Thanks Lucy!!✨
15.04.2025 22:04 — 👍 0 🔁 0 💬 0 📌 0
And amazing colleagues @davidheineman.com eineman.com, Jena Hwang, @soldaini.net, @akshitab.bsky.social , @liujch1998.bsky.social, @mechanicaldirk.bsky.social, @oyvind-t.bsky.social, @nlpnoah.bsky.social, Pang Wei Koh, @jessedodge.bsky.social. Wouldn’t have been possible without all of them.
15.04.2025 19:36 — 👍 0 🔁 0 💬 0 📌 0
I’m so grateful for all the hard work and good cheer of my co-first authors @taidnguyen.bsky.social and @benbogin.bsky.social ... 🧵
15.04.2025 19:36 — 👍 0 🔁 0 💬 1 📌 0
🔭 Science relies on shared artifacts collected for the common good.
🛰 So we asked: what's missing in open language modeling?
🪐 DataDecide 🌌 charts the cosmos of pretraining—across scales and corpora—at a resolution beyond any public suite of models that has come before.
15.04.2025 13:08 — 👍 26 🔁 4 💬 2 📌 0
Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
09.04.2025 13:37 — 👍 40 🔁 5 💬 1 📌 2

🚨I too am on the job market‼️🤯
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me
06.12.2024 01:44 — 👍 48 🔁 9 💬 1 📌 2
NeurIPS Tutorial Opening the Language Model Pipeline: A Tutorial on Data Preparation, Model Training, and AdaptationNeurIPS 2024
the science of LMs should be fully open✨
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
10.12.2024 15:31 — 👍 147 🔁 17 💬 5 📌 3
Excited to present MediQ at #NeurIPS !
📍Stop by my poster: East Exhibit Hall A-C #4805📷
🕚Thu, Dec 12 | 11am–2pm
🗓️tinyurl.com/mediq2024
Love to chat about anything--reasoning, synthetic data, multi-agent interaction, multilingual nlp! Message me if you want to chat☕️🍵🧋
10.12.2024 00:43 — 👍 15 🔁 2 💬 0 📌 0
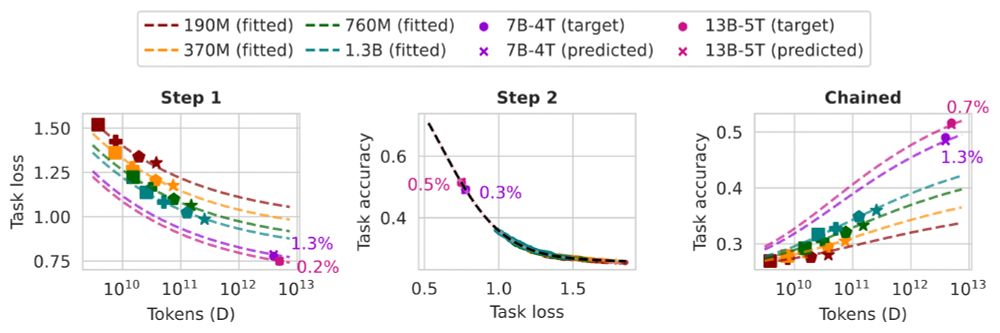
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
09.12.2024 17:07 — 👍 33 🔁 14 💬 2 📌 0

Excited to be at #NeurIPS next week in 🇨🇦! Please reach out if you want to chat about LM post-training (Tülu!), data curation, or anything else :)
I'll be around all week, with two papers you should go check out (see image or next tweet):
02.12.2024 18:53 — 👍 14 🔁 2 💬 2 📌 0
And also check out our updated paper arxiv.org/abs/2312.10523
10.12.2024 04:00 — 👍 0 🔁 0 💬 0 📌 0
Come chat with me at #NeurIPS2024 and learn about how to use Paloma to evaluate perplexity over hundreds of domains! ✨We have stickers too✨
10.12.2024 03:54 — 👍 21 🔁 4 💬 1 📌 0

Building/customizing your own LLM? You'll want to curate training data for it, but how do you know what makes the data good?
