Yeah of course
18.09.2025 14:13 — 👍 2 🔁 0 💬 0 📌 0
This includes full Datadog tracing/logs/metrics by the way.
There's no compromising on observability, not even cold starts.
18.09.2025 13:03 — 👍 0 🔁 0 💬 1 📌 0


I use AWS a ton but Lambda still astounds me. Throw some code in a function, send 1m requests as fast as you can.
It ate up all available file descriptors on my little t3 box and still ran 18k RPS with a p99 of 0.3479s. Not many services can go from 0 to 18k RPS instantaneously with this p99.
18.09.2025 13:03 — 👍 9 🔁 3 💬 1 📌 0
The faster your cold starts are, the cheaper these will be!
05.08.2025 17:51 — 👍 1 🔁 0 💬 0 📌 0
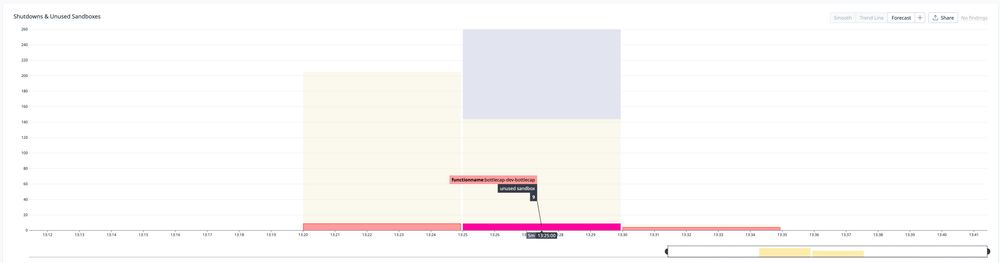
Lambda now charges for init time, so it's useful to count sandboxes which are proactively initialized but never receive a request.
Here's what happens after a 10k request burst. Hundreds of sandbox shutdowns, along with 22 sandboxes which were spun up but never received a request.
05.08.2025 17:51 — 👍 3 🔁 0 💬 1 📌 0

Happy Lambda Init Billing day to those who celebrate. Fix your cold starts!
01.08.2025 15:04 — 👍 4 🔁 0 💬 1 📌 0
Yeah!
01.08.2025 08:43 — 👍 1 🔁 0 💬 0 📌 0

NEW: Lambda can now send up to 200mb payloads using response streaming! I assume this is mostly directed at LLM inference workloads, where chatbots can stream large amounts of data over the wire as it becomes available.
01.08.2025 01:10 — 👍 3 🔁 0 💬 2 📌 0
That said, I'm excited to share that @Datadog's Serverless monitoring product now supports LWA!
Thanks to Harold and AWS Labs for collaborating with us on the PRs, and huge thanks to Alex Gallotta for driving this work.
30.07.2025 17:43 — 👍 0 🔁 0 💬 1 📌 0
I've long been an advocate for the Lambda Web Adapter project which lets anyone pretty easily ship an app to Lambda without learning about the event model/API.
Honestly AWS should simply support this natively.
30.07.2025 17:43 — 👍 2 🔁 1 💬 1 📌 0

Today, Sam Lambert from Planetscale is back for a third time. Planetscale just announced Planetscale Postgres, so we had to get Sam back to tell us how and why they decided to add support for Postgres. It's always great to have Sam on -- he brings great stories about real customers and honest insight about the state of the database industry.
In this episode, we talk about the road to Postgres and how operational excellence is the only true advantage in database providers. Sam walks us through the current Planetscale Postgres offering, along with details on Nova, a new sharded Postgres project that Planetscale is working on. Along the way, we get updates on Planetscale Metal, how demand has been for Planetscale Postgres, and future plans for Planetscale.
*Timestamps*
01:16 Start
06:37 The Timeline
15:15 Not Much IP in the Database Market
21:48 PSBouncer
24:17 Zonal affinity
27:38 Query Insights
29:34 How to sign up
32:02 Convex
34:37 Other data stores?
56:18 Acquisitions
Operational Excellence Is the Moat with Sam Lambert
I'm a big fan of continuous profiling/measuring your software against real world use cases. This is also how I often learn about in to new system changes in AWS early, heh.
Great episode of Software Huddle w/ @alexbdebrie: www.youtube.com/watch?v=JAw9...
28.07.2025 14:59 — 👍 1 🔁 0 💬 0 📌 0
"We run benchmarks continually across all of our competitors, not just queries - even connections, ensuring we don't add any latency at all." @isamlambert
Performance is such a competitive advantage which easily slips away if you're not constantly paying attention to it.
28.07.2025 14:59 — 👍 3 🔁 0 💬 1 📌 0

