
UW News put out a Q&A about our recent work on Variational Preference Learning, a technique for personalizing Reinforcement Learning from Human Feedback (RLHF) washington.edu/news/2024/12...
18.12.2024 21:51 — 👍 30 🔁 8 💬 1 📌 0
@abhishekunique7.bsky.social
Assistant Professor, Paul G. Allen School of Computer Science and Engineering, University of Washington Visiting Faculty, NVIDIA Ph.D. from Berkeley, Postdoc MIT https://homes.cs.washington.edu/~abhgupta I like robots and reinforcement learning :)
UW News put out a Q&A about our recent work on Variational Preference Learning, a technique for personalizing Reinforcement Learning from Human Feedback (RLHF) washington.edu/news/2024/12...
18.12.2024 21:51 — 👍 30 🔁 8 💬 1 📌 0
The key insight is - if you’re going to transfer from sim-to-real, be careful about transferring exploration behavior rather than just policies.Take a look at our paper: arxiv.org/abs/2410.20254. Fun collaboration with Andrew Wagenmaker, Kevin Huang, Kay Ke, Byron Boots, @kjamieson.bsky.social(6/6)
06.12.2024 00:46 — 👍 1 🔁 0 💬 0 📌 0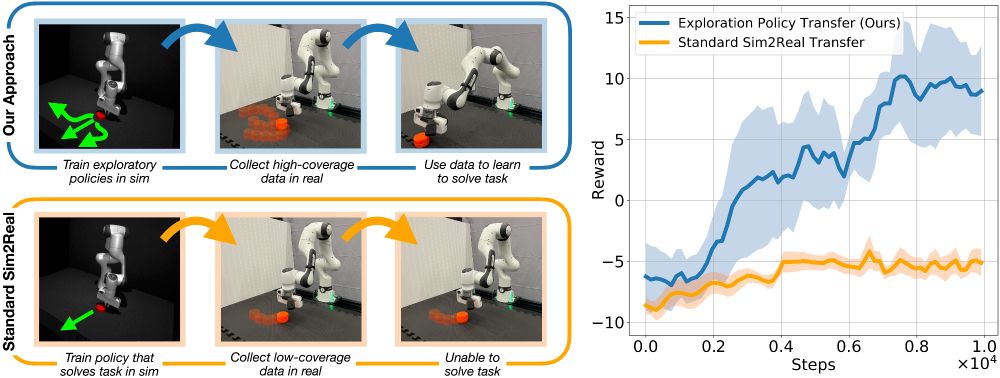
Given these insights,we develop a practical instantiation using a diversity driven policy learning algorithm in sim. This learns diverse exploration in the neighborhood of an optimal policy. Exploring using this policy learned in sim can then enable efficient policy learning in the real world (5/6)
06.12.2024 00:46 — 👍 1 🔁 0 💬 1 📌 0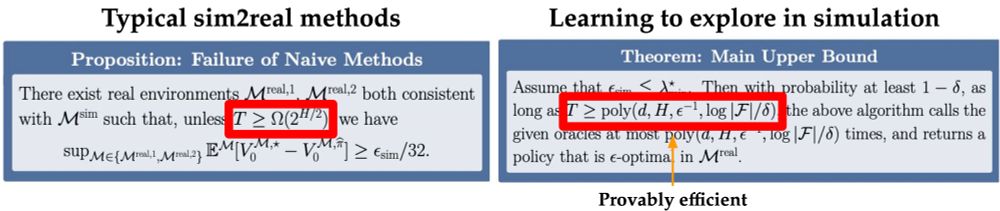
We show that exploration policies learned in sim can be played in the real world to collect data, performing policy improvement with RL. These policies cannot be naively played but must be combined with some degree of random exploration. However, this exploration is now provably efficient! (4/6)
06.12.2024 00:46 — 👍 0 🔁 0 💬 1 📌 0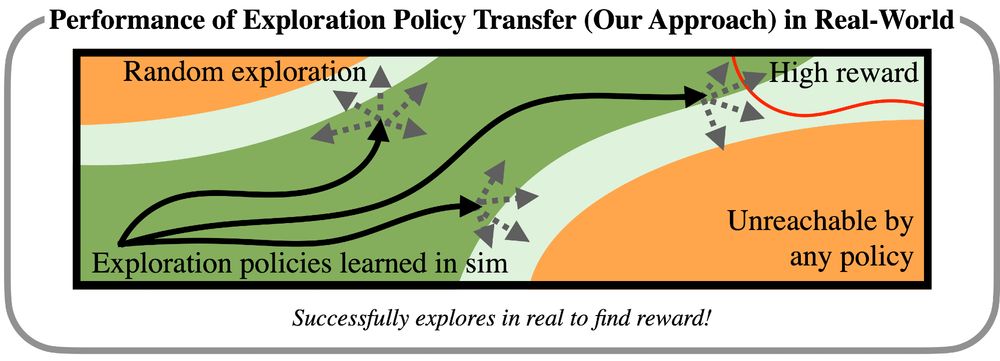