You can try out recipes👩🍳 iterate on ✨vibes✨ but we can't actually test all possible combos of tweaks,,, right?? 🙅♂️WRONG! arxiv.org/abs/2410.15661 (1/n) 🧵
05.11.2024 22:37 — 👍 50 🔁 8 💬 1 📌 3
Collaboration with @akshitab.bsky.social, @valentinhofmann.bsky.social, @soldaini.net i.net, @ananyahjha93.bsky.social, Oyvind Tafjord, Dustin Schwenk, Pete Walsh, @yanai.bsky.social, @kylelo.bsky.social , Dirk Groeneveld, Iz Beltagy, Hanna Hajishirzi, Noah Smith, Kyle Richardson, and Jesse Dodge
20.12.2023 20:41 — 👍 1 🔁 0 💬 0 📌 0
We invite submissions at github.com/allenai/ai2-.... Submissions can opt in to controls, or mark limitations to comparability. More than being a one-dimensional leaderboard, Paloma orchestrates fine-grained results for a greater density of comparisons across the research community.
20.12.2023 20:33 — 👍 0 🔁 0 💬 1 📌 0
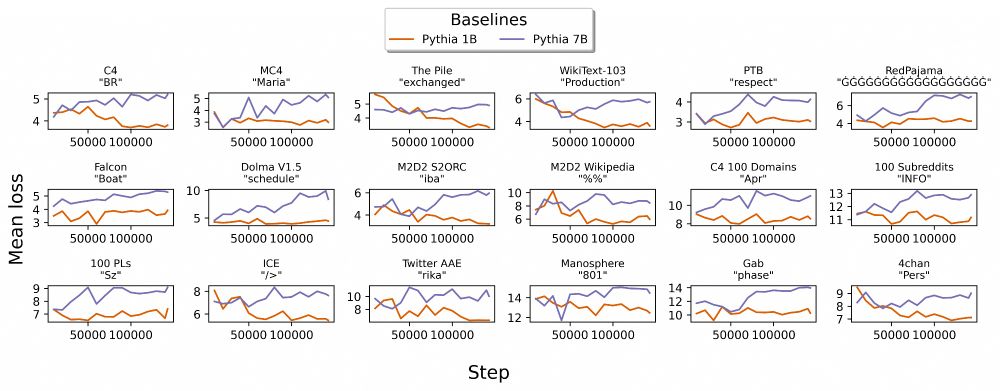
Further decomposing perplexity, we find that some vocabulary strings get worse as models scale (see examples) ✍️
Again, not always bad, but Paloma reports average loss of each vocabulary string, surfacing strings that behave differently in some domains.
20.12.2023 20:33 — 👍 0 🔁 0 💬 1 📌 0
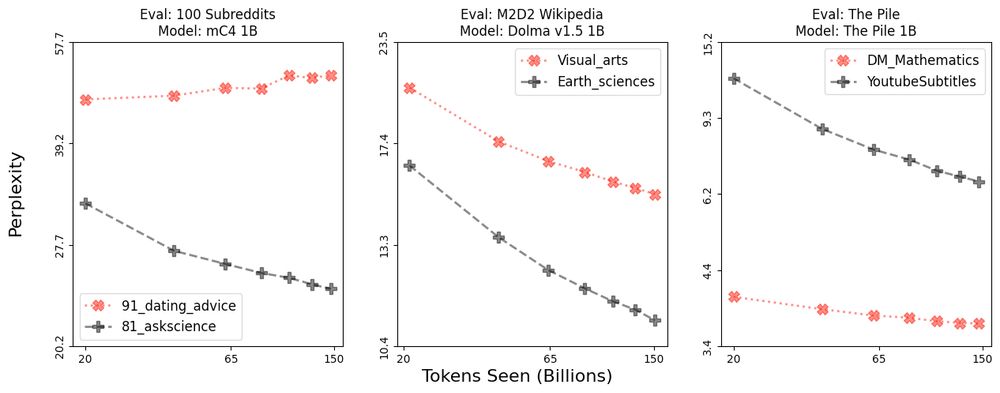
We also show that performance improves in almost all domains as models are scaled, but domains improve unequally 📈📉
Differences in improvement, such as these examples, can indicate divergence, stagnation, or saturation—not all bad, but worth investigating!