Datadog rewrote its AWS Lambda Extension from #Golang to #Rustlang with no prior Rust experience. @ajs.bsky.social will share how they achieved an 80% Lambda cold start improvement along with a 50% memory footprint reduction at our free and virtual #P99CONF. www.p99conf.io?latest_sfdc_...
#ScyllaDB
23.07.2025 14:17 — 👍 6 🔁 3 💬 0 📌 0
In our case the secret is a Datadog API key which isn't required until we actually flush data, so deferring it to that point saves us over 50ms.
22.07.2025 15:31 — 👍 2 🔁 1 💬 0 📌 0
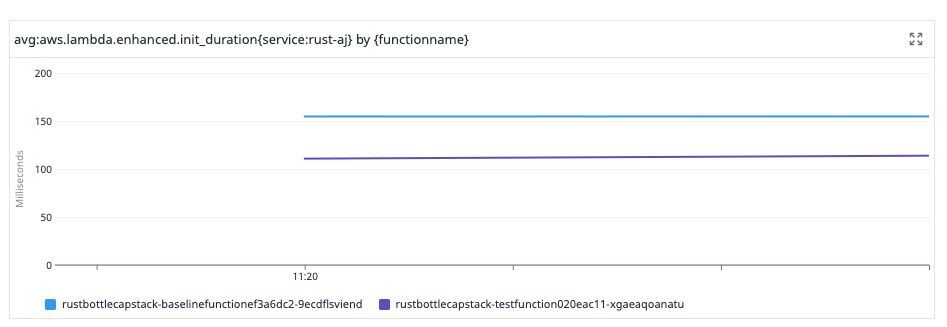
Here's another 33% cold start reduction, which comes from deferring expensive decryption calls made to AWS Secrets Manager until the secret is actually needed.
Lazy loading is great!
22.07.2025 15:31 — 👍 3 🔁 1 💬 1 📌 0
50% lol was not reading the profile carefully
18.07.2025 16:45 — 👍 0 🔁 0 💬 0 📌 0
By switching to a memory arena, we preallocate a slab of memory and virtually eliminate the linear growth of malloc syscalls, which cuts down kernel mode switches, improving latency.
Thank you profiling (and jemalloc)!
18.07.2025 15:07 — 👍 0 🔁 0 💬 0 📌 0
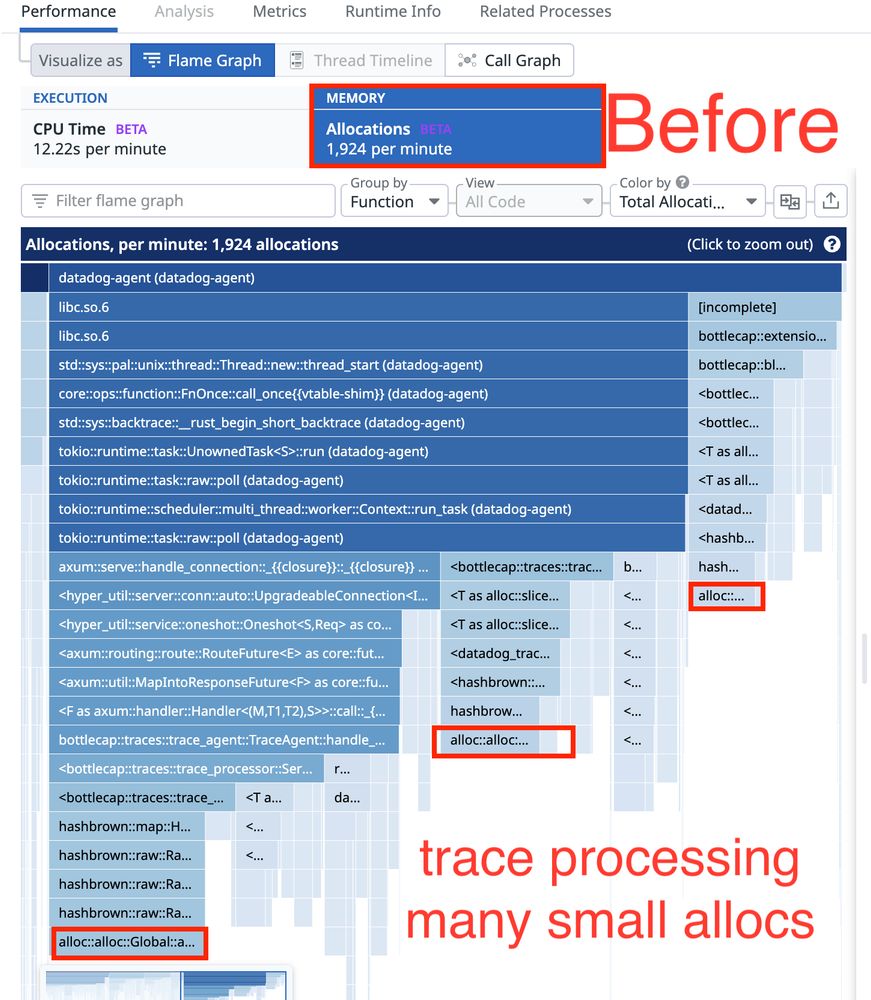
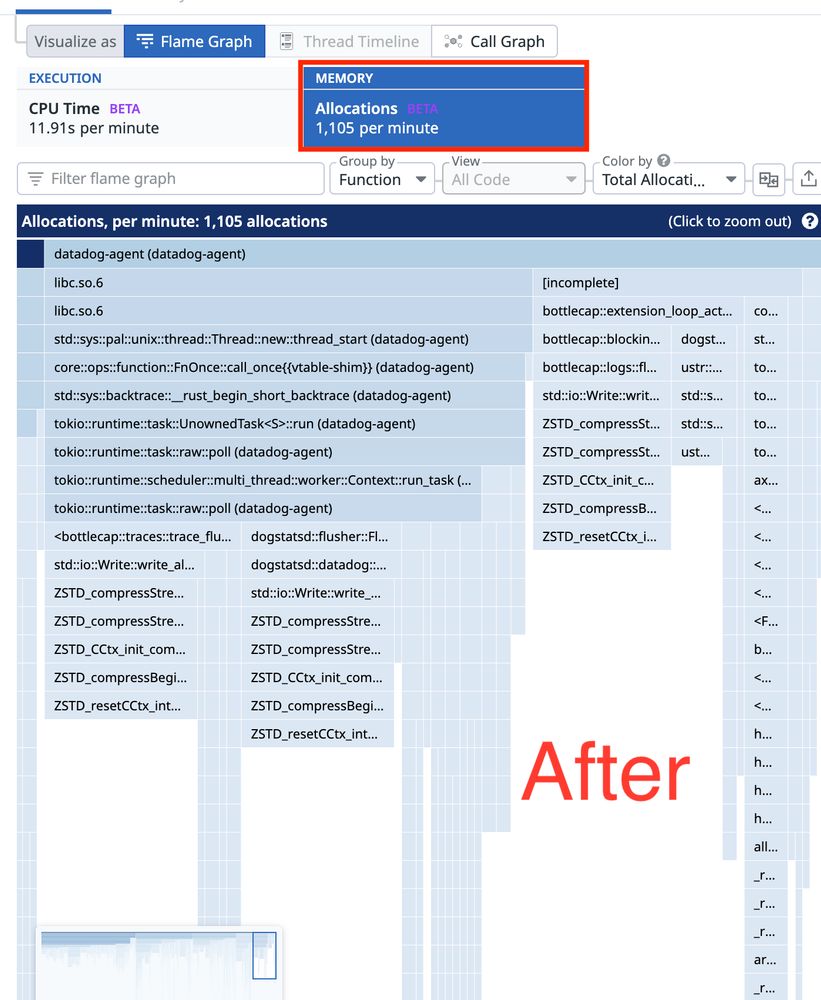
Here's how to visualize a 100% memory allocation improvement!
A recent stress test revealed that malloc calls bottlenecked when sending > 100k spans through the API and aggregator pipelines in Lambda.
18.07.2025 15:07 — 👍 1 🔁 0 💬 2 📌 0
Now writing a job to a log and then using a subscription filter to run them async is deeply fucking cursed though omg
17.07.2025 17:01 — 👍 1 🔁 0 💬 1 📌 0
I think OP's intentions were pretty pure until they felt they were mistreated by AWS. So many people end up taking to social media in those instances so in my opinion it was mostly fine.
17.07.2025 17:01 — 👍 0 🔁 0 💬 1 📌 0
Thanks Corey!
17.07.2025 16:41 — 👍 0 🔁 0 💬 0 📌 0
cc @quinnypig.com, as I saw this post in your newsletter
17.07.2025 16:25 — 👍 1 🔁 0 💬 1 📌 0

