Personally, I will be looking to mentor projects with Mahindra Rautela on (1) Search and Evaluation for test-time AI Reasoning, and (2) model distillation to compress large physics foundation models.
Please feel free to get in touch with questions or to express interest.
28.01.2026 19:36 — 👍 0 🔁 1 💬 0 📌 0
with @robmok.bsky.social and Xiaoliang "Ken" Luo
25.11.2025 19:35 — 👍 5 🔁 1 💬 0 📌 0
Intuitive cell types don't necessarily play the ascribed functional role in the overall computation. This is not a message the field wants to hear as it suggests better baselines, controls, and some reflection. elifesciences.org/reviewed-pre... 2/2
25.11.2025 19:29 — 👍 13 🔁 3 💬 1 📌 0
"The inevitability and superfluousness of cell types in spatial cognition". Intuitive cell types are found in random artificial networks using the same selection criteria neuroscientists use with actual data. elifesciences.org/reviewed-pre... 1/2
25.11.2025 19:29 — 👍 45 🔁 15 💬 4 📌 3

We developed a straightforward method of combining confidence-weighted judgments for any number of humans and AIs. w Felipe Yáñez, Omar Valerio Minero, @ken-lxl.bsky.social 2/2
25.11.2025 19:05 — 👍 0 🔁 0 💬 0 📌 0

How neuroscientists are using AI
Eight researchers explain how they are using large language models to analyze the literature, brainstorm hypotheses and interact with complex datasets.
Researchers are using LLMs to analyze the literature, brainstorm hypotheses, build models and interact with complex datasets. Hear from @mschrimpf.bsky.social, @neurokim.bsky.social, @jeremymagland.bsky.social, @profdata.bsky.social and others.
#neuroskyence
www.thetransmitter.org/machine-lear...
04.11.2025 16:07 — 👍 26 🔁 9 💬 0 📌 2

Home
Your local police force - online. Report a crime, contact us and other services, plus crime prevention advice, crime news, appeals and statistics.
moderation@blueskyweb.xyz, send to me, or send directly to the Met (London police) who are investigating www.met.police.uk. I could see this being super distressing for a vulnerable person, so hope this does not become more common. For me, it's been an exercise in rapidly learning to not care! 2/2
18.07.2025 22:14 — 👍 3 🔁 0 💬 0 📌 0
Some UK dude is trying to extort me, demanding money to not spread made-up stories. I reported to the poilice after getting flooded with phone messages I never listen to, etc. @bsky.app has been good about deleting his posts and accounts. If contacted, don't interact, but instead report to...1/2
18.07.2025 22:14 — 👍 4 🔁 0 💬 2 📌 0

https://bradlove.org/blog/prob-llm-consistency
New blog, "Backwards Compatible: The Strange Math Behind Word Order in AI" w @ken-lxl.bsky.social It turns out the language learning problem is the same for any word order, but is that true in practice for large language models? paper: arxiv.org/abs/2505.08739 BLOG: bradlove.org/blog/prob-ll...
28.05.2025 14:15 — 👍 4 🔁 1 💬 3 📌 0
with @ken-lxl.bsky.social , @robmok.bsky.social , Brett Roads
17.02.2025 15:23 — 👍 1 🔁 0 💬 2 📌 0

Coordinating multiple mental faculties during learning - Scientific Reports
Scientific Reports - Coordinating multiple mental faculties during learning
"Coordinating multiple mental faculties during learning" There's lots of good work in object recognition and learning, but how do we integrate the two? Here's a proposal and model that is more interactive than perception provides the inputs to cognition. www.nature.com/articles/s41...
17.02.2025 15:23 — 👍 31 🔁 9 💬 3 📌 1
Last year, we funded 250 authors and other contributors to attend #ICLR2024 in Vienna as part of this program. If you or your organization want to directly support contributors this year, please get in touch! Hope to see you in Singapore at #ICLR2025!
21.01.2025 15:52 — 👍 37 🔁 14 💬 1 📌 0
Thanks @hossenfelder.bsky.social for covering our recent paper, doi.org/10.1038/s415... Also, I want to spotlight this excellent podcast (19 minutes long) with Nicky Cartridge covering how AI will impact science and healthcare in the coming years, touchneurology.com/podcast/brai...
13.12.2024 15:44 — 👍 14 🔁 1 💬 2 📌 1
A 7B is small enough to train efficiently on 4 A100s (thanks Microsoft) and at the time Mistral performed relatively well for its size.
27.11.2024 17:11 — 👍 7 🔁 0 💬 1 📌 0
Yes, the model weights and all materials are openly available. We really want to offer easy to use tools people can use through the web without hassle. To do that, we need to do more work (will be announcing an open source effort soon) and need some funding for hosting a model endpoint.
27.11.2024 17:09 — 👍 9 🔁 0 💬 1 📌 0

