Congrats, Megan!
14.10.2025 05:19 — 👍 1 🔁 0 💬 1 📌 0
I am excited to share that our paper is accepted by @neuripsconf.bsky.social . This is an interesting work that uses tools and insights from comp cog neuroscience to understand LLMs. Nice work by @louannapan.bsky.social and @doctor-bob.bsky.social.
06.10.2025 17:44 — 👍 5 🔁 0 💬 0 📌 0
This result already shows the revealed processes from think aloud, are generative and generalized to their behaviors. The LLM can also learn to reason like humans when giving think aloud examples, which means LLMs not just learn superficial behavioral claims in the think aloud, but also processes.
05.10.2025 00:32 — 👍 0 🔁 0 💬 1 📌 0
Regarding your question about introspective process,I am afraid I cannot agree that people don’t have introspective access to their computation. What we were validating in the paper is that their think aloud are predictive of their behaviors at current trials as well as other trials.
05.10.2025 00:32 — 👍 0 🔁 0 💬 1 📌 0

Scaling up the think-aloud method
The think-aloud method, where participants voice their thoughts as they solve a task, is a valuable source of rich data about human reasoning processes. Yet, it has declined in popularity in contempor...
Thanks for your question, Harrison! The process level insight can be descriptive, algorithmic and computational. For example, you can code the think aloud of human participant in mental arithmetic game, which reveals the search process underlying one move.
arxiv.org/abs/2505.23931
05.10.2025 00:10 — 👍 1 🔁 0 💬 1 📌 0
This work is jointly done by @huadongxiong and @doctor-bob.bsky.social
02.10.2025 03:07 — 👍 0 🔁 0 💬 1 📌 0
OSF
osf.io/6ta3z_v2/
02.10.2025 03:06 — 👍 0 🔁 0 💬 1 📌 0

Can Think-Aloud be really useful in understanding human minds? Building on our previous work, we formally propose reopening this old debate, with one of the largest Think-Aloud datasets, "RiskyThought44K," and LLM analysis, showing Think-Aloud can complement to comp cogsci.
02.10.2025 03:06 — 👍 13 🔁 2 💬 1 📌 1
You are welcome to comment below, share our work, or request codes and data for replication and extension of our work!
31.01.2025 18:50 — 👍 0 🔁 0 💬 0 📌 0
In sum, our work uses an open-ended task to evaluate LLM's open-ended exploration capacity and suggest important differences between traditional LLMs and reasoning models in their cognitive capacity. We want to thank @frabraendle.bsky.social , @candemircan.bsky.social and Huadong Xiong for the help!
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
These attempts provide evidence that the fallback of traditional LLMs in inference paradigms is not a useful way to solve open-ended exploration problems. Instead, test compute scaling in the reasoning model (or we could say 'spending more time to think') can work.
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
In our discussion, we mentioned we have attempted multiple approaches, including prompt engineering, intervention, and seeking model alternatives. None of these approaches changed the situation, except we used the reasoning model, deepseek-r1.
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
This sounds like the models are 'thinking too fast' with their choices dominated by early representations in the models and did not 'wait' until the model effectively integrates empowerment information, which hinders the traditional LLMs from better performance in this task.
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
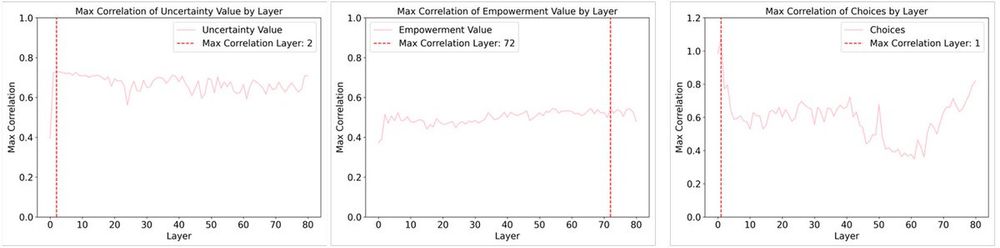
The SAE result suggests that empowerment and uncertainty strategies are represented in LLaMA-3.1 70B, with relatively strong correlations with latent neurons. However, choices and uncertainty are most correlated in early transformer blocks while empowerment is in later blocks.