We propose a simple fix - instead of learning *optimal* policies in sim, learn exploratory policies in sim. Since data collection in sim is cheap, we learn exploratory policies that have broad coverage. Even with domain gap, exploratory policies in sim can explore in the real world. (3/6)
06.12.2024 00:46 — 👍 0 🔁 0 💬 1 📌 0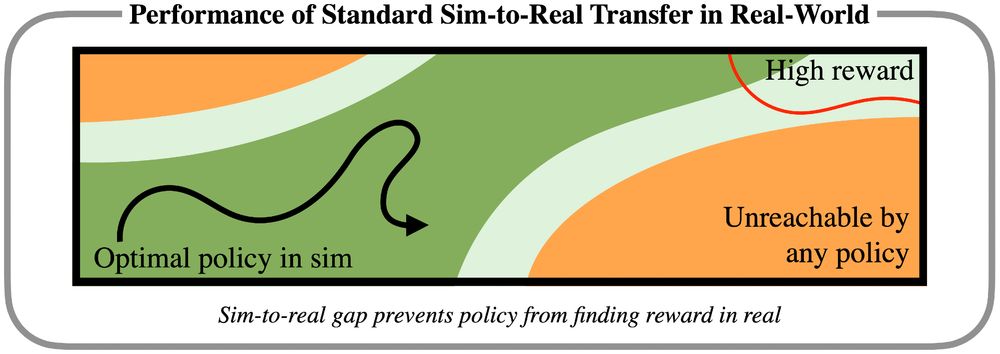
The typical paradigm for sim2real transfers a policy and hopes for few-shot finetuning with naive exploration. First, we show that there exist envs where this can be exponentially inefficient. An overconfident, wrong policy in an incorrect sim can lead to poor real-world exploration (2/6)
06.12.2024 00:46 — 👍 0 🔁 0 💬 1 📌 0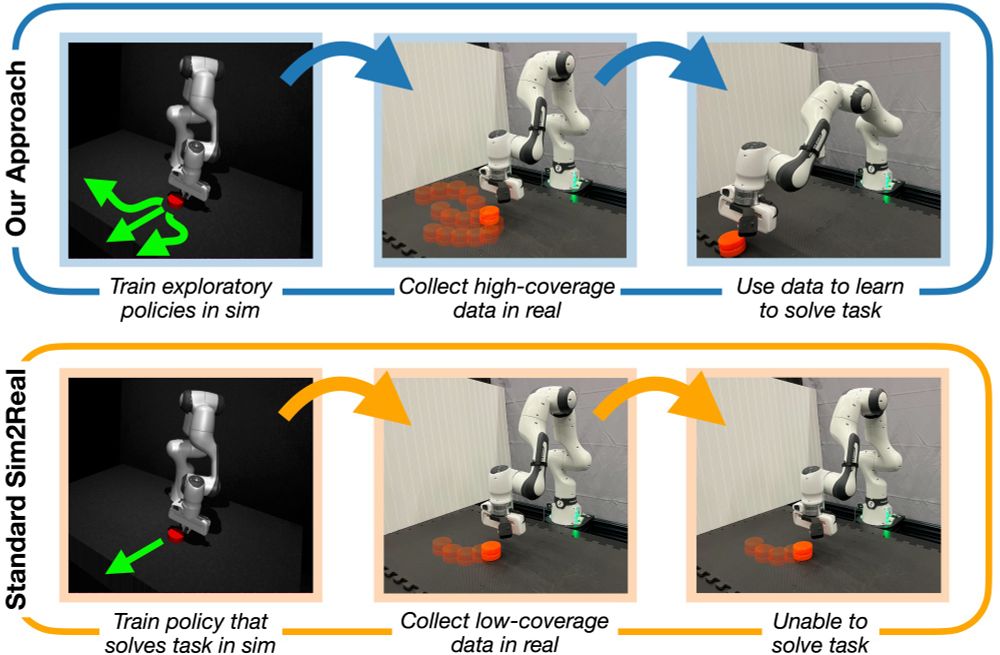
We’ve been investigating how sim, while wrong, can be useful for real-world robotic RL! In our #NeurIPS2024 work, we theoretically showed how naive sim2real transfer can be inefficient, but if you *learn to explore* in sim, this transfers to the real world! We show this works on real robots! 🧵(1/6)
06.12.2024 00:46 — 👍 13 🔁 5 💬 2 📌 0
I’m excited about the doors this opens for generalizable robot pre-training!
Paper: arxiv.org/abs/2412.01770
Website: casher-robot-learning.github.io/CASHER/
Fun project w/ @marcelto.bsky.social , @arhanjain.bsky.social , Carrie Yuan, Macha V, @ankile.bsky.social, Anthony S, Pulkit Agrawal :)
I’m also a sucker for a fun website. Check out our interactive demo where you can see some of the environments and learned behaviors. We’ve also open sourced USDZ assets of the sourced environments. (8/N)
05.12.2024 02:12 — 👍 0 🔁 0 💬 1 📌 0Why do I care - we’re going to have to consider off-domain data for robotics, and realistic simulation constructed cheaply from video provides a scalable way to source this data. Building methods that scale sublinearly with human effort make this practical, and generalizable. (7/N)
