
I'll be defending my dissertation at NYU next Monday, June 16 at 4pm ET!
I've definitely missed inviting some people who might be interested, so please email me if you'd like to attend (NYC or Zoom)

@lambdaviking.bsky.social
Will irl - PhD student @ NYU on the academic job market! Using complexity theory and formal languages to understand the power and limits of LLMs https://lambdaviking.com/ https://github.com/viking-sudo-rm
I'll be defending my dissertation at NYU next Monday, June 16 at 4pm ET!
I've definitely missed inviting some people who might be interested, so please email me if you'd like to attend (NYC or Zoom)

As we’ve been working towards training a new version of OLMo, we wanted to improve our methods for measuring the Critical Batch Size (CBS) of a training run, to unlock greater efficiency. but we found gaps between the methods in the literature and our practical needs for training OLMo. 🧵
03.06.2025 16:43 — 👍 16 🔁 3 💬 1 📌 1📜Paper link: arxiv.org/pdf/2503.03961
07.03.2025 16:46 — 👍 0 🔁 0 💬 0 📌 0
We take these results to justify further theoretical and empirical analysis of dynamic depth as a form of test-time computation for transformers
(we’re excited to share more results ourselves soon🤐)
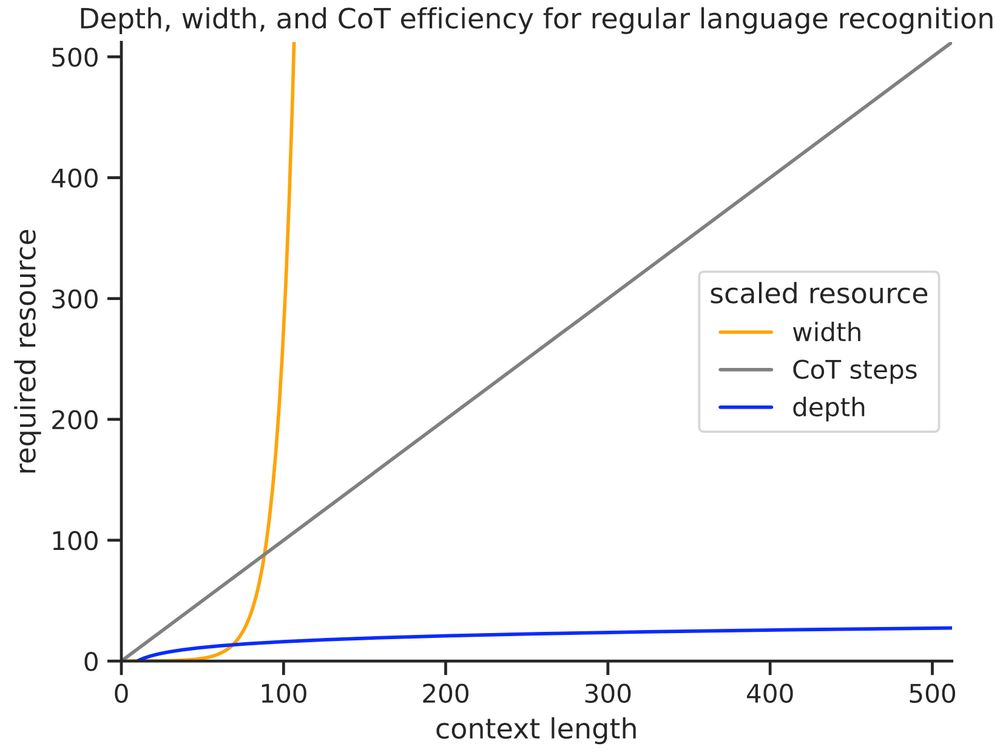
Our results suggest dynamic depth can be a more efficient form of test-time compute than chain of thought (at least for reg languages). While CoT would use ~n steps to recognize regular languages to length n, looped transformers only need ~log n depth
07.03.2025 16:46 — 👍 0 🔁 0 💬 1 📌 0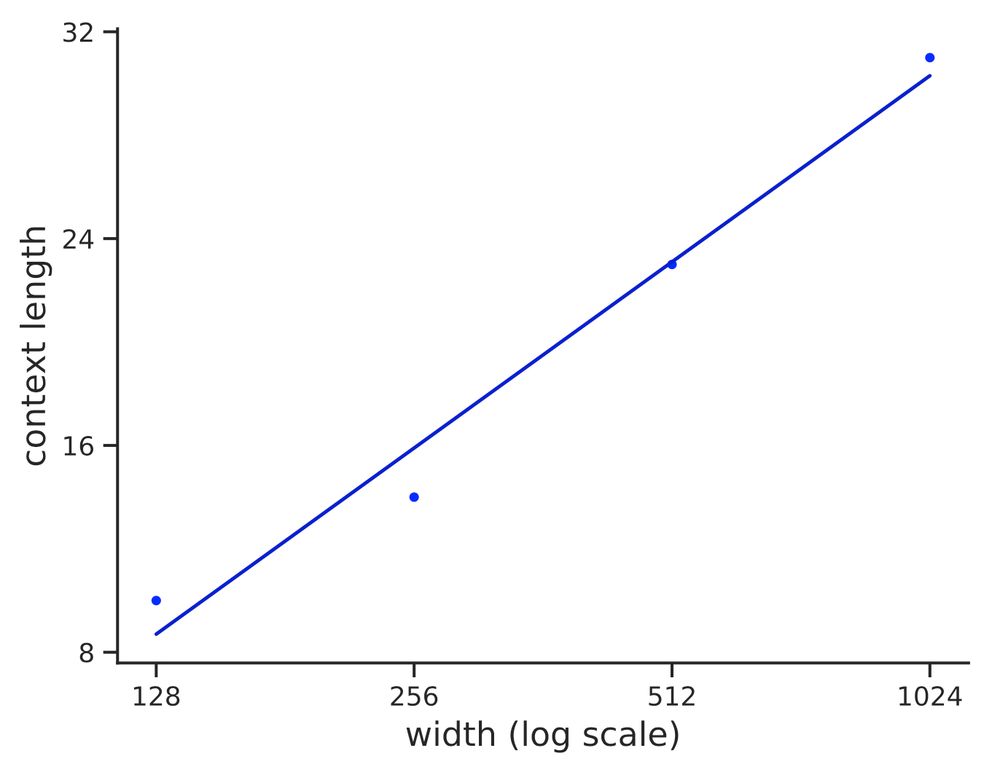
Graph showing log width is linear in context length (i.e., width is exponential)
In contrast, both in theory and practice, width must grow exponentially with sequence length to enable regular language recognition. Thus, while slightly increasing depth expands expressive power, increasing width to gain power is intractable!
07.03.2025 16:46 — 👍 1 🔁 0 💬 1 📌 0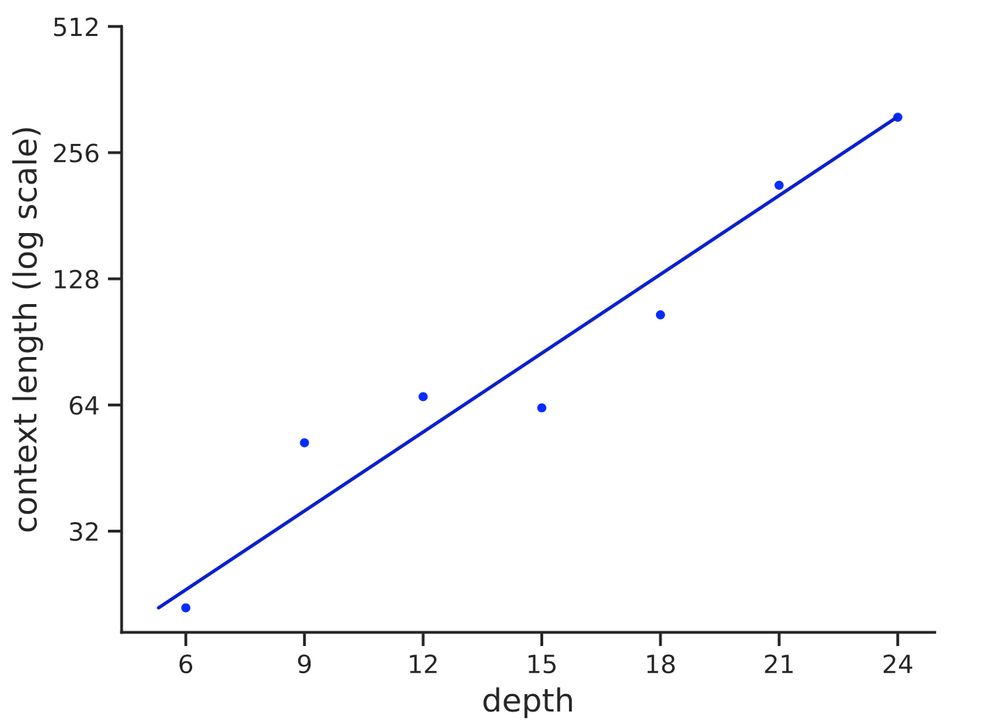
Graph showing depth is linear in log context length
In practice, can transformers learn to solve these problems with log depth?
We find the depth required to recognize strings of length n grows ~ log n with r^2=.93. Thus, log depth appears necessary and sufficient to recognize reg languages in practice, matching our theory
They are! We show that log-depth transformers can express two key problems that fixed-depth transformers provably cannot:
