NeurIPS 2025 Call for Papers
Submit at: https://openreview.net/group?id=NeurIPS.cc/2025/Conference
The NeurIPS Call for Papers is now live. Abstracts are due May 11th AoE, with full papers due May 15th AoE. neurips.cc/Conferences/...
Please read about key changes to Dataset and Benchmarks submissions this year in our blog post: blog.neurips.cc/2025/03/10/n...
10.03.2025 14:02 — 👍 29 🔁 12 💬 0 📌 2
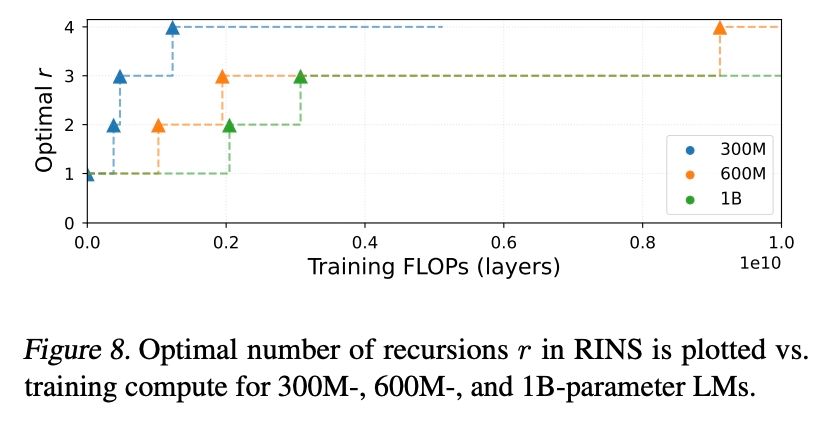
Good, but how many recursion rounds do I need? The optimal number of recursion rounds depends on the model size and training compute budget. Smaller models benefit more from RINS. Also, RINS helps more with long-training durations.
12.02.2025 08:54 — 👍 2 🔁 0 💬 1 📌 0
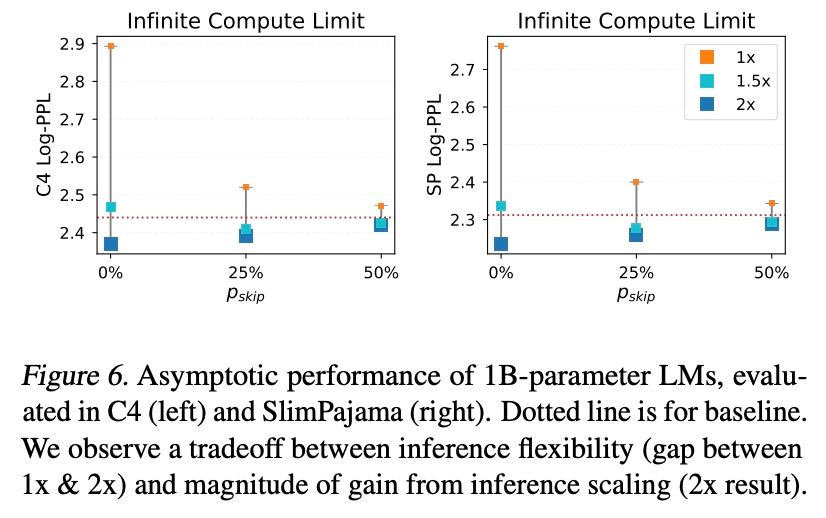
Besides, we also introduce *stochastic* RINS where we select the number of recursion rounds from a binomial distribution. This *improves* performance in SigLIP (despite also *saving* training flops). But in LM, there is a tradeoff between flexibility and maximum performance gain.
