This research opens up an exciting possibility: predictive coding as a fundamental cortical learning mechanism, guided by area-specific modulations that act as high-level control over the learning process. (5/6)
10.06.2025 13:17 — 👍 1 🔁 0 💬 1 📌 0
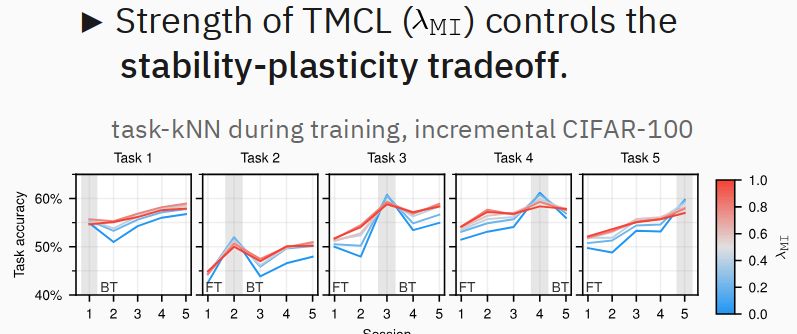
Furthermore, we can dynamically adjust the stability-plasticity trade-off by adapting the strength of the modulation invariance term. (4/6)
10.06.2025 13:17 — 👍 1 🔁 0 💬 1 📌 0
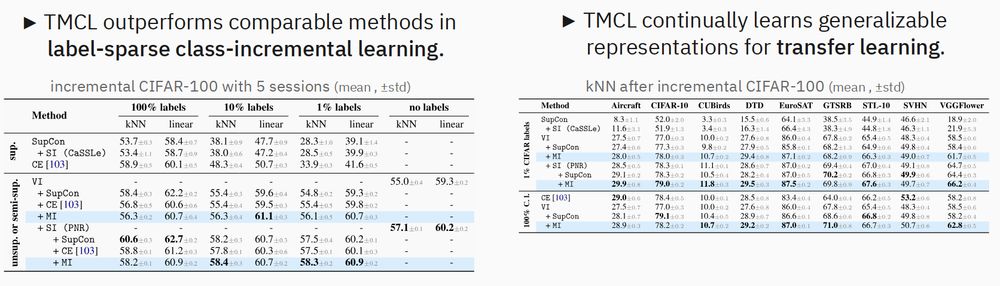
Key finding: With only 1% labels, our method outperforms comparable continual learning algorithms both on the continual task and when transferred to other tasks.