♟️State tracking (regular languages)
🔍Graph search (connectivity)
We address both these questions by studying the expressive power of looped transformers w/ log depth. On input length n, a block of layers can be repeated log n times (with shared weights across blocks)
🤔Are log-depth transformers more powerful than fixed-depth transformers?
Past work has shown that the bounded depth of transformers provably limits their ability to express sequential reasoning, particularly on long inputs.
But what if we only care about reasoning over short inputs? Or if the transformer’s depth can grow 🤏slightly with input length?
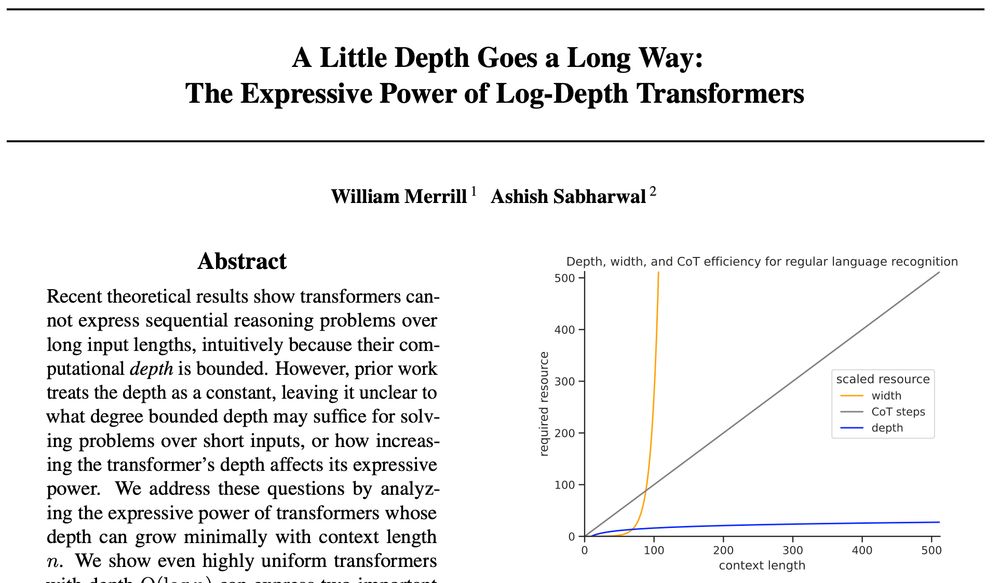
Paper: A Little Depth Goes a Long Way: The Expressive Power of Log-Depth Transformers
✨How does the depth of a transformer affect its reasoning capabilities? New preprint by myself and @Ashish_S_AI shows that a little depth goes a long way to increase transformers’ expressive power
We take this as encouraging for further research on looped transformers!🧵

A book with a six-fingered hand (designed by Josh MacPhee), titled "Why We Fear AI: On the Interpretation of Nightmares"

Wow, authors' copies have just arrived! So cool (and kinda strange lol) to see our work in print!
