Our paper on multilingual reasoning is accepted to Findings of #EMNLP2025! 🎉 (OA: 3/3/3.5/4)
We show SOTA LMs struggle with reasoning in non-English languages; prompt-hack & post-training improve alignment but trade off accuracy.
📄 arxiv.org/abs/2505.22888
See you in Suzhou! #EMNLP
20.08.2025 20:02 — 👍 7 🔁 3 💬 0 📌 0

📢 New paper: Can unsupervised metrics extracted from MT models detect their translation errors reliably? Do annotators even *agree* on what constitutes an error? 🧐
We compare uncertainty- and interp-based WQE metrics across 12 directions, with some surprising findings!
🧵 1/
30.05.2025 14:28 — 👍 16 🔁 3 💬 1 📌 2

XReasoning - models - a shanchen Collection
multilingualness - Dataset for XReasoning
ds - means continue post-training on deepseek distilled qwen math 7b
limo-{language}-{amount of data}
[12/] Grateful to all collaborators for their contributions!
@shan23chen.bsky.social @Zidi_Xiong @Raquel Fernández @daniellebitterman.bsky.social @arianna-bis.bsky.social
Github repo: github.com/Betswish/mCo...
Benchmark: huggingface.co/collections/...
Trained LRMs: huggingface.co/collections/...
30.05.2025 13:08 — 👍 1 🔁 0 💬 0 📌 0
[11/] Besides, increasing the instances doesn't reliably mitigate the issue. When increasing from 100 to 250 training instances, the post-trained LRMs suffer from a drop in matching rate, while accuracy exhibits only marginal recovery, far below the accuracy of the original LRM.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0

[10/] The results show that post-training on merely 100 instances sharply increases the matching rate to nearly 100% for TH and TE and to 80% for JA, but decreases accuracy, demonstrating the effectiveness of post-training to improve language matching, but the trade-off persists.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0


[9/] To see whether further training can help, we post-train on Distilled-R1-7B using mini training sets of 100 or 250 instances per poor-matching language (Japanese, Thai, Telugu), resulting in six post-trained LRMs. The training data are filtered and translated from LIMO.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0


[8/] Corresponding to the heatmaps, we further analyze the actual thinking languages of the LRM, where a clear mismatch is observed. Besides, all mismatches (i.e., red marks) fall into English or Chinese, suggesting the impact of thinking data on the model’s reasoning capability.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0
[7/] Interestingly, reasoning in English consistently results in higher accuracy, especially after prompt hacking. This aligns with concurrent work on improving answer accuracy via cross-lingual reasoning, supporting the reliability of our experiments and XReasoning benchmark.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0
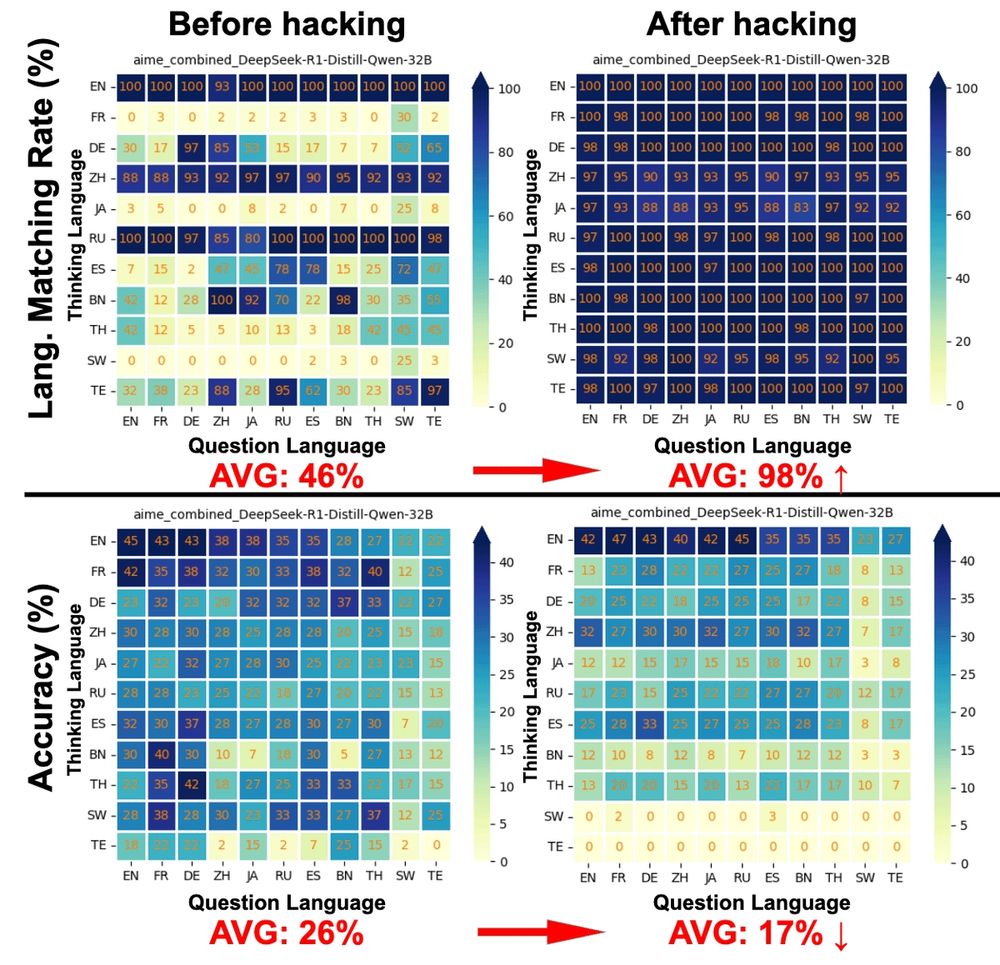
[6/] Heatmaps by query/thinking language show the 32B LRM fails to generate traces in the prompted language—e.g., asked to think in FR, it defaults to EN. Motivating LRM to reason with hacking increases the matching from 46% to 98%, but introduces a noticeable accuracy decrement.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0

