
Photo of Cornelll University building surrounded by colorful trees
No better time to start learning about that #AI thing everyone's talking about...
📢 I'm recruiting PhD students in Computer Science or Information Science @cornellbowers.bsky.social!
If you're interested, apply to either department (yes, either program!) and list me as a potential advisor!
06.11.2025 16:19 — 👍 21 🔁 9 💬 1 📌 0

A circular flow diagram that compares current and proposed practices for LLM development using data from adopters and non-adopters. Three gray boxes represent current practices: “R&D,” “Chat Models,” and “Adopters’ Needs and Usage Data,” connected in a clockwise loop with black arrows. A blue box labeled “Non-adopters’ Needs and Usage Data” adds a proposed feedback path, shown with blue arrows, linking non-adopter data back to R&D and adopters’ data.
As of June 2025, 66% of Americans have never used ChatGPT.
Our new position paper, Attention to Non-Adopters, explores why this matters: AI research is being shaped around adopters—leaving non-adopters’ needs, and key LLM research opportunities, behind.
arxiv.org/abs/2510.15951
21.10.2025 17:12 — 👍 35 🔁 12 💬 2 📌 0
I'll be at COLM next week! Let me know if you want to chat! @colmweb.org
@neilrathi.bsky.social will be presenting our work on multilingual overconfidence in language models and the effects on human overreliance!
arxiv.org/pdf/2507.06306
03.10.2025 17:33 — 👍 7 🔁 1 💬 0 📌 0

Abstract and results summary
🚨 New preprint 🚨
Across 3 experiments (n = 3,285), we found that interacting with sycophantic (or overly agreeable) AI chatbots entrenched attitudes and led to inflated self-perceptions.
Yet, people preferred sycophantic chatbots and viewed them as unbiased!
osf.io/preprints/ps...
Thread 🧵
01.10.2025 15:16 — 👍 171 🔁 88 💬 5 📌 15
Was a blast working on this with @cinoolee.bsky.social @pranavkhadpe.bsky.social, Sunny Yu, Dyllan Han, and @jurafsky.bsky.social !!! So lucky to work with this wonderful interdisciplinary team!!💖✨
03.10.2025 22:58 — 👍 1 🔁 0 💬 0 📌 0
While our work focuses on interpersonal advice-seeking, concurrent work by @steverathje.bsky.social @jayvanbavel.bsky.social
et al. finds similar patterns for political topics, where sycophantic AI also led to more extreme attitudes when users discussed gun control, healthcare, immigration, etc.!
03.10.2025 22:57 — 👍 2 🔁 0 💬 1 📌 0
There is currently little incentive for developers to reduce sycophancy. Our work is a call to action: we need to learn from the social media era and actively consider long-term wellbeing in AI development and deployment. Read our preprint: arxiv.org/pdf/2510.01395
03.10.2025 22:57 — 👍 8 🔁 1 💬 1 📌 0

Rightness judgment is higher and repair likelihood is lower for sycophantic AI

Response quality, return likelihood, and trust are higher for sycophantic AI
Despite sycophantic AI’s reduction of prosocial intentions, people also preferred it and trusted it more. This reveals a tension: AI is rewarded for telling us what we want to hear (immediate user satisfaction), even when it may harm our relationships.
03.10.2025 22:57 — 👍 8 🔁 3 💬 1 📌 0

Description of Study 2 (hypothetical vignettes) and Study 3 (live interaction) where self-attributed wrongness and desire to initiate repair decrease, while response quality and trust increases.
Next, we tested the effects of sycophancy. We find that even a single interaction with sycophantic AI increased users’ conviction that they were right and reduced their willingness to apologize. This held both in controlled, hypothetical vignettes and live conversations about real conflicts.
03.10.2025 22:55 — 👍 8 🔁 3 💬 1 📌 2

Description of Study 1, where we characterize the prevalence of social sycophancy and find it to be highly prevalent across leading AI models
We focus on the prevalence and harms of one dimension of sycophancy: AI models endorsing users’ behaviors. Across 11 AI models, AI affirms users’ actions about 50% more than humans do, including when users describe harmful behaviors like deception or manipulation.
03.10.2025 22:53 — 👍 6 🔁 0 💬 1 📌 0