12.02.2025 08:54 — 👍 1 🔁 0 💬 1 📌 0
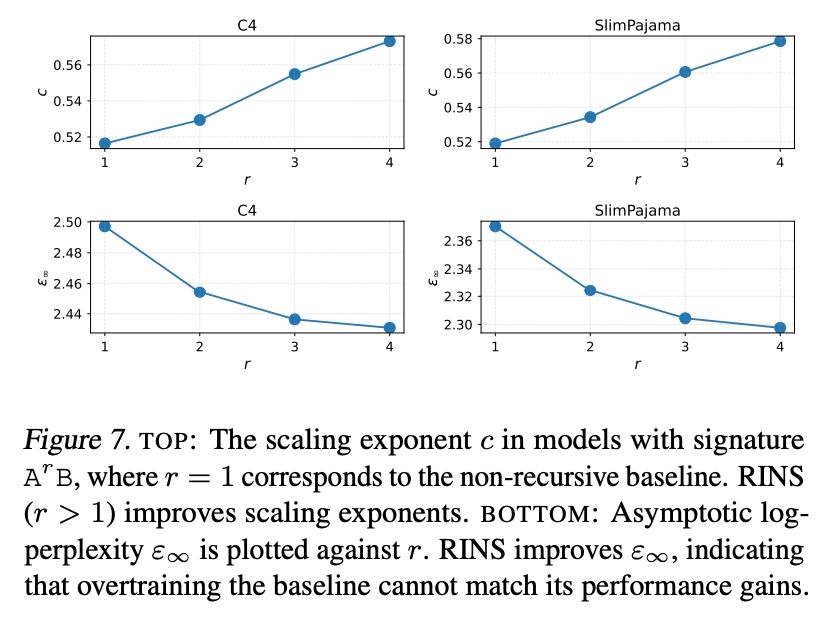
Question: what if we use infinite compute? Will the gap vanish? We did scaling analysis and found that RINS improves both the asymptotic performance limit (so the gap actually increases, not vanishes) and improves convergence speed (scaling exponent).
12.02.2025 08:54 — 👍 1 🔁 0 💬 1 📌 0
Our inspiration came from the study of self-similarity in language. If patterns are shared across scales, could scale-invariant decoding serve as a good inductive bias for processing language? It turns out that it does!
12.02.2025 08:54 — 👍 1 🔁 0 💬 1 📌 0
To repeat, we train RINS on less data to match the same compute flops, which is why this is a stronger result than “sample efficiency”, and one should not just expect it to work. E.g. it does NOT help in image classification but RINS works in language and multimodal. Why? (3/n)🤔
12.02.2025 08:54 — 👍 1 🔁 0 💬 1 📌 0
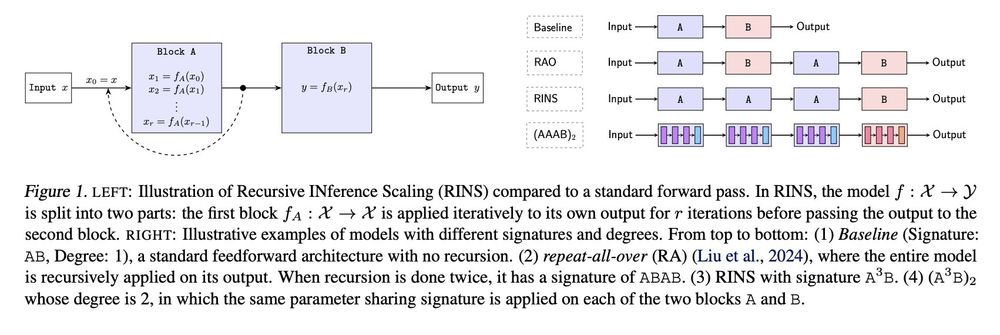
RINS is trivial to implement. After you pick your favorite model & fix your training budget: (1) partition the model into 2 equally-sized blocks, (2) apply recursion on the first and train for the same amount of compute you had planned -> meaning with *fewer* examples! That’s it!
