This was accepted to #NeurIPS 🎉🎊
TL;DR Impoverished notions of rigor can have a formative impact on AI work. We argue for a broader conception of what rigorous work should entail & go beyond methodological issues to include epistemic, normative, conceptual, reporting & interpretative considerations
29.09.2025 23:13 — 👍 25 🔁 8 💬 1 📌 1

Dr. Su Lin Blodgett and Dr. Gagan Bansal will be the keynote speakers of the 2nd HEAL workshop @CHI25
We are excited to kick off the 2nd HEAL workshop tomorrow at #CHI2025. Dr. Su Lin Blodgett and Dr. Gagan Bansal from MSR will be our keynote speakers!
Welcome new and old friends! See you at G221!
All accepted papers: tinyurl.com/bdfpjcr4
25.04.2025 11:28 — 👍 6 🔁 2 💬 0 📌 0
😅
03.04.2025 13:29 — 👍 1 🔁 0 💬 0 📌 0


Bringing together our incredible current and admitted students—future leaders, innovators, and changemakers!
07.03.2025 05:15 — 👍 7 🔁 2 💬 0 📌 0
📣 DEADLINE EXTENSION 📣
By popular request, HEAL workshop submission deadline is extended to Feb 24 AOE!
Reminder that we welcome a wide range of submissions: position papers, lit reviews, encore of published work, etc.
Looking forward to your submissions!
13.02.2025 22:05 — 👍 4 🔁 0 💬 0 📌 0
The submission deadline is in less than a month! We welcome encore submissions, so consider submitting your work regardless of whether it's been accepted or not #chi2025 😉
22.01.2025 15:32 — 👍 8 🔁 1 💬 0 📌 0
An awesome team of organizers: @wesleydeng.bsky.social, @mlam.bsky.social, @juhokim.bsky.social, @qveraliao.bsky.social, @cocoweixu.bsky.social, @ziangxiao.bsky.social, Motahhare Eslami, and Jekaterina Novikova!
16.12.2024 22:07 — 👍 7 🔁 0 💬 0 📌 1

The image includes a shortened call for participation that reads:
"We welcome participants who work on topics related to supporting human-centered evaluation and auditing of language models. Topics of interest include, but not limited to:
- Empirical understanding of stakeholders' needs and goals of LLM evaluation and auditing
- Human-centered evaluation and auditing methods for LLMs
- Tools, processes, and guidelines for LLM evaluation and auditing
- Discussion of regulatory measures and public policies for LLM auditing
- Ethics in LLM evaluation and auditing
Special Theme: Mind the Context. We invite authors to engage with specific contexts in LLM evaluation and auditing. This theme could involve various topics: the usage contexts of LLMs, the context of the evaluation/auditing itself, and more! The term ''context'' is purposefully left open for interpretation!
The image also includes pictures of workshop organizers, who are: Yu Lu Liu, Wesley Hanwen Deng, Michelle S. Lam, Motahhare Eslami, Juho Kim, Q. Vera Liao, Wei Xu, Jekaterina Novikova, and Ziang Xiao.
Human-centered Evalulation and Auditing of Language models (HEAL) workshop is back for #CHI2025, with this year's special theme: “Mind the Context”! Come join us on this bridge between #HCI and #NLProc!
Workshop submission deadline: Feb 17 AoE
More info at heal-workshop.github.io.
16.12.2024 22:07 — 👍 44 🔁 10 💬 2 📌 4
Super excited to announce that @msftresearch.bsky.social's FATE group, Sociotechnical Alignment Center, and friends have several workshop papers at next week's @neuripsconf.bsky.social. A short thread about (some of) these papers below... #NeurIPS2024
02.12.2024 23:01 — 👍 58 🔁 13 💬 1 📌 0
📣 📣 Interested in an internship on human-centred AI, human agency, AI evaluation & the impacts of AI systems? Our team/FATE MLT (Su Lin Blodgett, @qveraliao.bsky.social & I) is looking for a few summer interns 🎉 Apply by Jan 10 for full consideration: jobs.careers.microsoft.com/global/en/jo...