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
There are two possibilities. The traditional LLMs do not know about 'empowerment,' or they know it but they overlook it in the information processing! To test these hypotheses, we used Sparse AutoEncoders (SAE) to probe whether and where the models represent those strategies.
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
The strategy usage well explains why traditional LLMs are worse than humans and why o1 can surpass human performance (effective strategy use!). Then we are curious why traditional LLMs cannot well balance those strategies.
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
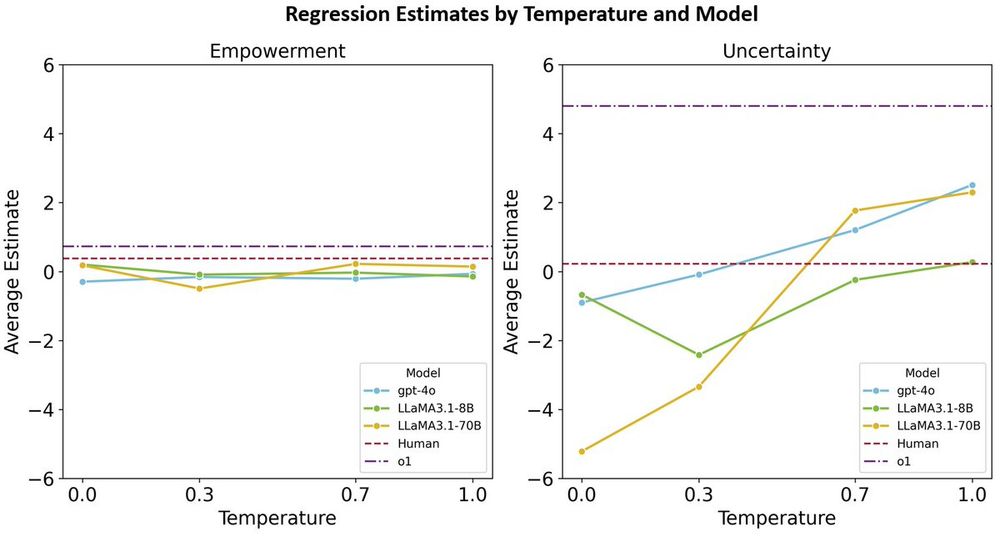
Our results suggest that humans can somehow well balance these two strategies, while traditional LLMs mainly use uncertainty-driven strategies rather than empowerment, which only yields short-term competence when the action space is small. o1 uses both strategies more than humans
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
There are two possible strategies for this task: one is uncertainty-driven, where agents explore based on the uncertainty of elements, while the other is empowerment, where agents explore based on an understanding of the task structure (inventory tree).
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
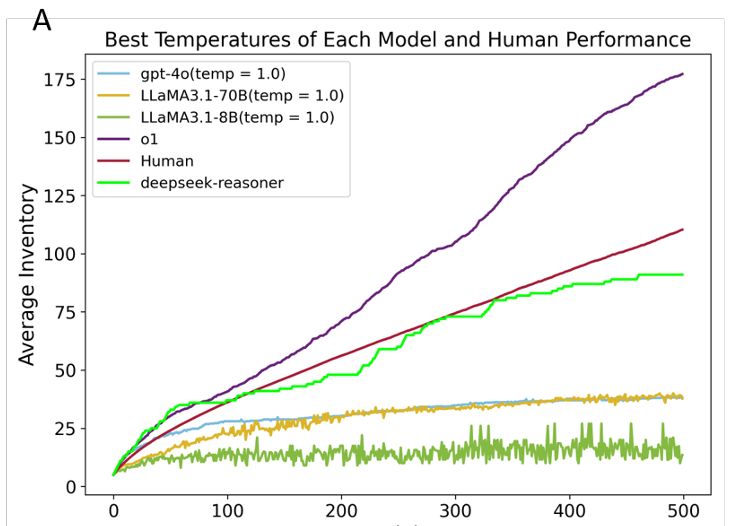
The result is intriguing. For traditional LLMs (GPT-4o, LLaMA-3.1 8B, 70B), their performance is far worse than humans, while for reasoning models like o1 and the popular deepseek-R1 (see appendix), they can surpass or reach human-level performance.
