ooh, interesting! would the best xLSTM model to try be the xLSTM Large 7B ?
10.11.2025 15:57 — 👍 1 🔁 0 💬 1 📌 0
LLMs don't accumulate information over the course of a text the way you'd hope!
I think this is why LLMs often feel 'fixated on the wrong thing' or 'overly literal'—they are usually responding using the most relevant single thing they remember, not the aggregate of what was said
09.11.2025 20:06 — 👍 6 🔁 1 💬 0 📌 0
Thank you so much!
08.11.2025 12:10 — 👍 1 🔁 0 💬 0 📌 0
While long-context models can do many retrieval tasks impressively well, they have a long way to go to solve realistic information synthesis problems!
Oolong is joint work with Adithya Pratapa, Teruko Mitamura, @gneubig.bsky.social , and Matt Gormley.
07.11.2025 17:07 — 👍 2 🔁 1 💬 1 📌 0

Score by answer type and task type for Oolong-synth. The month+year and date types are the hardest for many models, corresponding with the difficulty of the timeline tasks.
Models show varying error patterns. Claude and some GPT-family models underperform on tasks that require outputting dates; Gemini and Deepseek-R1 frequently over-reason and fail to return an answer at all on Oolong-synth, although Gemini is the best model on Oolong-real.
07.11.2025 17:07 — 👍 0 🔁 1 💬 1 📌 0

Graph showing that the performance with labels in-context for Oolong synth is only slightly better.

Graph showing that increasing reasoning effort only helps marginally, and only in contexts shorter than 64K.
Why is this so hard? Models must identify relevant sections of input, label or categorize these sections, and then accumulate information to make distributional-level decisions. Adding labels in-context or specifying more reasoning effort has limited benefit.
07.11.2025 17:07 — 👍 2 🔁 1 💬 1 📌 0

A figure demonstrating the two splits of Oolong: the left side has the question “Were there more news articles about the economy in September or August?”, from Oolong-synth; the right side has the question “How many times in this set of episodes does the character Jester cast Healing Word?”, from Oolong-real. Both questions require the model to label sections of input, identify the important segments, and aggregate across these to answer the question.
Oolong has a synthetic setting that poses distributional questions over sets of classification examples and their metadata and a realistic setting using conversational data from game transcripts. Both splits require counting, temporal reasoning, and multi-step entity resolution.
07.11.2025 17:07 — 👍 0 🔁 0 💬 1 📌 0

Performance of a sweep of models on Oolong-synth and Oolong-real. Performance decreases with increasing context length, sometimes steeply.
Can LLMs accurately aggregate information over long, information-dense texts? Not yet…
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!
07.11.2025 17:07 — 👍 50 🔁 20 💬 3 📌 3

why intern at Ai2?
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
05.11.2025 23:11 — 👍 27 🔁 8 💬 2 📌 1

DeltaNet Explained by Sonlin Yang
A gentle and comprehensive introduction to the DeltaNet
Part 1: sustcsonglin.github.io/blog/2024/de...
Part 2: sustcsonglin.github.io/blog/2024/de...
Part 3: sustcsonglin.github.io/blog/2024/de...
05.11.2025 23:45 — 👍 15 🔁 2 💬 0 📌 0
I’ll be presenting this work in **2 hours** at EMNLP’s Gather Session 3. Come by to chat about fanfiction, literary notions of similarity, long-context modeling, and consent-focused data collection!
05.11.2025 22:01 — 👍 7 🔁 1 💬 0 📌 0