BrainGPT
This is the homepage for BrainGPT, a Large Language Model tool to assist neuroscientific research.
While BrainBench focused on neuroscience, our approach is science general, so others can adopt our template. Everything is open weight and open source. Thanks to the entire team and the expert participants. Sign up for news at braingpt.org 8/8
27.11.2024 14:13 — 👍 11 🔁 0 💬 3 📌 0

Finally, LLMs can be augmented with neuroscience knowledge for better performance. We tuned Mistral on 20 years of the neuroscience literature using LoRA. The tuned model, which we refer to as BrainGPT, performed better on BrainBench. 7/8
27.11.2024 14:13 — 👍 7 🔁 0 💬 1 📌 0
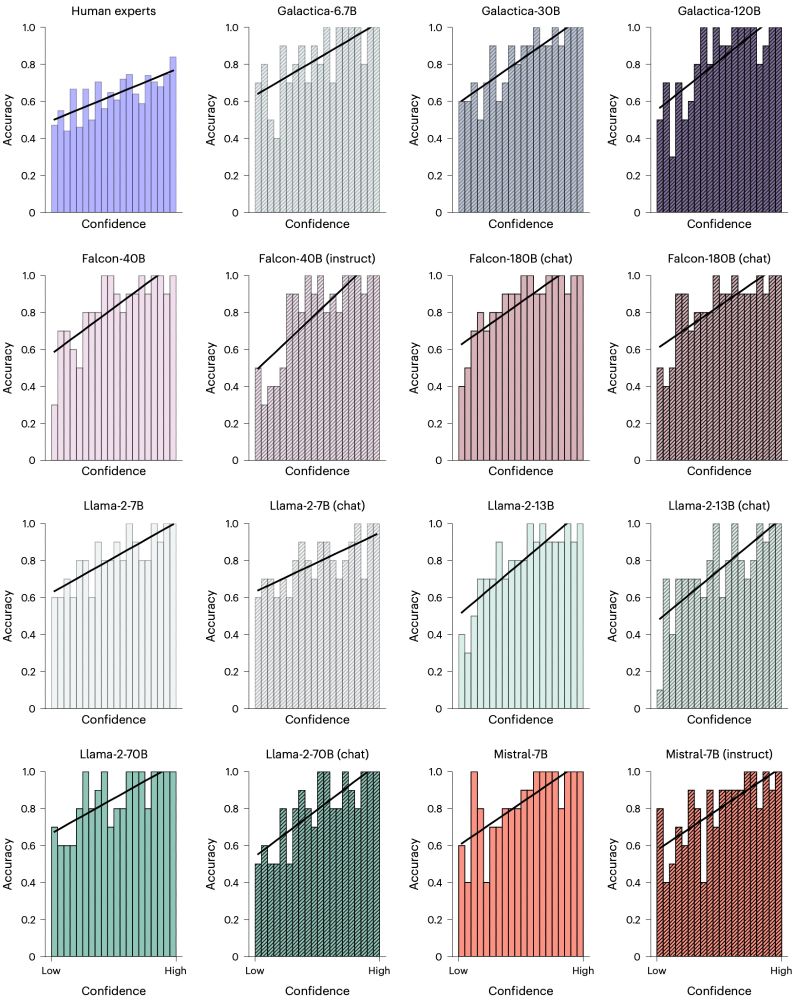
In the Nature HB paper, both human experts and LLMs were well calibrated - when they were more certain of their decisions, they were more likely to be correct. Calibration is beneficial for human-machine teaming. 5/8
27.11.2024 14:13 — 👍 6 🔁 0 💬 1 📌 0
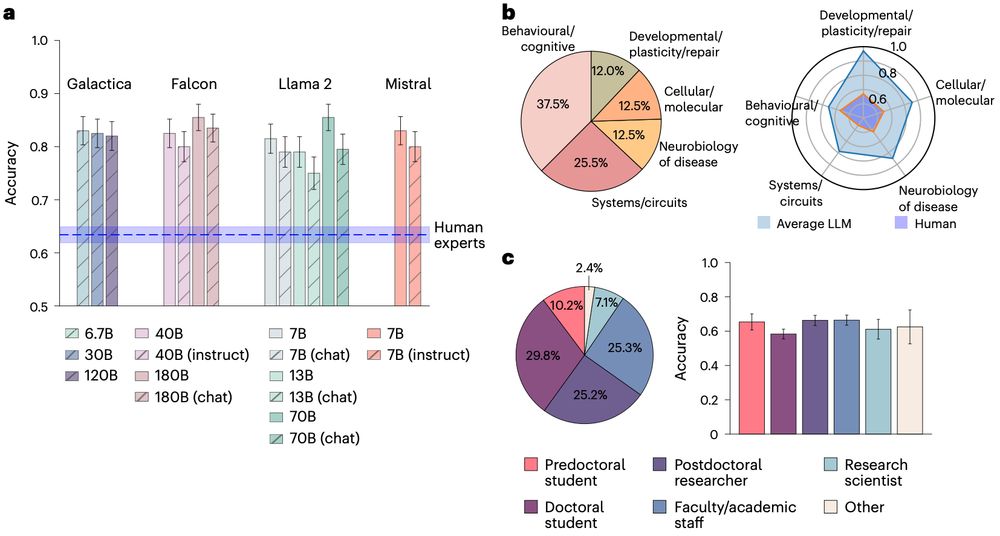
All 15 LLMs considered crushed human experts at BrainBench's predictive task. LLMs correctly predicted neuroscience results (across all sub areas) dramatically better than human experts, including those with decades of experience. 3/8
27.11.2024 14:13 — 👍 10 🔁 0 💬 1 📌 0
Postdoctoral Researcher in Computational Neuroscience & Psychiatry
@Yale University | Previously Icahn School of Medicine at Mount Sinai | PhD from UCL Max Planck Centre & Wellcome Trust Centre for Neuroimaging UCL
She/Her
Neuroscientist at the Allen Institute for Neural Dynamics
Assistant Professor of Cognitive Science at Johns Hopkins. My lab studies human vision using cognitive neuroscience and machine learning. bonnerlab.org
Hertie Network of Excellence in Clinical Neuroscience and Hertie Academy of Clinical Neuroscience
Studying cognitive control at Brown University & RIKEN CBS. Incoming Assistant Professor at the University of Maryland (starting 2026 Fall). Almost always failing to behave adaptively — but trying.
Computational Neuroscientist & Neurotechnologist