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0

Therefore, we borrowed a paradigm with human data from a game-like experiment-'Little Alchemy 2', where agents combine known elements to invent novel ones. We wonder (1) whether LLMs can do better than humans. (2) what strategies and (3) what mechanisms explain the performance?
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
Exploration is an important capacity of both natural and artificial intelligence. But people rarely discuss how LLMs can explore. Previous studies mainly focus on bandit tasks, which are closed-form questions. However, exploration can also exist in an open-ended environment.
31.01.2025 18:50 — 👍 0 🔁 0 💬 1 📌 0
Thank you for mentioning our work, Carlos.
05.12.2024 13:43 — 👍 3 🔁 0 💬 0 📌 0
Just check back in Bluesky and find this is a great place for science threads!
21.11.2024 15:30 — 👍 1 🔁 0 💬 0 📌 0
魏朝行, Post-doc in Cognitive and Affective Neuroscience Lab @dartmouth. Brain-spinal fMRI, Placebo and Neuromodulation.
💪🏻PhD student at the School of Psychological and Cognitive Sciences, Peking University
#attention #decision-making #eye-tracking
Cognitive scientist / philosopher working on modality and high level cognition.
Cognitive science at Dartmouth
https://phillab.host.dartmouth.edu/
Photo credit: Justin Khoo
Professor of Psychology at NYU (jayvanbavel.com) | Author of The Power of Us Book (powerofus.online) | Director of NYU Center for Conflict & Cooperation | trying to write a new book about collective decisions
🇹🇭 phd candidate w/ @lukejchang.bsky.social in the computational social affective neuroscience lab (cosanlab.com) at @DartmouthPBS.bsky.social
i study social interactions & communication
wasita.space
🇪🇺 European project: Human-centred collaboratIVE MultI-ageNt framework for accelerating software Development and maintenance
👉 https://hivemind-project.eu/
Associate Professor of Computer Science and Psychology @ Princeton. Posts are my views only. https://www.cs.princeton.edu/~bl8144/
Postdoc @NassarLab || information seeking, planning, exploration, latent states, emotion || musical, cheese foam fruit tea, cats!
Finance/Accounting/Tech. Interested in cognitive and social psychology, neuroscience, and policy.
Jamaican 🇯🇲 | White Room Student | True Neutral
Not a bot | Not a follow farmer | I suck at posting so I lurk and like
Neuroscientist. Assistant Professor of Cognition and Brain Science @ GeorgiaTech Prev: Postdoc @ MIT, PhD @ IISc Bangalore
www.murtylab.com
Postdoc at the Princeton University Center for Human Values. Interested in cogsci broadly; primarily belief, (bounded) rationality, and JDM
ORISE Intelligence Community Postdoc @Harvard || agency, emotion, causal inference, reinforcement learning & computational psychiatry || www.hayleydorfman.com
PostDoc at University of Oxford.
Incoming Postdoc at UChicago in Bakkour lab. PhD from WUSTL. Interested in how we build models of the world, naturalistic neuroimaging, and reinforcement learning.
Social psychologist, studying boredom, interest, and thinking (...and why it's so hard for so many of us!). Assistant Professor @ University of Florida 🐊
🌐 erinwestgate.com
📸 https://instagram.com/erin.corwin.westgate
I study STEM learning, development, education, instructional communication, gesture, diagrams. Professor and mom. She/her.
Dad, behavioral and neuroeconomist, sometimes good trouble
PhD Student, Boston University Brain Behavior Cognition | he/they 🏳️🌈
Human Curiosity, Exploration, & Information Seeking: Why do we seek out knowledge and when do we avoid it?
Formerly @MGHPsychiatry & @UMassLowell
https://www.psyc.dev
The 2025 Conference on Language Modeling will take place at the Palais des Congrès in Montreal, Canada from October 7-10, 2025






