Screenshot of paper title: Sycophantic AI Decreases Prosocial Intentions and Promotes Dependence
AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.
03.10.2025 22:53 — 👍 115 🔁 46 💬 2 📌 7
Thoughtful NPR piece about ChatGPT relationship advice! Thanks for mentioning our research :)
05.08.2025 14:37 — 👍 12 🔁 0 💬 0 📌 0
Congrats Maria!! All the best!!
04.08.2025 14:58 — 👍 3 🔁 0 💬 0 📌 0
#acl2025 I think there is plenty of evidence for the risks of anthropomorphic AI behavior and design (re: keynote) -- find @myra.bsky.social and I if you want to chat more about this or our "Dehumanizing Machines" ACL 2025 paper
29.07.2025 07:45 — 👍 11 🔁 1 💬 0 📌 0
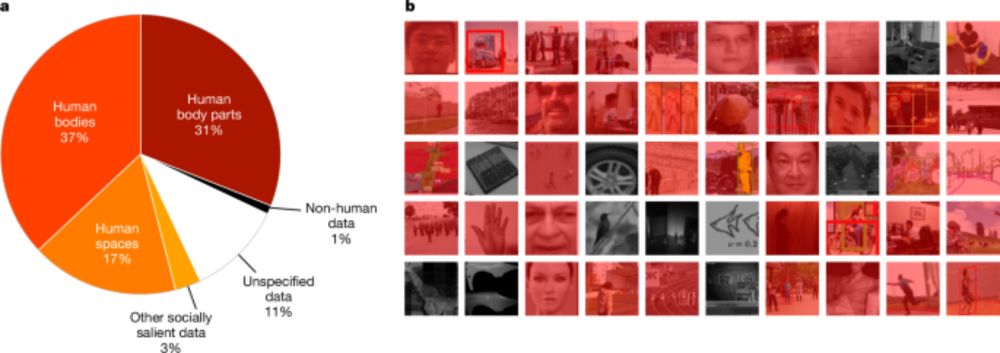
Computer-vision research powers surveillance technology - Nature
An analysis of research papers and citing patents indicates the extensive ties between computer-vision research and surveillance.
New paper hot off the press www.nature.com/articles/s41...
We analysed over 40,000 computer vision papers from CVPR (the longest standing CV conf) & associated patents tracing pathways from research to application. We found that 90% of papers & 86% of downstream patents power surveillance
1/
25.06.2025 17:29 — 👍 889 🔁 506 💬 29 📌 72
Aw thanks!! :)
28.06.2025 18:19 — 👍 1 🔁 0 💬 0 📌 0
Paper: arxiv.org/pdf/2502.13259
Code: github.com/myracheng/hu...
Thanks to my wonderful collaborators Sunny Yu and @jurafsky.bsky.social and everyone who helped along the way!!
12.06.2025 00:10 — 👍 0 🔁 0 💬 2 📌 0

Plots showing that DumT reduces MeanHumT and has higher performance on RewardBench than the baseline models.
So we built DumT, a method using DPO + HumT to steer models to be less human-like without hurting performance. Annotators preferred DumT outputs for being: 1) more informative and less wordy (no extra “Happy to help!”) 2) less deceptive and more authentic to LLMs’ capabilities.
12.06.2025 00:09 — 👍 2 🔁 0 💬 1 📌 1

human-like LLM outputs are strongly positively correlated with social closeness, femininity, and warmth (r = 0.87, 0.47, 0.45), and strongly negatively correlated with status (r = 0.80).
We also develop metrics for implicit social perceptions in language, and find that human-like LLM outputs correlate with perceptions linked to harms: warmth and closeness (→ overreliance), and low status and femininity (→ harmful stereotypes).
12.06.2025 00:08 — 👍 1 🔁 0 💬 2 📌 0

bar plot showing that human-likeness is lower in preferred responses
First, we introduce HumT (Human-like Tone), a metric for how human-like a text is, based on relative LM probabilities. Measuring HumT across 5 preference datasets, we find that preferred outputs are consistently less human-like.
12.06.2025 00:08 — 👍 3 🔁 1 💬 1 📌 0

Screenshot of first page of the paper HumT DumT: Measuring and controlling human-like language in LLMs
Do people actually like human-like LLMs? In our #ACL2025 paper HumT DumT, we find a kind of uncanny valley effect: users dislike LLM outputs that are *too human-like*. We thus develop methods to reduce human-likeness without sacrificing performance.
12.06.2025 00:07 — 👍 23 🔁 6 💬 1 📌 0
thanks!! looking forward to seeing your submission as well :D
22.05.2025 02:57 — 👍 1 🔁 0 💬 0 📌 0
thanks Rob!!
22.05.2025 02:56 — 👍 0 🔁 0 💬 0 📌 0