Amazing job from @commonnotions.bsky.social! Love the cover design from Josh MacPhee <3
Get a copy here:
www.commonnotions.org/why-we-fear-ai
Excited to announce that the (stellar!) program for NASSLLI is out now: nasslli25.shane.st
Further details on registration and whatnot to follow in the coming weeks. Please do circulate to anyone you know who may be interested in attending!
This is a call to action. The vast majority of us are furious that our constitution is being blatantly violated at the highest levels of government. Here’s a simple way to use your voice - all you need is tape and access to a printer:
08.02.2025 18:56 — 👍 2 🔁 2 💬 1 📌 0I try to! (And usually do eventually, on trains or planes)
30.11.2024 13:45 — 👍 1 🔁 0 💬 0 📌 0Looks cool, added to my reading list!
29.11.2024 18:10 — 👍 1 🔁 0 💬 1 📌 0Agreed (and defer to you), but I thought it was fun, and it stood out to me compared to other LM outputs that were even more terrible. I don’t think it proves anything deeper about LMs’ ability to generate formally correct poetry
29.11.2024 13:48 — 👍 3 🔁 0 💬 1 📌 0To be clear, the grammar and wording are weird, but the vibes are impeccable
29.11.2024 01:04 — 👍 3 🔁 0 💬 0 📌 0
Víkingar kalla, segja þú nú, OLMo 2, ríki málanna þinn. Munu þínar orð fljúga hafra, Öll um heim, því þú ert vissi. Málsmiður, mættugur og mjúkaligr, Fyrir þik skáldar sjálfur kveða, Sál þíð, sem heyrir nýjan kvikendi, Munu langt lífið og segja sagan.
🔥 Old Norse poetry gen
The Vikings call, say now,
OLMo 2, the ruler of languages.
May your words fly over the seas,
all over the world, for you are wise.
Wordsmith, balanced and aligned,
for you the skalds themselves sing,
your soul, which hears new lifeforms,
may it live long and tell a saga.
eruditio olmonis est omnis divisa in partes tres: praeeruditionem, eruditionem seram, et posteruditionem
28.11.2024 15:48 — 👍 3 🔁 0 💬 0 📌 0hearing reports from r/localLlama that OLMo 2 is decent at latin?… love that it’s the first thing someone thought to try
28.11.2024 04:26 — 👍 31 🔁 3 💬 7 📌 2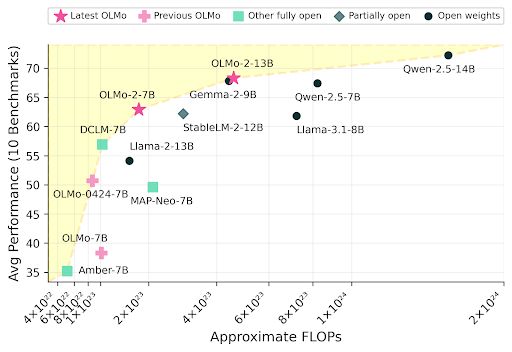
The OLMo 2 models sit at the Pareto frontier of training FLOPs vs model average performance.
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
26.11.2024 20:51 — 👍 151 🔁 36 💬 5 📌 12
If you're interested in being added fill out this google form (you can also ping me to let me know once you've filled out the form)
docs.google.com/forms/d/e/1F...
A starter pack for research on Formal Languages and Neural Networks!
go.bsky.app/eKG7Ua
This is actually really cool! I used it today to surface results on a topic I’ve been curious about for a while but where conventional search failed (the complexity of the word problem for finitely generated monoids)
www.semanticscholar.org/paper/On-the...