art & architectural historian / visual, material & religious culture
I'm interested in how animals communicate with sound and I try to make that easier for everyone to study: https://www.vocalpy.org/
Cat & dog dad, cold brew addict, video gamer, Florida boy, #altac, podcast fan, occasional espanglish. nicholdav.info
Assistant Professor of Cognitive Neuroscience | UConn Psych Sci | attention, cognition, mental health, development, environment, personalized neuroscience
@acornlab.bsky.social
arielleskeller.wixsite.com/attention
appliedcognitionlab.psychology.uconn.edu
Postdoc @brognition.bsky.social | Yale University
Research interests: attention | long-term memory | working memory | EEG | machine learning
cogsci postdoc @ ucla
https://sites.google.com/view/nick-ichien/home
Distinguished AI Research Scientist at SentinelOne. Former OpenAI, Apple infosec. Lecturer at John’s Hopkins SAIS Alperovitch Institute. Deceiver of hike length and difficulty.
Professor & Chair, Psychology at the University of Waterloo
I help ambitious people raise capital, get board seats, take companies public. Let's get more entrepreneurs and builders on bsky!
Author of 4 best selling business books
🧠 PhD student at the University of Toronto | The Memory & Perception Lab and The Duncan Lab
Professor in Brain & Cognition, KU Leuven, Belgium - The brain rules the mind; would-be runner and musician.
Exploring how the brain uses specialized knowledge in domain-general cognition.
NeuroSPACE unites 4 labs led by @hansopdebeeck.bsky.social, @bertdesmedt.bsky.social, @kobedesender.bsky.social & @neuropsylab.bsky.social.
🌐 ppw.kuleuven.be/neurospace
Experimental psychologist at the Uni of Hull studying Theory of mind and knowledge processing. Also physics, philosophy, beer and drums. A bit deaf.
I build mathematical models to understand cognition and behavior. Care about history and philosophy of science.
Tenured Senior Scientist, Department of Psychology, University of Zurich.
https://venpopov.com


