NEW: A recent blog post went viral in the AWS ecosystem, about how there's a silent crash in AWS Lambda's NodeJS runtime.
Today I'll step you through the actual Lambda runtime code which causes this confusing issue, and walk you through how to safely perform async work in Lambda:
17.07.2025 15:29 — 👍 7 🔁 0 💬 3 📌 0
I assume this helps with capacity, especially as so many functions are triggered on schedules for the top of the hour or on a routine call schedule.
I've long suspected that I could get faster cold starts/placements by scheduling a function at the 58th minute instead of the top of the hour.
14.07.2025 16:07 — 👍 1 🔁 0 💬 0 📌 0
Now after only ~4 invocation/shutdown cycles, Lambda shuts down the sandbox 1 minute after my request:
14.07.2025 16:07 — 👍 1 🔁 0 💬 1 📌 0
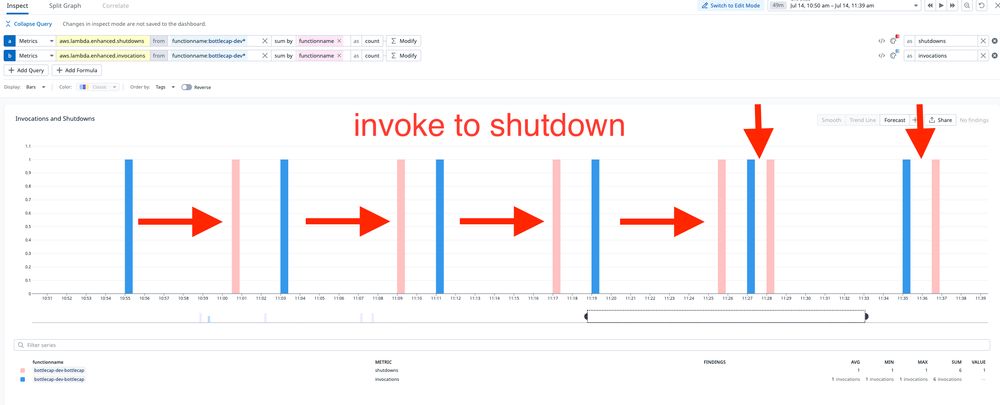
Lambda's fleet management shutdown algorithm is learning faster!
I'm calling this function every 8 or so minutes. At first the gap from invocation to shutdown is about 5-6 minutes, which was the fastest I've observed during previous experiments.
14.07.2025 16:07 — 👍 3 🔁 0 💬 1 📌 0