Figure showing a similarity comparison between three stories. Story A and story B have the same author, and story A and story C have the same tone. A human might care about which stories are tonally the most similar, but a language model's notion of similarity is strongly informed by surface-level features like small differences in writing style across authors.
Digital humanities researchers often care about fine-grained similarity based on narrative elements like plot or tone, which don’t necessarily correlate with surface-level textual features.
Can embedding models capture this? We study this in the context of fanfiction!
05.11.2025 21:59 — 👍 39 🔁 13 💬 1 📌 1
We'll be posting course content for anyone who would like to follow along!
The first four lecture videos are available now: youtube.com/playlist?lis...
12.09.2025 17:14 — 👍 1 🔁 0 💬 0 📌 0
11-664/763 LM Inference
A class at Carnegie Mellon University on language model inference algorithms.
. @gneubig.bsky.social and I are co-teaching a new class on LM inference this fall!
We designed this class to give a broad view on the space, from more classical decoding algorithms to recent methods for LLMs, plus a wide range of efficiency-focused work.
website: phontron.com/class/lminfe...
12.09.2025 17:14 — 👍 4 🔁 0 💬 1 📌 0
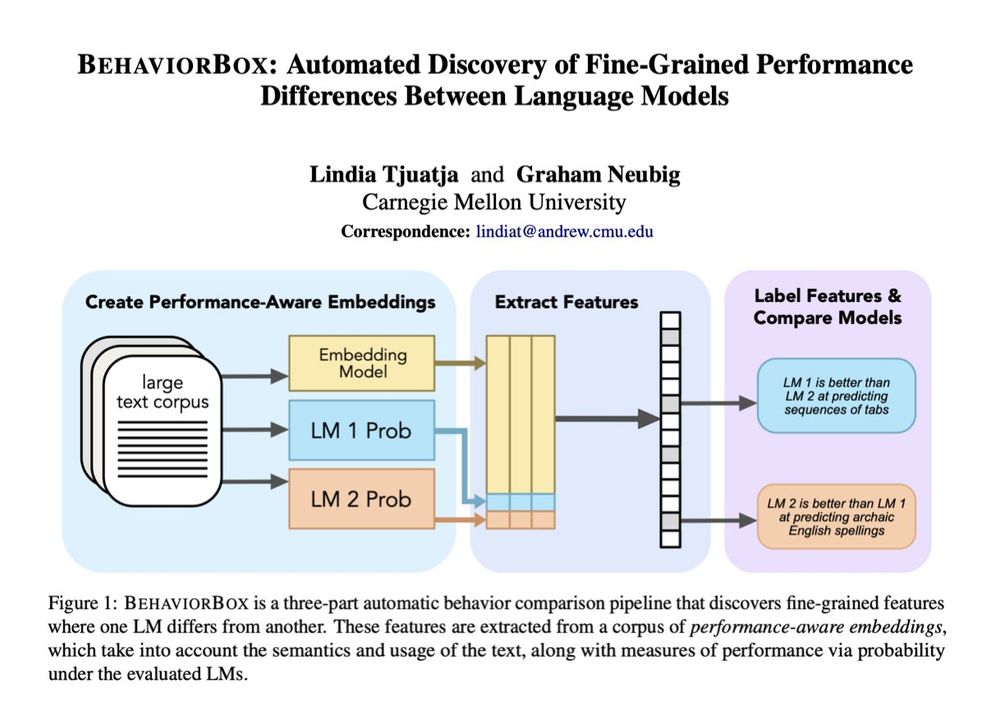
When it comes to text prediction, where does one LM outperform another? If you've ever worked on LM evals, you know this question is a lot more complex than it seems. In our new #acl2025 paper, we developed a method to find fine-grained differences between LMs:
🧵1/9
09.06.2025 13:47 — 👍 72 🔁 21 💬 2 📌 2
we also have a followup work, and @emilyxiao.bsky.social will also be around the conference to discuss! bsky.app/profile/emil...
30.04.2025 00:06 — 👍 0 🔁 0 💬 0 📌 0
super excited to see folks at #NAACL25 this week! I'll be presenting our work on long-context ICL Wednesday in the 2pm poster session in Hall 3-- would love to chat with folks there or at the rest of the conference about long context data, ICL, inference time methods, New Mexican food, etc :)
30.04.2025 00:03 — 👍 11 🔁 1 💬 1 📌 0

Image of the first page of the CHI 2025 paper titled "A Taxonomy of Linguistic Expressions That Contribute To Anthropomorphism of Language Technologies" by authors Alicia DeVrio, Myra Cheng, Lisa Egede, Alexandra Olteanu, & Su Lin Blodgett
How can we better think and talk about human-like qualities attributed to language technologies like LLMs? In our #CHI2025 paper, we taxonomize how text outputs from cases of user interactions with language technologies can contribute to anthropomorphism. arxiv.org/abs/2502.09870 1/n
06.03.2025 03:43 — 👍 43 🔁 11 💬 2 📌 3