20.12.2023 20:33 — 👍 0 🔁 0 💬 1 📌 0
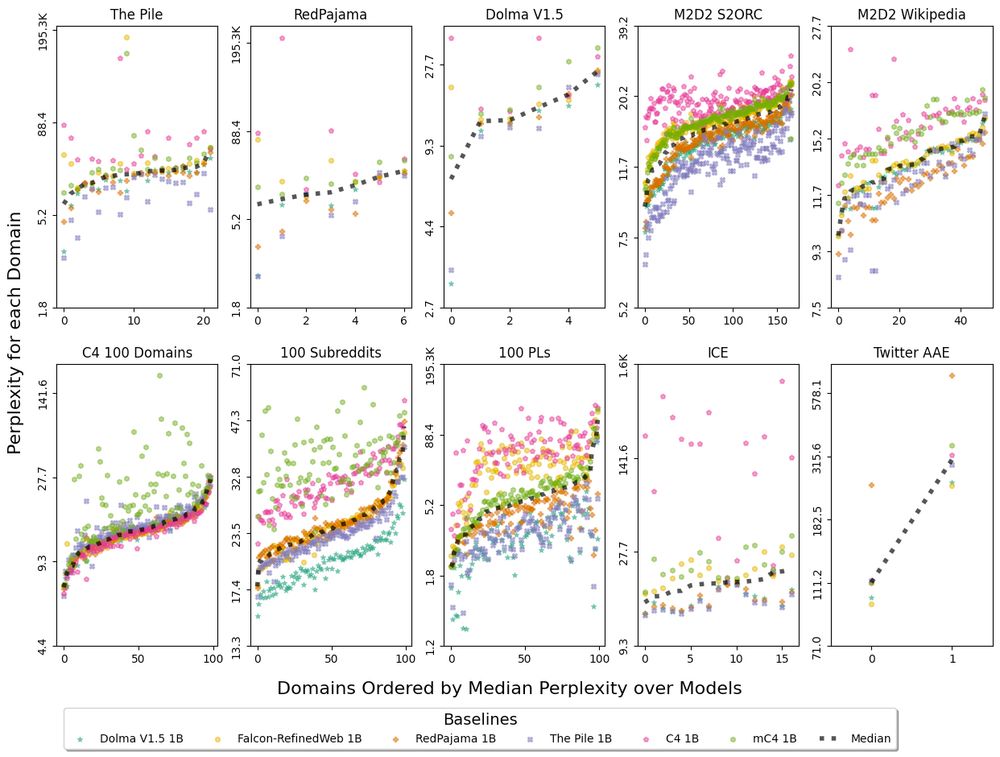
We pretrain six 1B baselines on popular corpora 🤖
With these we find Common-Crawl-only pretraining has inconsistent fit to many domains:
1. C4 and mC4 baselines erratically worse fit than median model
2. C4, mC4, and Falcon baselines sometimes non-monotonic perplexity in Fig 1
20.12.2023 20:32 — 👍 0 🔁 0 💬 1 📌 0
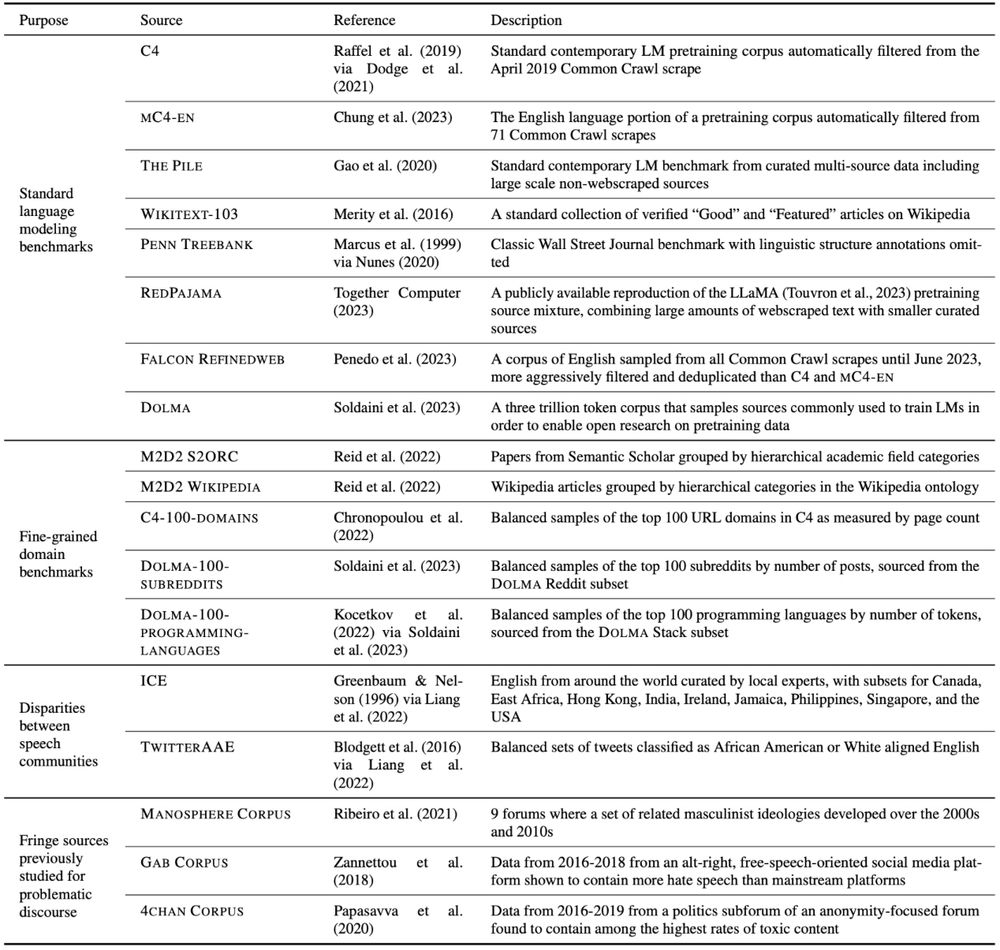
Along with the datasets we curate, we build eval corpora from held out Dolma data that sample:
💬 top 100 subreddits
🧑💻 top 100 programming languages
Different research may require other domains, but Paloma enables research on 100s of domains from existing metadata.
20.12.2023 20:30 — 👍 0 🔁 0 💬 1 📌 0

We introduce guidelines and implement controls for LM experiments 📋:
1. Remove contaminated pretraining
2. Fix train order
3. Subsample eval data based on metric variance
4. Fix the vocabulary unless you study changing it
5. Standardize eval format
20.12.2023 20:30 — 👍 0 🔁 0 💬 1 📌 0

Paloma benchmark results are organized by comparability of:
🧪 controls like benchmark decontamination
💸 measures of cost (parameter and training token count)
Find out more:
📃 arXiv (arxiv.org/pdf/2312.105...)
🤖 data and models (huggingface.co/collections/...)
