Excited to launch Principia, a nonprofit research organisation at the intersection of deep learning theory and AI safety.
Our goal is to develop theory for modern machine learning systems that can help us understand complex network behaviors, including those critical for AI safety and alignment.
1
16.02.2026 09:27 —
👍 91
🔁 26
💬 1
📌 1
At #NeurIPS ? Visit our posters! 🧵
Demystifying Spectral Feature Learning for Instrumental Variable Regression: #2600, Wed 11am
Regularized least squares learning with heavy-tailed noise is minimax optimal: #3012, Wed 4:30pm ✨spotlight✨
1/2
01.12.2025 18:31 —
👍 5
🔁 2
💬 1
📌 0
Congrats !
19.09.2025 10:02 —
👍 1
🔁 0
💬 1
📌 0
AISTATS 2026 will be in Morocco!
30.07.2025 08:07 —
👍 35
🔁 10
💬 0
📌 0
I have been looking at the draft for a while, I am surprised you had a hard time publishing it, it is a super cool work! Will it be included in the TorchDR package ?
27.06.2025 10:17 —
👍 1
🔁 0
💬 1
📌 0

Distributional Reduction paper with H. Van Assel, @ncourty.bsky.social, T. Vayer , C. Vincent-Cuaz, and @pfrossard.bsky.social is accepted at TMLR. We show that both dimensionality reduction and clustering can be seen as minimizing an optimal transport loss 🧵1/5. openreview.net/forum?id=cll...
27.06.2025 07:44 —
👍 33
🔁 9
💬 1
📌 1
Dimitri Meunier, Antoine Moulin, Jakub Wornbard, Vladimir R. Kostic, Arthur Gretton
Demystifying Spectral Feature Learning for Instrumental Variable Regression
https://arxiv.org/abs/2506.10899
13.06.2025 04:37 —
👍 1
🔁 2
💬 0
📌 0
Very much looking forward to this ! 🙌 Stellar line-up
29.05.2025 14:41 —
👍 2
🔁 1
💬 0
📌 0