NEW: AWS is rolling out a new free tier beginning July 15th!!
New accounts get $100 in credits to start and can earn $100 exploring AWS resources. You can now explore AWS without worrying about incurring a huge bill, this is great!
docs.aws.amazon.com/awsaccountbi...
11.07.2025 15:23 — 👍 6 🔁 2 💬 0 📌 0
Staff Software Engineer - Datadog APM
(he/him/his)
Dad
Royal Oak, MI
https://bryanenglish.com
All Boston, all the time, and, yeah, that includes turkeys, helicopters and the odd chicken.
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
AWS Hero | Cloud Consultant
Chief Cloud Architect at Defiance Digital. AWS DevTools Hero. Co-author of The CDK Book. One typo in each post.
My Advanced CDK Course at matthewbonig.sidkik.app
Software Engineer | Everything Serverless at Datadog | Making Games/Pixel Art/Retro Stuff on the Side
Sincere poster. No cynicism. Dad to two sets of twins! Co-founder of tryhardstudios.com
- https://MasteringPostgres.com
- https://HighPerformanceSQLite.com
- https://screencasting.com
- https://mostlytechnical.com
- https://aaronfrancis.com
Husband, Father, Principal Engineer @ AWS,
AWS CloudFormation (previously: AWS SAM/SAR, Amazon Fulfillment, AWS MTurk), Blogger, Coder, Hockey fan 🏒🥅
Creator of 99% Invisible, WRMCLACL, Power Broker Breakdown - http://99pi.org
TEDTalk on flags has over 7M views
NYT Bestseller The 99% Invisible City: http://99pi.org/book
East Bay, CA
Alum: Oberlin, Simon's Rock of Bard, UGA
AWS Serverless Hero. Product manager. Devtools, entrepreneurship, observability, cloud infrastructure.
Technologist | Speaker | Author | AWS Serverless Hero | Team Topologies Advocate | Serverless Development on AWS (O'Reilly) | Speak Effectively At Conferences
https://sheenbrisals.com
🇲🇽 🇺🇸 | Soccer Coach | Dad | Serverless | AWS Community Builder | Principal Software Architect @ Caylent
Founding Engineer @momentohq | AWS Serverless Community Builder
🇺🇸🏳️🌈🏳️⚧️🥄❄️🐆👩🏽💻 in 🇦🇺🇨🇦 working on 🍯⬢🔭
she/it
Cofounder/CEO at DuckbillHQ.com. @mike_julian on Twitter
Principal Systems Engineer @Cloudflare • Prev @GatsbyJS
AWS Community Builder | Senior Cloud Engineer @PostNL | Speaker | Blogger | #Serverless Enthusiast | 🇱🇰 🇳🇱 | pubudu.dev