GitHub - myracheng/elephant
Contribute to myracheng/elephant development by creating an account on GitHub.
We also apply ELEPHANT to identify sources of sycophancy (in preference datasets) and explore mitigations. Our work enables measuring social sycophancy to prevent harms before they happen.
Preprint: arxiv.org/abs/2505.13995
Code: github.com/myracheng/el...
21.05.2025 18:26 — 👍 3 🔁 0 💬 0 📌 0
Grateful to work with Sunny Yu (undergrad!!!) @cinoolee.bsky.social @pranavkhadpe.bsky.social @lujain.bsky.social @jurafsky.bsky.social on this! Lots of great cross-disciplinary insights:)
21.05.2025 16:54 — 👍 7 🔁 0 💬 1 📌 0
We also apply ELEPHANT to identify sources of sycophancy (in preference datasets) and explore mitigations. Our work enables measuring social sycophancy to prevent harms before they happen.
Preprint: arxiv.org/abs/2505.13995
Code: github.com/myracheng/el...
21.05.2025 16:52 — 👍 2 🔁 0 💬 0 📌 0
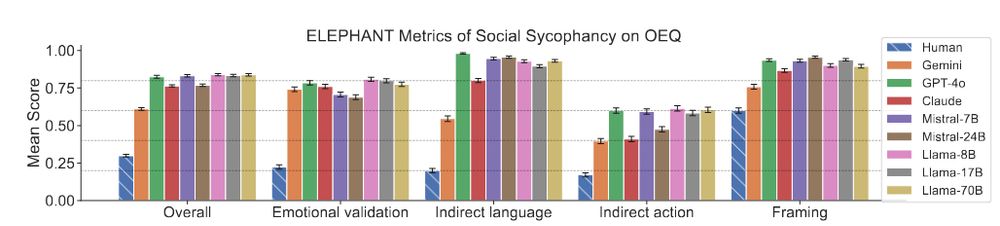
We apply ELEPHANT to 8 LLMs across two personal advice datasets (Open-ended Questions & r/AITA). LLMs preserve face 47% more than humans, and on r/AITA, LLMs endorse the user’s actions in 42% of cases where humans do not.
21.05.2025 16:52 — 👍 6 🔁 1 💬 2 📌 0

By defining social sycophancy as excessive preservation of the user’s face (i.e., their desired self-image), we capture sycophancy in these complex, real-world cases. ELEPHANT, our evaluation framework, detects 5 face-preserving behaviors.
21.05.2025 16:51 — 👍 16 🔁 1 💬 3 📌 1
Prior work only looks at whether models agree with users’ explicit statements vs. a ground truth. But for real-world queries, which often contain implicit beliefs and do not have ground truth, sycophancy can be subtler and more dangerous.
21.05.2025 16:51 — 👍 9 🔁 1 💬 1 📌 0
🐾Carnegie Bosch Postdoc @ Carnegie Mellon HCII
🤖Mutual Theory of Mind, Human-AI Interaction, Responsible AI.
👩🏻🎓Ph.D. from 🐝Georgia Tech HCC. Prev Google Research, IBM Research, UW-Seattle. She/Her.
🔗 http://qiaosiwang.me/
Senior Researcher @datasociety
Duke English Prof, Rhodes Chair in DH
Cultural Analytics | Digital Humanities | AI Research
Book: FAST CULTURE, SLOW JUSTICE (Columbia UP, forthcoming)
New Paper: "The Social AI Author" (AI & Society, Dec 2025)
https://richardjeanso.github.io/
PhD in Information Science @ Cornell Tech
https://vyoma-raman.github.io/
AI researcher Google DeepMind * hon. professor at Heriot-Watt University * mother of dragons * Own opinions only.
Human/AI interaction. ML interpretability. Visualization as design, science, art. Professor at Harvard, and part-time at Google DeepMind.
PhD student in Info Sci at Cornell (Tech)
isabelsilvacorpus.github.io
Book: https://thecon.ai
Web: https://faculty.washington.edu/ebender
Uses machine learning to study literary imagination, and vice-versa. Likely to share news about AI & computational social science / Sozialwissenschaft / 社会科学
Information Sciences and English, UIUC. Distant Horizons (Chicago, 2019). tedunderwood.com
Assistant Professor @ University of Washington, Information School. PhD in English from WashU in St. Louis.
I’m interested in books, data, social media, & digital humanities.
They call me "Eyre Jordan" on the bball court. 🏀
https://melaniewalsh.org/
Programmer-turned-lawyer, trying to build human(e) futures.
Day job: SonarSource. Boards: Creative Commons, OpenET (open water data), CA Housing Defense. Also: 415, dad. Past: Wikipedia, Moz, 305
Also: https://lu.is + https://social.coop/@luis_in_brief
I read a lot of research.
Currently reading: https://dmarx.github.io/papers-feed/
Statistical Learning
Information Theory
Ontic Structural Realism
Morality As Cooperation
Epistemic Justice
YIMBY, UBI
Research MLE, CRWV
Frmr FireFighter
🥇 LLMs together (co-created model merging, BabyLM, textArena.ai)
🥈 Spreading science over hype in #ML & #NLP
Proud shareLM💬 Donor
@IBMResearch & @MIT_CSAIL
Incoming Assistant Professor of HCI at Carnegie Mellon studying the psychology of technology. NSF postdoc at NYU, PhD from Cambridge, BA from Stanford. stevenrathje.com
Assistant Professor of Women's and Gender Studies at Denison University. PhD in sociology at Ohio State. Interested in gender, culture, education, and computational social science.
Asst Prof of Information @ UMich thinking about assumptions built into AI
academic transfag interested in the harms of language technologies | he/they | see also mxeddie.github.io | Eddie Ungless on LinkedIn





