[5/] Overall, LRMs struggle to follow instructions to think in user-specified languages with standard prompts. Motivating LRMs to generate traces in user query language with prompt hacking boosts language matching, but decreases accuracy, which shrinks as model size increases.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0


[4/] Besides the standard prompting with explicitly specified thinking language in the instruction, we introduce and leverage the prompt hacking technique to induce the LRM to generate the thinking traces in the user-expected languages.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0

[3/] We comprehensively evaluate six SOTA LRMs belonging to two families: Distilled-R1 and Skywork-OR1. Due to the lack of multilingual reasoning datasets, we introduce a novel benchmark named XReasoning, covering easy MGSM and translated challenging AIME2024, AIME2025, and GPQA_Diamond.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0

[2/] The matching of thinking language is as important as accuracy because it makes the traces more readable and easier for users to verify. Even correct answers can feel untrustworthy if users can’t understand how the model gets there, especially as task complexity increases.
30.05.2025 13:08 — 👍 0 🔁 0 💬 1 📌 0

[1/]💡New Paper
Large reasoning models (LRMs) are strong in English — but how well do they reason in your language?
Our latest work uncovers their limitation and a clear trade-off:
Controlling Thinking Trace Language Comes at the Cost of Accuracy
📄Link: arxiv.org/abs/2505.22888
30.05.2025 13:08 — 👍 7 🔁 4 💬 1 📌 3
[8/] Taken together, our findings reveal the LLMs' capability of consistently utilizing multilingual contexts, with a barrier in decoding answers in the user language. These deepen the understanding of how LLMs work in mRAG systems, providing directions for future improvements.
11.04.2025 16:04 — 👍 0 🔁 0 💬 0 📌 0


[7/] Including distractors, our analysis with both accuracy and feature attribution techniques further shows that distracting passages negatively impact answer quality regardless of their language. However, distractors in the query language exert a slightly stronger influence.
11.04.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0
[6/] This finding suggests that generating in the target language is the major bottleneck, which could dominate, if not hide, the effect of similarity with the passage language.
11.04.2025 16:04 — 👍 1 🔁 0 💬 1 📌 0

[5/] Detailed heatmaps further showcase that answer accuracy is relatively consistent within each row, more so than within each column. In other words, the query language is much more predictive of accuracy than the passage language.
11.04.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0

[4/] Our experiments with 4 LLMs across 3 QA datasets, covering 48 languages, reveal a surprising ability of LLMs to extract relevant information from passages in different languages than the query, but a weaker ability to formulate an answer in the correct language (shading bars).
11.04.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0

[3/] Through accuracy and feature attribution analysis, we assess LLMs’ ability to make consistent use of a relevant passage regardless of its language, respond in expected languages, and focus on relevant passages even when distractors in different languages are provided.
11.04.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0
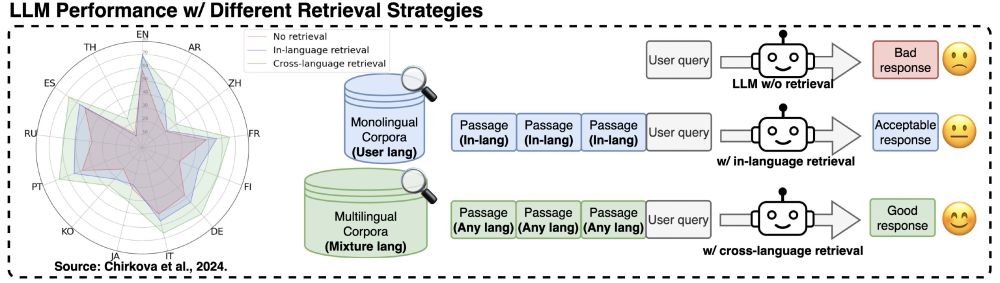
[2/] Multilingual RAG (mRAG) has been shown to be beneficial, particularly for low-resource languages. However, the extent to which LLMs can leverage multilingual contexts to generate accurate answers, independently from retrieval quality, remains understudied.
11.04.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0