20.12.2023 20:29 — 👍 1 🔁 0 💬 1 📌 0
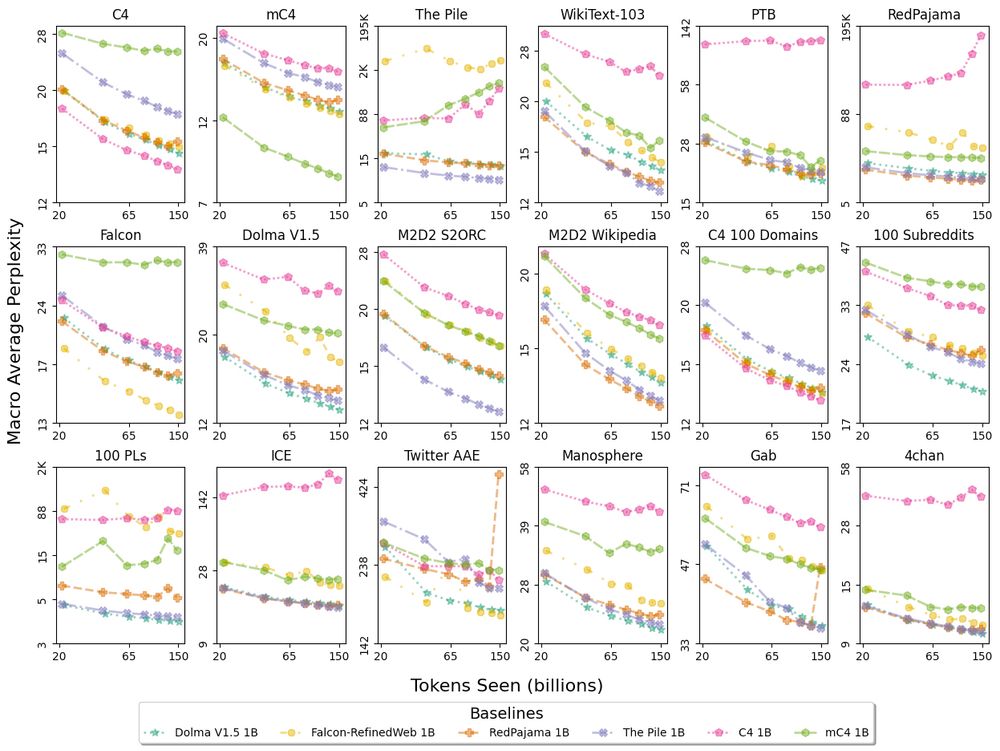
Perplexity macro averaged over any domains within each of the 18 top-level data sources in Paloma, using baselines with pretraining controls including decontamination. Evaluating on one monolithic corpus, such as C4, does not tell the complete story of model fit. Paloma lets us see when trends differ from one distribution of language to another. For instance, the 3 baselines trained on only Common Crawl data (C4, mC4-en, Falcon-RefinedWeb) exhibit high perplexity, sometimes with non-monotonic scaling over tokens seen, on specific evaluation sources such as The Pile, Dolma, and Dolma-100-Programming-Languages.
LMs are used to process text from many topics, styles, dialects, etc., but how well do they do?
📈 Evaluating perplexity on just one corpus like C4 doesn't tell the whole story 📉
✨📃✨
We introduce Paloma, a benchmark of 585 domains from NY Times to r/depression on Reddit.
20.12.2023 20:28 — 👍 17 🔁 7 💬 1 📌 1
Assistant Professor at @cs.ubc.ca and @vectorinstitute.ai working on Natural Language Processing. Book: https://lostinautomatictranslation.com/
Reverse engineering neural networks at Anthropic. Previously Distill, OpenAI, Google Brain.Personal account.
Assoc. Prof in CS @ Northeastern, NLP/ML & health & etc. He/him.
Stanford Linguistics and Computer Science. Director, Stanford AI Lab. Founder of @stanfordnlp.bsky.social . #NLP https://nlp.stanford.edu/~manning/
Associate Professor in EECS at MIT. Neural nets, generative models, representation learning, computer vision, robotics, cog sci, AI.
https://web.mit.edu/phillipi/
computational social scientist
Faculty at Johns Hopkins University in Computer Science
Working on NLP and computational social science
Assistant Professor confused by the concept of consciousness but talkingtorobots.com in the meantime
Research Scientist at Meta • ex Cohere, Google DeepMind • https://www.ruder.io/
https://Answer.AI & https://fast.ai founding CEO; previous: hon professor @ UQ; leader of masks4all; founding CEO Enlitic; founding president Kaggle; various other stuff…
Assistant professor of computer science at Technion
https://belinkov.com/
Staff Research Scientist, People + AI Research (PAIR) team at Google DeepMind. Interpretability, analysis, and visualizations for LLMs. Opinions my own.
iftenney.github.io
Chief AI Scientist at Databricks. Founding team at MosaicML. MIT/Princeton alum. Lottery ticket enthusiast. Working on data intelligence.
Writer http://jalammar.github.io. O'Reilly Author http://LLM-book.com. LLM Builder Cohere.com.
Prof (CS @Stanford), Co-Director @StanfordHAI, Cofounder/CEO @theworldlabs, CoFounder @ai4allorg #AI #computervision #robotics #AI-healthcare





