05.12.2024 02:12 — 👍 1 🔁 0 💬 1 📌 0Step 5: One neat feature is that in a test environment, human demos aren’t even required. Scan in an environment video to build a test-time simulation and let the generalist model provide itself demos and improve with RL in sim. Results in over 50% improvement with 0 human effort (6/N)
05.12.2024 02:12 — 👍 0 🔁 0 💬 1 📌 0Step 4: Transfer over to the real world, either zero-shot or with some co-training. Shows scaling laws as more experience is encountered, and robust performance across distractors, object positions, visual conditions and disturbances. (5/N)
05.12.2024 02:12 — 👍 0 🔁 0 💬 1 📌 0Step 3: Providing even 10 demos per env is still expensive. By training generalists from RL data, we get cross-environment generalization that allows the model to provide *itself* demos and only use human effort when necessary. The better the generalist gets, the less human effort is required. (4/N)
05.12.2024 02:12 — 👍 0 🔁 0 💬 1 📌 0Step 2: Train policies on these environments with demo-bootstrapped RL. A couple of demos are needed to guide exploration, but the heavy lifting is done with large scale RL in simulation . This takes success rates from 2-3% to >90% success from <10 human demos. (3/N)
05.12.2024 02:12 — 👍 0 🔁 0 💬 1 📌 0Step 1: Collect lots of environments with video scans - anyone can do it with their phone. I even had my parents scan in a bunch :) use 3D reconstruction methods like Gaussian splats to make diverse, visually & geometrically realistic sim environments for training policies (2/N)
05.12.2024 02:12 — 👍 0 🔁 0 💬 1 📌 0I'm excited about scaling up robot learning! We’ve been scaling up data gen with RL in realistic sims generated from crowdsourced videos. Enables data collection far more cheaply than real world teleop. Importantly, data becomes *cheaper* with more environments and transfers to real robots! 🧵 (1/N)
05.12.2024 02:12 — 👍 21 🔁 11 💬 3 📌 0

