The Learning Dynamics of a PhD
This is what a PhD looks like: 9.6 million seconds of research.
9.6 million seconds = 1 PhD 🔥
Finally analyzed my PhD time tracking data so you can plan your own research journey more effectively: mxij.me/x/phd-learning-dynamics
For current students: I hope this helps put your journey into perspective. Wishing you all the best!
23.12.2024 22:08 — 👍 36 🔁 7 💬 0 📌 1

The abstract of a paper titled "Basic Research, Lethal Effects: Military AI Research Funding as Enlistment".
In the context of unprecedented U.S. Department of Defense (DoD) budgets, this paper examines the recent history of DoD funding for academic research in algorithmically based warfighting. We draw from a corpus of DoD grant solicitations from 2007 to 2023, focusing on those addressed to researchers in the field of artificial intelligence (AI). Considering the implications of DoD funding for academic research, the paper proceeds through three analytic sections. In the first, we offer a critical examination of the distinction between basic and applied research, showing how funding calls framed as basic research nonetheless enlist researchers in a war fighting agenda. In the second, we offer a diachronic analysis of the corpus, showing how a 'one small problem' caveat, in which affirmation of progress in military technologies is qualified by acknowledgement of outstanding problems, becomes justification for additional investments in research. We close with an analysis of DoD aspirations based on a subset of Defense Advanced Research Projects Agency (DARPA) grant solicitations for the use of AI in battlefield applications. Taken together, we argue that grant solicitations work as a vehicle for the mutual enlistment of DoD funding agencies and the academic AI research community in setting research agendas. The trope of basic research in this context offers shelter from significant moral questions that military applications of one's research would raise, by obscuring the connections that implicate researchers in U.S. militarism.
When I started on ARL project that funds my PhD, the thing we were supposed to build was a "MaterialsGPT".
What is a MaterialsGPT? Where does that idea come from? I got to spend a lot of time thinking about that second question with @davidthewid.bsky.social and Lucy Suchman (!) working on this:
17.12.2024 14:33 — 👍 20 🔁 7 💬 1 📌 0

Basic Research, Lethal Effects: Military AI Research Funding as Enlistment David Gray Widder Digital Life Initiative, Cornell University Sireesh Gururaja School of Computer Science, Carnegie Mellon University Lucy Suchman Department of Sociology, Lancaster University Abstract In the context of unprecedented U.S. Department of Defense (DoD) budgets, this paper examines the recent history of DoD funding for academic research in algorithmically based warfighting. We draw from a corpus of DoD grant solicitations from 2007 to 2023, focusing on those addressed to researchers in the field of artificial intelligence (AI). Considering the implications of DoD funding for academic research, the paper proceeds through three analytic sections. In the first, we offer a critical examination of the distinction between basic and applied research, showing how funding calls framed as basic research nonetheless enlist researchers in a war fighting agenda. In the second, we offer a diachronic analysis of the corpus, showing how a ‘one small problem’ caveat, in which affirmation of progress in military technologies is qualified by acknowledgement of outstanding problems, becomes justification for additional investments in research. We close with an analysis of DoD aspirations based on a subset of Defense Advanced Research Projects Agency (DARPA) grant solicitations for the use of AI in battlefield applications. Taken together, we argue that grant solicitations work as a vehicle for the mutual enlistment of DoD funding agencies and the academic AI research community in setting research agendas. The trope of basic research in this context offers shelter from significant moral questions that military applications of one’s research would raise, by obscuring the connections that implicate researchers in U.S. militarism. Keywords: artificial intelligence; US Department of Defense; military; funding; investment, war
📢 NEW Paper!
@siree.sh, Lucy Suchman, and I examine a corpus of 7,000 US Military grant solicitations to ask what the world’s largest military wants with to do with AI, by looking at what it seeks to fund. #STS
📄: arxiv.org/pdf/2411.17840
We find…
09.12.2024 14:18 — 👍 66 🔁 32 💬 4 📌 4
I think @siree.sh was also looking at this! No marker of arxiv category in the url, unfortunately :/
25.11.2024 14:18 — 👍 3 🔁 0 💬 1 📌 0
and just realized this post is a full two weeks old but! bsky showed it to me now 🥲
25.11.2024 07:17 — 👍 1 🔁 0 💬 1 📌 0
if the j*b m*rket takes you anywhere in a mining or old industrial area (incl most of the east coast), soil test before planting a garden in the ground! most universities will let you mail them like $30 and a bag of dirt to check it for lead and arsenic
25.11.2024 07:15 — 👍 5 🔁 0 💬 2 📌 0
when you try to convert your text into smaller pieces but all it gives you is Elvish, that’s a tolkienizer
20.11.2024 17:50 — 👍 1011 🔁 104 💬 35 📌 17
That’s right. You might think that all successful CS academics are good at running. But that’s only because the ones who weren’t, have been eaten by bears.
21.11.2024 00:45 — 👍 80 🔁 4 💬 5 📌 0
if we put our models through training runs, I think it's only fair that we do the same
21.11.2024 01:16 — 👍 18 🔁 0 💬 1 📌 0