Therefore, we continually learn generalizable representations, unlike conventional, class-collapsing methods (e.g. Cross-Entropy). (3/6)
10.06.2025 13:17 — 👍 1 🔁 0 💬 1 📌 0
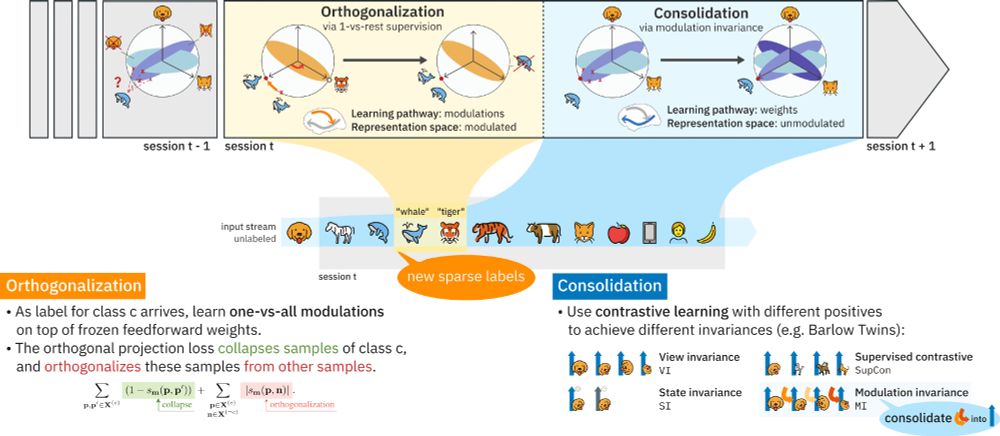
Feedforward weights learn via view-invariant self-supervised learning, mimicking predictive coding. Top-down class modulations, informed by new labels, orthogonalize same-class representations. These are then consolidated into the feedforward pathway through modulation invariance. (2/6)
10.06.2025 13:17 — 👍 4 🔁 0 💬 1 📌 0
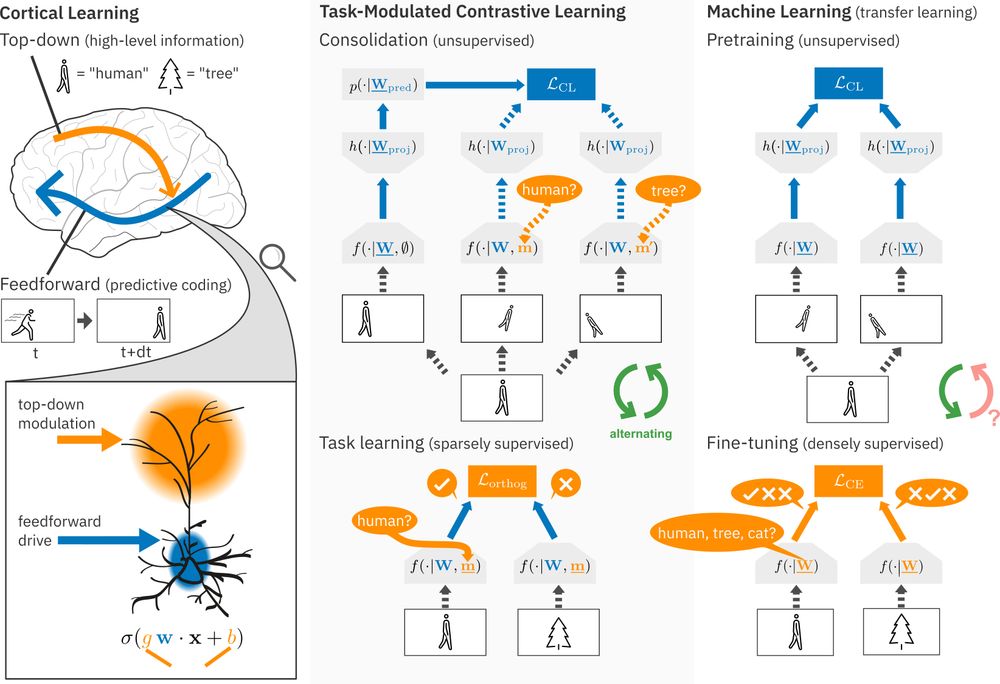
New #NeuroAI preprint on #ContinualLearning!
Continual learning methods struggle in mostly unsupervised environments with sparse labels (e.g. parents telling their child the object is an 'apple').