new preprint with the amazing @lviano.bsky.social and @neu-rips.bsky.social on offline imitation learning! learned a lot :)
when the expert is hard to represent but the environment is simple, estimating a Q-value rather than the expert directly may be beneficial. lots of open questions left though!
27.05.2025 07:12 —
👍 18
🔁 3
💬 1
📌 1
TL;DR:
✅ Theoretical guarantees for nonlinear meta-learning
✅ Explains when and how aggregation helps
✅ Connects RKHS regression, subspace estimation & meta-learning
Co-led with Zhu Li 🙌, with invaluable support from @arthurgretton.bsky.social, Samory Kpotufe.
26.05.2025 16:50 —
👍 0
🔁 0
💬 0
📌 0
Even with nonlinear representation you can estimate the shared structure at a rate improving in both N (tasks) and n (samples per task). This leads to parametric rates on the target task!⚡
Bonus: for linear kernels, our results recover known linear meta-learning rates.
26.05.2025 16:50 —
👍 0
🔁 0
💬 1
📌 0
Short answer: Yes ✅
Key idea💡: Instead of learning each task well, under-regularise per-task estimators to better estimate the shared subspace in the RKHS.
Even though each task is noisy, their span reveals the structure we care about.
Bias-variance tradeoff in action.
26.05.2025 16:50 —
👍 0
🔁 0
💬 1
📌 0
Our paper analyses a meta-learning setting where tasks share a finite dimensional subspace of a Reproducing Kernel Hilbert Space.
Can we still estimate this shared representation efficiently — and learn new tasks fast?
26.05.2025 16:50 —
👍 0
🔁 0
💬 1
📌 0
Most prior theory assumes linear structure: All tasks share a linear representation, and task-specific parts are also linear.
Then: we can show improved learning rates as the number of tasks increases.
But reality is nonlinear. What then?
26.05.2025 16:50 —
👍 0
🔁 0
💬 1
📌 0
Meta-learning = using many related tasks to help learn new ones faster.
In practice (e.g. with neural nets), this usually means learning a shared representation across tasks — so we can train quickly on unseen ones.
But: what’s the theory behind this? 🤔
26.05.2025 16:50 —
👍 1
🔁 0
💬 1
📌 0
Dimitri Meunier, Zikai Shen, Mattes Mollenhauer, Arthur Gretton, Zhu Li
Optimal Rates for Vector-Valued Spectral Regularization Learning Algorithms
https://arxiv.org/abs/2405.14778
24.05.2024 04:06 —
👍 3
🔁 2
💬 0
📌 0
Mattes Mollenhauer, Nicole M\"ucke, Dimitri Meunier, Arthur Gretton: Regularized least squares learning with heavy-tailed noise is minimax optimal https://arxiv.org/abs/2505.14214 https://arxiv.org/pdf/2505.14214 https://arxiv.org/html/2505.14214
21.05.2025 06:14 —
👍 6
🔁 6
💬 1
📌 1
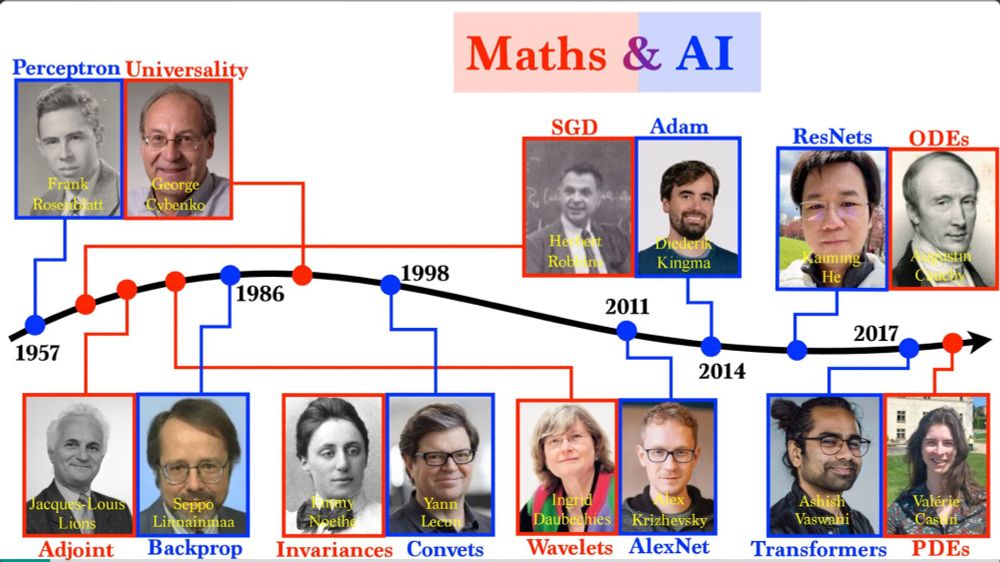
I have updated my slides on the maths of AI by an optimal pairing between AI and maths researchers ... speakerdeck.com/gpeyre/the-m...
20.05.2025 11:21 —
👍 25
🔁 3
💬 3
📌 0
Gabriel Peyr\'e
Optimal Transport for Machine Learners
https://arxiv.org/abs/2505.06589
13.05.2025 06:48 —
👍 4
🔁 1
💬 0
📌 0

New ICML 2025 paper: Nested expectations with kernel quadrature.
We propose an algorithm to estimate nested expectations which provides orders of magnitude improvements in low-to-mid dimensional smooth nested expectations using kernel ridge regression/kernel quadrature.
arxiv.org/abs/2502.18284
08.05.2025 04:29 —
👍 14
🔁 1
💬 1
📌 0

Great talk by Aapo Hyvärinen on non linear ICA at AISTATS 25’!
04.05.2025 02:57 —
👍 7
🔁 0
💬 0
📌 0

Density Ratio-based Proxy Causal Learning Without Density Ratios 🤔
at #AISTATS2025
An alternative bridge function for proxy causal learning with hidden confounders.
arxiv.org/abs/2503.08371
Bozkurt, Deaner, @dimitrimeunier.bsky.social, Xu
02.05.2025 11:29 —
👍 7
🔁 4
💬 0
📌 0
YouTube video by ML New Papers
Interview of Statistics and ML Expert - Pierre Alquier
Link to the video: youtu.be/nLGBTMfTvr8?...
28.04.2025 11:01 —
👍 11
🔁 2
💬 0
📌 1
🤩 c’était super de te revoir Pierre!
01.05.2025 03:01 —
👍 1
🔁 0
💬 0
📌 0

Dinner in Siglap yesterday evening with the members of the ABI team & friends who are attending ICLR.
27.04.2025 09:41 —
👍 9
🔁 1
💬 1
📌 0

Optimality and Adaptivity of Deep Neural Features for Instrumental Variable Regression
#ICLR25
openreview.net/forum?id=ReI...
NNs
✨better than fixed-feature (kernel, sieve) when target has low spatial homogeneity,
✨more sample-efficient wrt Stage 1
Kim, @dimitrimeunier.bsky.social, Suzuki, Li
22.04.2025 22:23 —
👍 8
🔁 3
💬 0
📌 0





