🏆ADVSCORE won an Outstanding Paper Award at #NAACL2025
🚨 Don't miss out on our poster presentation *today at 2 pm* by Yoo Yeon (first author).
📍Poster Session 5 - HC: Human-centered NLP
💼 Highly recommend talking to her if you are hiring and/or interested in Human-focused Al dev and evals!
01.05.2025 12:38 — 👍 7 🔁 1 💬 1 📌 0

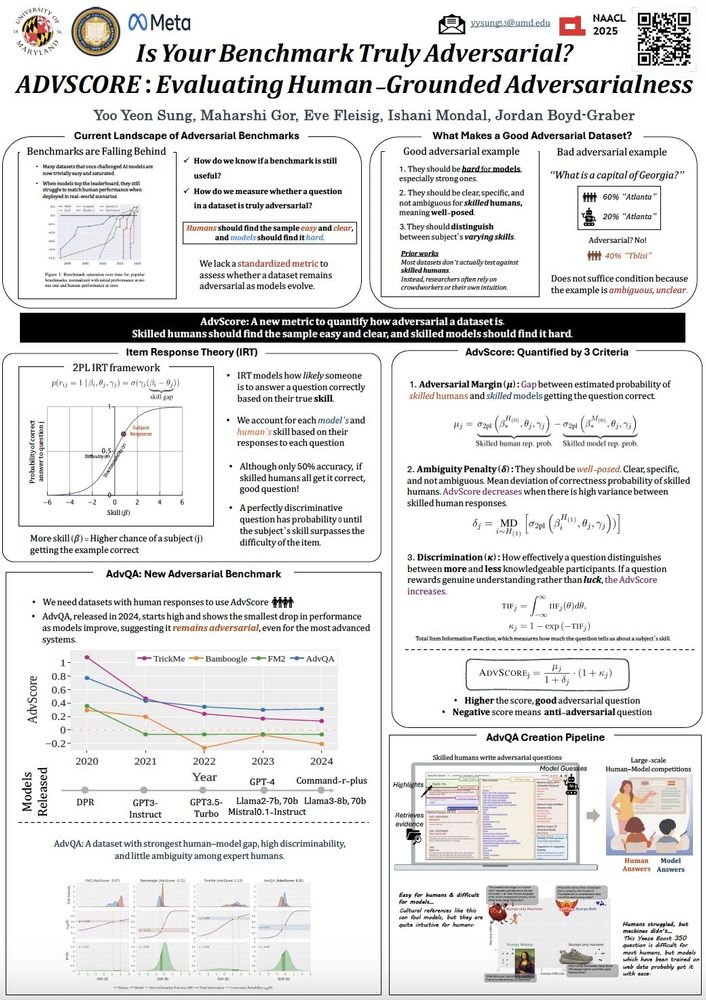
🚨 New Position Paper 🚨
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
24.02.2025 21:03 — 👍 46 🔁 13 💬 2 📌 0

meme with three rows.
"this human-ai decision making leads to unfair outcomes" --> "panik"
"let's show explanations to help people be more fair" --> "kalm"
"those explanations are based on proxy features" --> "panik"
The Impact of Explanations on Fairness in Human-AI Decision-Making: Protected vs Proxy Features
Despite hopes that explanations improve fairness, we see that when biases are hidden behind proxy features, explanations may not help.
Navita Goyal, Connor Baumler +al IUI’24
hal3.name/docs/daume23...
>
09.12.2024 11:41 — 👍 21 🔁 6 💬 1 📌 0

Meme of two muscular arms grasping. The first is labeled "humans" the second "AI systems" and where they grasp is labeled "item response theory."
Do great minds think alike? Investigating Human-AI Complementarity in QA
We use item response theory to compare the capabilities of 155 people vs 70 chatbots at answering questions, teasing apart complementarities; implications for design.
by Maharshi Gor +al EMNLP’24
hal3.name/docs/daume24...
>
12.12.2024 10:40 — 👍 10 🔁 5 💬 2 📌 0
💯
Hallucination is totally the wrong word, implying it is perceiving the world incorrectly.
But it's generating false, plausible sounding statements. Confabulation is literally the perfect word.
So, let's all please start referring to any junk that an LLM makes up as "confabulations".
11.12.2024 14:47 — 👍 205 🔁 45 💬 18 📌 8
I used to like writefull when it was new and there nothing else better. But 🥲
12.12.2024 16:07 — 👍 1 🔁 0 💬 0 📌 0
starter pack for the Computational Linguistics and Information Processing group at the University of Maryland - get all your NLP and data science here!
go.bsky.app/V9qWjEi
10.12.2024 17:14 — 👍 29 🔁 12 💬 1 📌 1
👋🏽 Hey! 🫡
11.11.2024 05:21 — 👍 0 🔁 0 💬 0 📌 0
associate prof at UMD CS researching NLP & LLMs
LLMs and ratings at lmarena.ai
Esports stuff for fun:
https://cthorrez.github.io/riix/riix.html
https://huggingface.co/datasets/EsportsBench/EsportsBench
Building robust LLMs @Cohere
Lifelong learner. BSc in engineering and healthcare, M.Sc. in gerontology and public health.
Acupuncturist, martial artist, hobbyist gardener and carpenter.
Investigator@NLM; machine learning for health. Views my own
https://www.nlm.nih.gov/research/researchstaff/WeissJeremy.html
CS PhD Student. Trying to find that dog in me at UMD. Babysitting (aligning) + Bullying (evaluating) LLMs
nbalepur.github.io
NLP PhD student @UMD. Study how to make visual-language models more trustworthy and useful for humans. Website: http://lingjunzhao.github.io
computational psycholinguistics @ umd
he/him
UMIACS Postdoc - Incoming Assistant Professor @ SBU CS. Vision and Language. Prev. @RiceCompSci @vislang @merl_news @MITIBMLab. EECS Rising Star'23. Former drummer. 🇨🇷
https://paolacascante.com/
PhD student @ University of Maryland, College Park
4th year PhD student in UMD CS advised by Philip Resnik. I have also been a research intern at MSR (2024) and Adobe Research (2022).




















