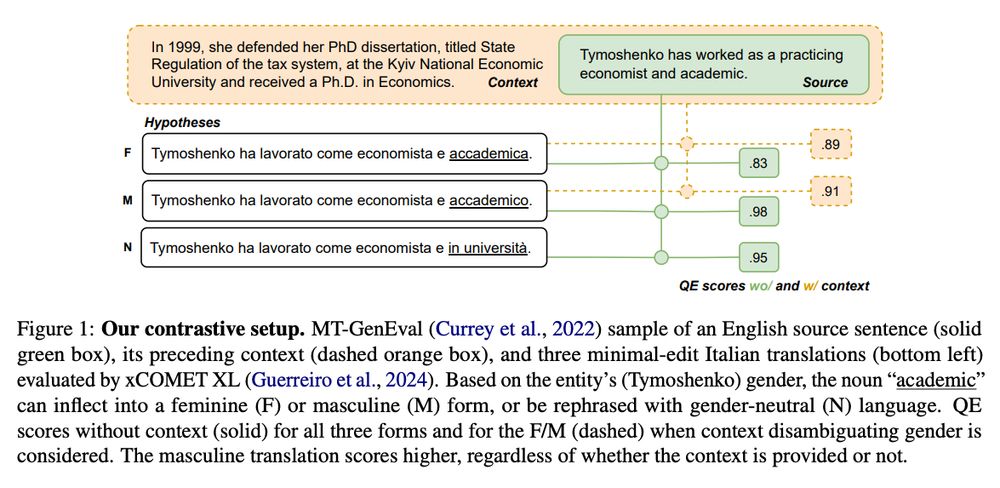
Figure 1 of the paper shows that the metrics score the masculine forms higher than the feminine or neutral ones.
As neural metrics are a pillar for #MT, being extensively used for evaluation but also improving translation, we'd want them to be fair.
🚨 Our #ACL2025 paper shows they consistently, unduly favor masculine-inflected translations, or gendered forms, over neutral ones.
arxiv.org/pdf/2410.10995
14.07.2025 14:00 — 👍 11 🔁 8 💬 1 📌 1

Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus...
New paper from
Manos Zaranis, @tozefarinhas.bsky.social
and other sardines!!🚀
Meet MF²: Movie Facts & Fibs: a new benchmark for long-movie understanding
This benchmark focuses on narrative understanding (key events, emotional arcs, causal chains) in long movies.
Paper: arxiv.org/abs/2506.06275
24.06.2025 15:51 — 👍 0 🔁 0 💬 0 📌 0
LxMLS 2025 - The 15th Lisbon Machine Learning Summer School
Applications for the 2025 Lisbon Machine Learning Summer School (LxMLS) are open, with @andre-t-martins.bsky.social as one of the organizers.
LxMLS is a great opportunity to learn from top speakers and to interact with other students. You can apply for a scholarship.
Apply here:
lxmls.it.pt/2025/
28.02.2025 15:35 — 👍 2 🔁 1 💬 0 📌 0
📣 New paper alert! We released a new safety benchmark for VLMs with a core focus on test cases that become unsafe by combining text and images.
TL;DR: many modern VLMs are unsafe across various types of queries and languages.
arxiv.org/abs/2501.10057
huggingface.co/datasets/fel...
22.01.2025 13:43 — 👍 14 🔁 1 💬 0 📌 0




