12.02.2025 08:54 — 👍 1 🔁 0 💬 1 📌 0
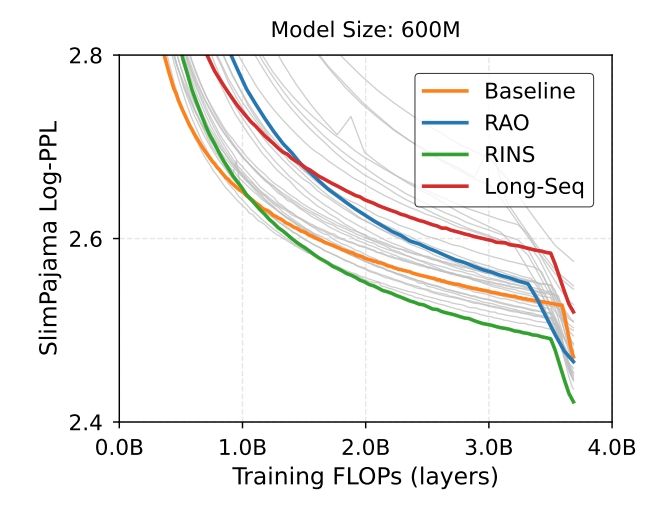
Recursion is trending (e.g. MobileLLM). But recursion adds compute / example so to show that it helps, one must match training flops; otherwise we could’ve just trained the baseline longer. With this, RINS beats +60 other recursive methods. (2/n)
12.02.2025 08:54 — 👍 1 🔁 0 💬 1 📌 0
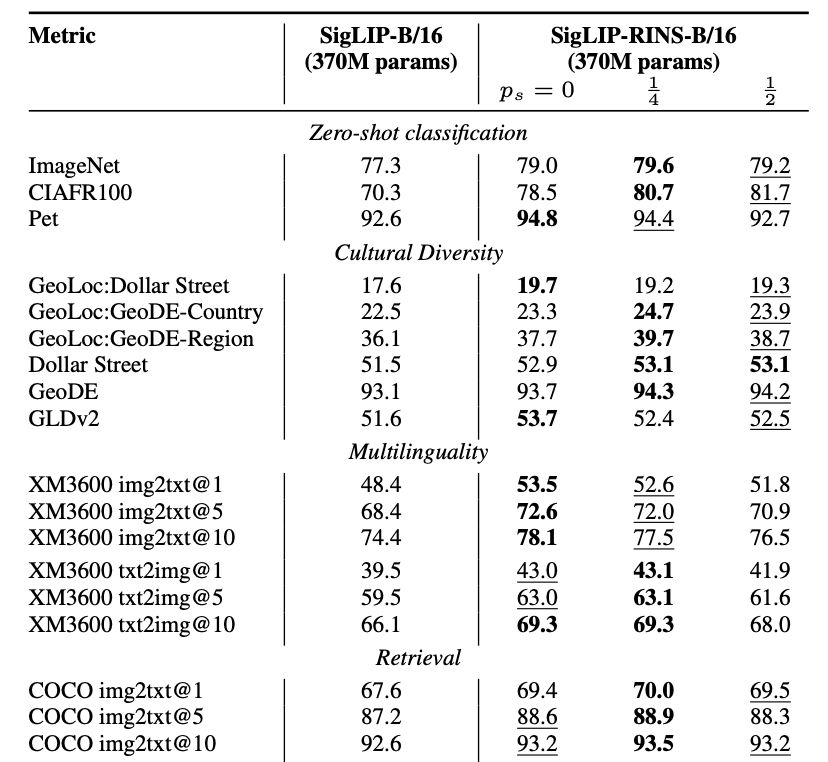
🔥Excited to introduce RINS - a technique that boosts model performance by recursively applying early layers during inference without increasing model size or training compute flops! Not only does it significantly improve LMs, but also multimodal systems like SigLIP.
(1/N)
12.02.2025 08:54 — 👍 6 🔁 2 💬 1 📌 0
Pushing live production code cooked up by some young coders over a week of sleepness nights in place of a legacy system that is fundamental to the operation of the US government is against every programming best practice.
04.02.2025 17:28 — 👍 3665 🔁 1184 💬 127 📌 130

Research Scientist, Zurich
Zurich, Switzerland
If you are interested in developing large-scale, multimodal datasets & benchmarks, and advancing AI through data-centric research, check out this great opportunity. Our team is hiring!
boards.greenhouse.io/deepmind/job...
25.01.2025 14:42 — 👍 3 🔁 3 💬 0 📌 0
x.com
Have you wondered why next-token prediction can be such a powerful training objective? Come visit our poster to talk about language and fractals and how to predict downstream performance in LLMs better.
Poster #3105, Fri 13 Dec 4:30-7:30pm
x.com/ibomohsin/st...
See you there!
07.12.2024 18:50 — 👍 2 🔁 0 💬 0 📌 0

LocCa: Visual Pretraining with Location-aware Captioners
Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area ...
Language interface is truly powerful! In LocCa, we show how simple image-captioning pretraining tasks improve localization without specialized vocabulary, while preserving holistic performance → SoTA on RefCOCO!