05.12.2024 20:11 — 👍 22 🔁 10 💬 0 📌 2
I am collecting examples of the most thoughtful writing about generative AI published in 2024. What’s yours? They can be insightful for commentary, smart critique, or just because it shifted the conversation. I’ll post some of mine below as I go through them. #criticalAI
02.12.2024 04:09 — 👍 353 🔁 118 💬 98 📌 19
Created a small starter pack including folks whose work I believe contributes to more rigorous and grounded AI research -- I'll grow this slowly and likely move it to a list at some point :) go.bsky.app/P86UbQw
30.11.2024 19:58 — 👍 12 🔁 5 💬 1 📌 0
Added!
28.11.2024 15:29 — 👍 1 🔁 0 💬 0 📌 0
Hi, so I've spent the past almost-decade studying research uses of public social media data, like e.g. ML researchers using content from Twitter, Reddit, and Mastodon.
Anyway, buckle up this is about to be a VERY long thread with lots of thoughts and links to papers. 🧵
27.11.2024 15:33 — 👍 966 🔁 453 💬 59 📌 125
Added!
27.11.2024 01:29 — 👍 1 🔁 0 💬 0 📌 0
Human-Centered Eval@EMNLP24
Had a lot of fun teaching a tutorial on Human-Centered Evaluation of Language Technologies at #EMNLP2024, w/ @ziangxiao.bsky.social, Su Lin Blodgett, and Jackie Cheung
We just posted the slides on our tutorial website: human-centered-eval.github.io
26.11.2024 20:55 — 👍 13 🔁 3 💬 0 📌 0
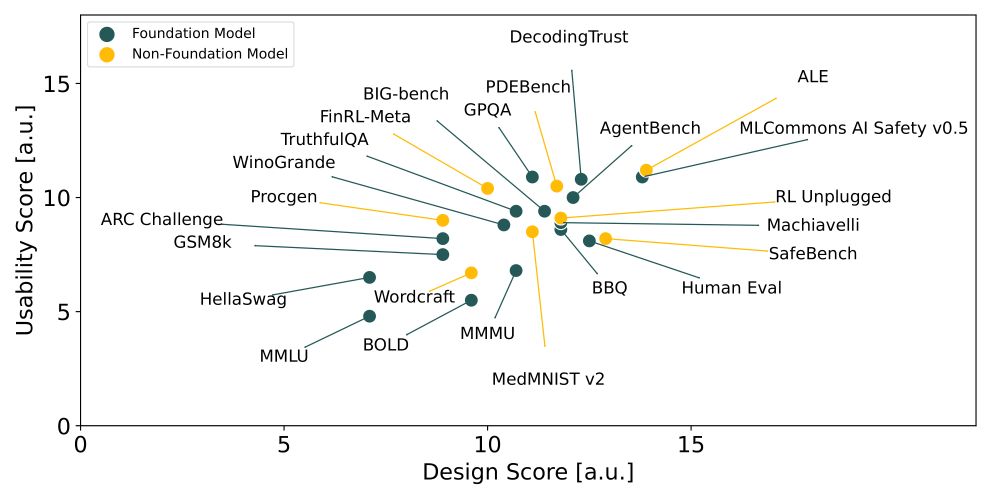
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
25.11.2024 19:02 — 👍 139 🔁 25 💬 5 📌 7
It turns out we had even more papers at EMNLP!
Let's complete the list with three more🧵
24.11.2024 02:17 — 👍 14 🔁 4 💬 1 📌 1
Our lab members recently presented 3 papers at @emnlpmeeting.bsky.social in Miami ☀️ 📜
From interpretability to bias/fairness and cultural understanding -> 🧵
23.11.2024 20:35 — 👍 19 🔁 6 💬 1 📌 2
Added!
23.11.2024 22:06 — 👍 1 🔁 0 💬 0 📌 0
Added!
23.11.2024 16:27 — 👍 0 🔁 0 💬 0 📌 0
Added!
23.11.2024 15:44 — 👍 1 🔁 0 💬 0 📌 0
Added!
