Center (BSC) in January 2025! I'm now in a full-time role, back to Speech Translation after a few years of internships and detours. 🧵
03.06.2025 20:53 — 👍 3 🔁 0 💬 1 📌 0
Wishing everyone a Happy New Year! Stay tuned for this work to be presented at #ICASSP2025.
arxiv.org/abs/2409.11003
This research was conducted during my internship at Dolby Labs. A special thanks to Roy Fejgin, Chunghsin Yeh, Xiaoyu Liu, and Gautam Bhattacharya for their mentorship and collaboration.
31.12.2024 19:48 — 👍 0 🔁 0 💬 1 📌 0With this approach, we demonstrate that single-stage NAR systems can perform competitively compared to more complex two-stage models, narrowing the gap in quality and intelligibility.
31.12.2024 19:48 — 👍 0 🔁 0 💬 1 📌 0Our system, NARSiS, integrates semantic and acoustic modeling into a unified, single-stage framework. Using Semantic Knowledge Distillation, we incorporate semantic guidance during training while keeping inference efficient.
31.12.2024 19:48 — 👍 0 🔁 0 💬 1 📌 0As we welcome 2025, we're excited to share that our paper, "Single-stage TTS with Masked Audio Token Modeling and Semantic Knowledge Distillation", has been accepted to #ICASSP2025!
This work advances single-stage Non-Autoregressive TTS based on audio token modeling.
🧵
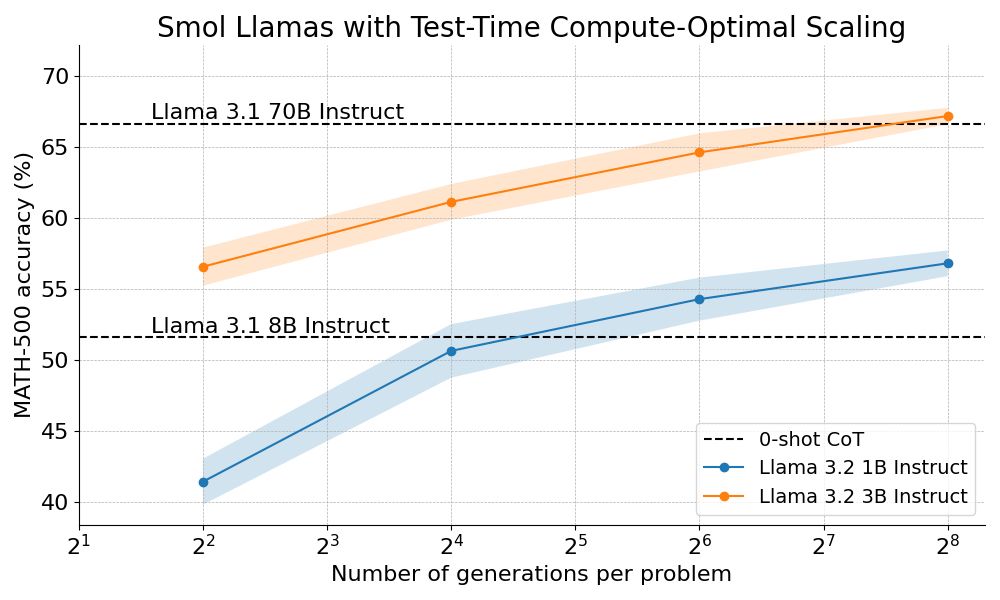
We outperform Llama 70B with Llama 3B on hard math by scaling test-time compute 🔥
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
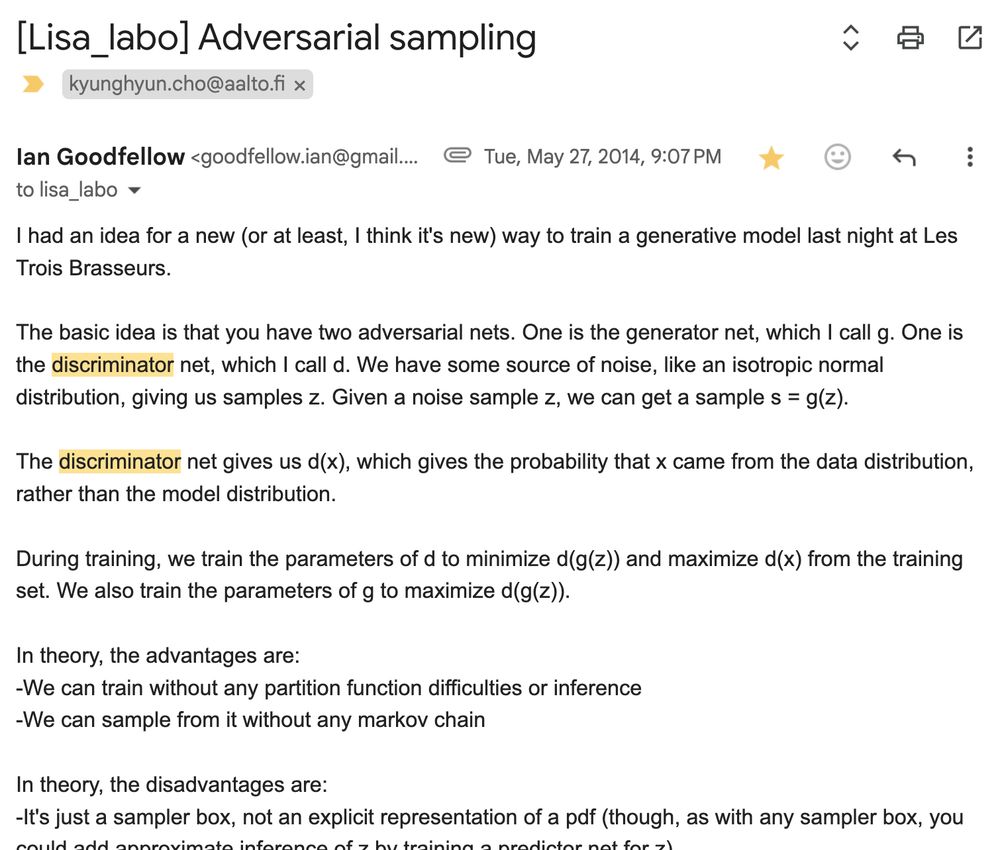


congratulations, @ian-goodfellow.bsky.social, for the test-of-time award at @neuripsconf.bsky.social!
this award reminds me of how GAN started with this one email ian sent to the Mila (then Lisa) lab mailing list in May 2014. super insightful and amazing execution!

Arxiv sharing reminder
pdf ❌
abs ✅



