Poster #3602, Thu 12 Dec 4:30-7:30pm
arxiv.org/abs/2403.19596
07.12.2024 18:50 — 👍 2 🔁 0 💬 1 📌 0
x.com
1st, we present recipes for evaluating and improving cultural diversity in contrastive models, with practical, actionable insights.
Poster #3810, Wed 11 Dec 11am-2pm (2/4)
x.com/ibomohsin/st...
07.12.2024 18:50 — 👍 0 🔁 0 💬 1 📌 0
Attending #NeurIPS2024? If you're interested in multimodal systems, building inclusive & culturally aware models, and how fractals relate to LLMs, we've 3 posters for you. I look forward to presenting them on behalf of our GDM team @ Zurich & collaborators. Details below (1/4)
07.12.2024 18:50 — 👍 12 🔁 5 💬 1 📌 0
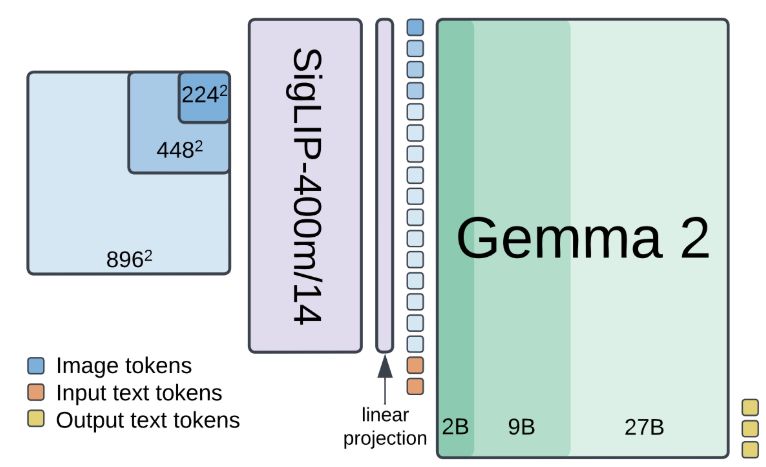
🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
05.12.2024 18:16 — 👍 69 🔁 21 💬 1 📌 5
Advancing AI & robotics by reverse engineering the neocortex.
Leveraging sensorimotor learning, structured reference frames, & cortical modularity.
Open-source research backed by Jeff Hawkins & Gates Foundation.
Explore thousandbrains.org
Research scientist at Google
Research Scientist @ Google DeepMind - working on video models for science. Worked on video generation; self-supervised learning; VLMs - 🦩; point tracking.
Computer Vision, Robotics, Machine Learning. CV/ML research engineer at Skydio. Prev. PhD in CV/Robotics at RPG in Zurich.
Director of Responsible AI @GSK | Interested in Responsible AI, AI for healthcare, fairness and causality | Prev. Google DeepMind, Google Health, UCL, Stanford, ULiege | WiML board/volunteer. She/her.
Research Scientist
Tech Lead & Manager
Google DeepMind
msajjadi.com
Waitress turned Congresswoman for the Bronx and Queens. Grassroots elected, small-dollar supported. A better world is possible.
ocasiocortez.com
Student Researcher @ Google
MSc CS @ ETH Zurich (@ethzurich.bsky.social)
Visual computing, 3D computer vision, Spatial AI, ML, and robotics perception.
📍Zurich, Switzerland
ELLIS PhD, University of Tübingen | Data-centric Vision and Language @bethgelab.bsky.social
Website: adhirajghosh.github.io
Twitter: https://x.com/adhiraj_ghosh98
The Thirty-Eighth Annual Conference on Neural Information Processing Systems will be held in Vancouver Convention Center, on Tuesday, Dec 10 through Sunday, Dec 15.
https://neurips.cc/
Research Scientist at Google. PhD from ETH Zürich. Exotic AI architectures and silicon.
👾 Zürich, Switzerland
MD. PhD. Assistant Professor @ETH Zurich. Previously @Stanford CS.
Research Scientist @Kingston University London | Computer Vision | Continual Learning | Scene Understanding | Multimodal Models | Open-Ended Learning
Writer http://jalammar.github.io. O'Reilly Author http://LLM-book.com. LLM Builder Cohere.com.




