23.11.2024 13:49 — 👍 1 🔁 0 💬 1 📌 0

tiny owl
my first post, now that I am here with my 500+ closest friends 🙂 -- here is a tiny owl 🦉 I met some weeks back in the big apple 🍎 (picture by @sbucur.bsky.social)
22.11.2024 23:19 — 👍 11 🔁 1 💬 0 📌 0
Added!
23.11.2024 01:44 — 👍 1 🔁 0 💬 0 📌 0
McGill NLP just landed on this blue planet
bsky.app/profile/mcgi...
22.11.2024 17:17 — 👍 8 🔁 2 💬 0 📌 0
The starter pack just surpassed 1/3 of its capacity! Don't be shy to reach out to me if you are a researcher in this area, or if you have suggestions. Thank you 🥰
23.11.2024 01:10 — 👍 6 🔁 0 💬 0 📌 0
VP and Distinguished Scientist at Microsoft Research NYC. AI evaluation and measurement, responsible AI, computational social science, machine learning. She/her.
One photo a day since January 2018: https://www.instagram.com/logisticaggression/
Postdoc researcher @MicrosoftResearch, previously @TUDelft.
Interested in the intricacies of AI production and their social and political economical impacts; gap policies-practices (AI fairness, explainability, transparency, assessments)
AI/ML Applied Research Intern at Adobe | NLP-ing (Research Masters) at MILA/McGill
MSc Master's @mila-quebec.bsky.social @mcgill-nlp.bsky.social
Research Fellow @ RBC Borealis
Model analysis, interpretability, reasoning and hallucination
Studying model behaviours to make them better :))
Looking for Fall '26 PhD
PhD Student @ University of Toronto DGP Lab | HCI Research | Prev. Tsinghua University | lepingqiu.com
Ph.D student in Digital Media at Georgia Tech | HCI & STS | inhacha.info | She/her
phding@mcgill, words@reboot, translator@limited connection, forecast.weather.gov stan
shiraab.github.io
Books:
https://asterismbooks.com/product/the-hand-of-the-hand-laura-vazquez
https://www.arche-editeur.com/livre/le-reve-dun-langage-commun-747
Assistant Professor @Mila-Quebec.bsky.social
Co-Director @McGill-NLP.bsky.social
Researcher @ServiceNow.bsky.social
Alumni: @StanfordNLP.bsky.social, EdinburghNLP
Natural Language Processor #NLProc
Research scientist at Amazon. I studied at Mila during my Ph.D. and focused on understanding why AI discriminates based on gender and race; and how to measure/fix that.
PhDing @ MILA/McGill in Computer Science | Multi-agent systems, emergent organization, and neurosymbolic methods
Previously @ UWaterloo
Also love guitar/bass, volleyball, history, cycling, and institutional design
International non-profit org democratizing AI ethics literacy.
✉️ Join 20K+ readers and get the AI Ethics Brief delivered to your inbox bi-weekly: http://brief.montrealethics.ai
Responsible AI & Human-AI Interaction
Currently: Research Scientist at Apple
Previously: Princeton CS PhD, Yale S&DS BSc, MSR FATE & TTIC Intern
https://sunniesuhyoung.github.io/
I write mostly about the intersection of tech & art/culture which these days means I spend nearly all my time trying to address the exploitation underlying current AI models. A secular humanist interrogating modern religions.
Common Cyborg | NB ND Mad Bean | Disability and Epistemology | Research Ethics and Dissensus
Assistant Professor in Interaction Design at KTH | Feminisms + HCI + Critical computing | She/Her | Latin American 💚🧡
Transitional Assistant Professor at University of Nottingham, UK.
Human-Computer, Human-Robot, Human-AI Interaction research.
Mexican. She/her.
Part of TAS Hub (https://tas.ac.uk/) and RAi UK (https://rai.ac.uk/)
Views my own.
reyescruz.com
Head of Student Programs, @scholarslab. DH, pedagogy, sound studies, text analysis. Editorial board @JITpedagogy. More info at walshbr.com
#nlp researcher interested in evaluation including: multilingual models, long-form input/output, processing/generation of creative texts
previous: postdoc @ umass_nlp
phd from utokyo
https://marzenakrp.github.io/





