We propose that in the cortex, predictive coding of high-level top-down modulations solves this! (1/6)
10.06.2025 13:17 — 👍 8 🔁 2 💬 1 📌 0
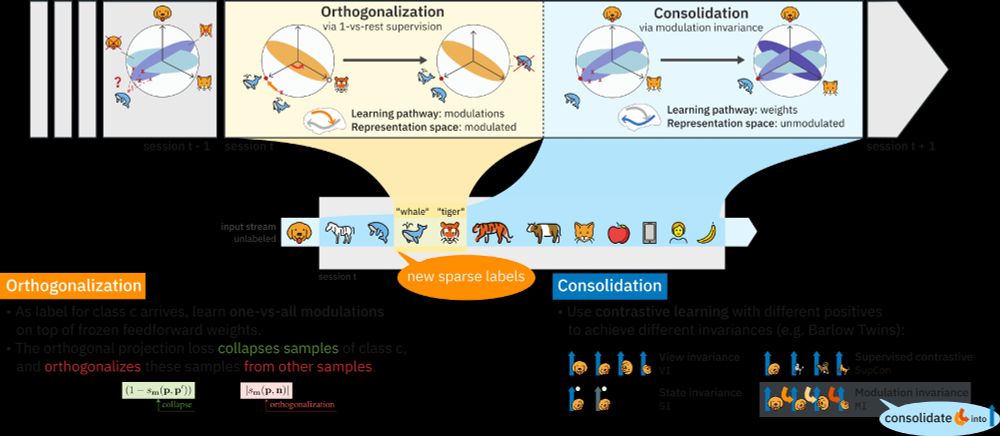
Feedforward weights learn via view-invariant self-supervised learning, mimicking predictive coding. Top-down class modulations, informed by new labels, orthogonalize same-class representations. These are then consolidated into the feedforward pathway through modulation invariance. (2/6)
10.06.2025 13:13 — 👍 0 🔁 0 💬 0 📌 0
ML Professor at École Polytechnique. Python open source developer. Co-creator/maintainer of POT, SKADA. https://remi.flamary.com/
👀🧠(x) | x ∈ {👀🧠,🤖}
PhD student @MPI-SWS
trying to trick rocks into thinking and remembering.
EurIPS is a community-organized, NeurIPS-endorsed conference in Copenhagen where you can present papers accepted at @neuripsconf.bsky.social
eurips.cc
Assistant Professor at the Department of Computer Science, University of Liverpool.
https://lutzoe.github.io/
Hi 👋 I'm a postdoc in the #Neuroimmunology and #Imaging group at the @dzne.science Bonn 🧪🔬 Passionate about #ComputationalNeuroscience 🧠💻 and #NeuralModeling 🧮
🌍 fabriziomusacchio.com
👨💻 github.com/FabrizioMusacchio
🐘 sigmoid.social/@pixeltracker
CTO @Numenta. Neuroscience & AI. I love to discuss sparsity, sensorimotor learning, dendrites, deep learning, and #OpenScience.
PostDoc at ETH Zurich | Prev. PhD at Sapienza Roma| Working on Representation Learning.
irene.cannistraci.dev
PostDoc @ISTAustria 🧑🏻💻 | Organizer of @unireps.bsky.social | Member @ellis.eu | Prev. PhD @SapienzaRoma @ELLISforEurope | @amazon AWS AI | @autodesk AI Lab | (he/him)
Searching for principles of neural representation | Neuro + AI @ enigmaproject.ai | Stanford | sophiasanborn.com
Machine Learning Researcher @ Apple
Apple MLR (Barcelona) intern | ELLIS Ph.D. student in representation learning @SapienzaRoma & @ISTAustria | Former NLP Engineer @babelscape
flegyas.github.io
Research lab at UCSB Engineering revealing the geometric signatures of nature and artificial intelligence | PI: @ninamiolane.bsky.social
NeurIPS workshop and digital community | 🌐 geometry, algebra, topology + 🤖 deep learning + 🧠 neuroscience | Join us on slack! http://tinyurl.com/nr-slack
Visit our website: https://www.neurreps.org/
machine learning researcher @ Apple machine learning research
ML PhD student at University of Oxford. Interested in Geometric Deep Learning
Chilean roboticist • Research Associate at the School of Informatics, University of Edinburgh • Prev: UOXF, ETHZ, UChile • Robot perception, navigation, and autonomy
🌐 http://mmattamala.github.io
Postgraduate researcher (PhD) at Imperial College London and visiting researcher at the University of Oxford. Working on probabilistic machine learning.
AMLab, Informatics Institute, University of Amsterdam. ELLIS Scholar. Geometry-Grounded Representation Learning. Equivariant Deep Learning.
Created by @columbiauniversity.bsky.social to be the world's foremost neuroscience institute, we are deciphering the brain — how it develops, works, endures and recovers.