Screenshot of the paper title "What Goes Into a LM Acceptability Judgment? Rethinking the Impact of Frequency and Length"
💬 Have you or a loved one compared LM probabilities to human linguistic acceptability judgments? You may be overcompensating for the effect of frequency and length!
🌟 In our new paper, we rethink how we should be controlling for these factors 🧵:
20.11.2024 18:07 — 👍 84 🔁 19 💬 1 📌 4
Post-doc @UC Louvain
https://aurelien-goutsmedt.com
History macro, inflation, econ policy & energy since the 70s
#Political_Economy #Central_Banks
#Rstats #nlp #networks #bibliometrics
Managing editor journals.openedition.org/oeconomia
PhD Candidate in Natural Language Processing @unistra.fr; working on LLM gender bias mitigation.
Localization Specialist (EN → FR).
Interested in research; politics; technology; languages; literature; philosophy.
Website: https://edoyen.com/
Views my own.
Animateur, journaliste, auteur: quotidienne Moteur de recherche, Ici Première, 19h-20h; paru le 8 octobre «Moteur de recherche, le livre» https://editionslapresse.ca/collections/sorties-recentes/products/moteur-de-recherche-le-livre
Breakthrough AI to solve the world's biggest problems.
› Join us: http://allenai.org/careers
› Get our newsletter: https://share.hsforms.com/1uJkWs5aDRHWhiky3aHooIg3ioxm
Associate Professor @ UW
Computational Social Science
Assistant Professor @ UChicago CS & DSI UChicao
Leading Conceptualization Lab http://conceptualization.ai
Minting new vocabulary to conceptualize generative models.
PhD student @ltiatcmu.bsky.social. he/him
researching AI [evaluation, governance, accountability]
Using computers to better understand languages, texts, and music.
Web, Python, ML, DH, Corpus Linguistics, Computational Literary Studies, Data Visualization, Philology, Ancient Greek, Music Theory, Tolkien, Space.
PhD candidate @dhssfau.bsky.social
Cultural Analytics and NLP researcher
A business analyst at heart who enjoys delving into AI, ML, data engineering, data science, data analytics, and modeling. My views are my own.
You can also find me at threads: @sung.kim.mw
PhD student @mainlp.bsky.social (@cislmu.bsky.social, LMU Munich). Interested in language variation & change, currently working on NLP for dialects and low-resource languages.
verenablaschke.github.io
The image that I run from
Only seems to follow me
Assist. Prof at CMU, CS PhD at UW. HCI+AI, map general-purpose models to specific use cases!
I develop tough benchmarks for LMs and then I build agents to try and beat those benchmarks. Postdoc @ Princeton University.
https://ofir.io/about
LLM post-training, reasoning, and multimodality. Ph.D. @ JHU CLSP, incoming researcher at Microsoft Copilot Tuning. #NLProc
https://katesanders9.github.io/
Applied Scientist @ Amazon
(Posts are my own opinion)
Previously PhD@JHU
PhD student at Johns Hopkins University
Alumni from McGill University & MILA
Working on NLP Evaluation, Responsible AI, Human-AI interaction
she/her 🇨🇦






