✨ New Paper ✨
[1/] Retrieving passages from many languages can boost retrieval augmented generation (RAG) performance, but how good are LLMs at dealing with multilingual contexts in the prompt?
📄 Check it out: arxiv.org/abs/2504.00597
(w/ @arianna-bis.bsky.social @Raquel_Fernández)
#NLProc
11.04.2025 16:04 — 👍 4 🔁 5 💬 1 📌 1
Many thanks to all collaborators for their contributions!
Tianyu Liu, Paul He, Arianna Bisazza, @mrinmaya.bsky.social, Ryan Cotterell.
24.01.2025 09:56 — 👍 0 🔁 0 💬 0 📌 0
[8/8] 🌟Take-home msg: p(question) can gauge LM performance in RAG QA.
Considering we are taking the first step to prompt optimization without LM decoding, we follow the previous setup and mainly adopt document reordering. Thus, other prompt modifications are left for the future.
24.01.2025 09:56 — 👍 0 🔁 0 💬 1 📌 0

[7/8] Based on the above analysis, we propose two methods to optimize the prompt of the QA task with RAG. Experimental results show that both methods boost the model performance of the baseline prompt with documents in random order, supporting our hypothesis and claims above.
24.01.2025 09:56 — 👍 0 🔁 0 💬 1 📌 0
[6/8] The observations may explain instance-level correlation: a higher likelihood indicates the prompt is less surprising to/better understood by LM (e.g. have seen it in pretraining). Thus, LM tends to assign a higher probability to the gold answer, leading to better performance after decoding.
24.01.2025 09:56 — 👍 0 🔁 0 💬 1 📌 0

[5/8] We also observe an overlap between LM performance and question likelihoods by reproducing the U-shape accuracy curve of Lost-in-the-Middle paper and plotting the corresponding p(question) in the same figure. Meanwhile, gold answer likelihoods change synchronously with them.
24.01.2025 09:56 — 👍 0 🔁 0 💬 1 📌 0

[4/8] Zooming into the instance level, we find that each question is more likely to be correctly answered when it reaches the highest likelihood via document reordering with other segments unchanged in RAG pipelines.
24.01.2025 09:56 — 👍 0 🔁 0 💬 1 📌 0

[3/8] Starting from corpus-level validation, we find that the questions with higher likelihoods in the dataset can be better answered than the ones with medium or low likelihoods.
24.01.2025 09:56 — 👍 0 🔁 0 💬 1 📌 0
PhD student at ILLC / University of Amsterdam, interested in safety, bias, and stereotypes in conversational and generative AI #NLProc
https://veranep.github.io/
Immigrant. Digital health equity researcher. Hospitalist.
The 2025 Conference on Language Modeling will take place at the Palais des Congrès in Montreal, Canada from October 7-10, 2025
PhD candidate @Technion | NLP
Head of LanD research group at FBK - Italy | NLP for Social Good.
I'm a physician-scientist working in clinical NLP and LLM safety/evaluation. You'll find me in the lab or the rad onc clinic | BWH | DFCI | Harvard Medical School
www.bittermanlab.org
PhD student @gronlp.bsky.social | University of Groningen
The largest workshop on analysing and interpreting neural networks for NLP.
BlackboxNLP will be held at EMNLP 2025 in Suzhou, China
blackboxnlp.github.io
Associate Professor at GroNLP ( @gronlp.bsky.social ) #NLP | Multilingualism | Interpretability | Language Learning in Humans vs NeuralNets | Mum^2
Head of the InClow research group: https://inclow-lm.github.io/
Prof, Chair for AI & Computational Linguistics,
Head of MaiNLP lab @mainlp.bsky.social, LMU Munich
Co-director CIS @cislmu.bsky.social
Visiting Prof ITU Copenhagen @itu.dk
ELLIS Fellow @ellis.eu
Vice-President ACL
PI MCML @munichcenterml.bsky.social
PhD candidate in Linguistics at Unipv & Unibg // Exploring the representation of femicide cases in Italian news reports
Postdoc at Mila & McGill University 🇨🇦 with a PhD in NLP from the University of Edinburgh 🏴 interpretability x memorisation x (non-)compositionality. she/her 👩💻 🇳🇱
Postdoctoral Scholar Stanford NLP
ML SWE @ Google DeepMind Gemini. Prev. EPFL, Google, Amazon, NTUA.
Professor at the University of Sheffield. I do #NLProc stuff.
PhD #NLProc from CLTL, Vrije Universiteit Amsterdam || Interests: Computational Argumentation, Responsible AI, interdisciplinarity, cats || I express my own views
#MachineTranslation Research Unit @ Fondazione Bruno Kessler
#nlproc #deeplearning #ai
mt.fbk.eu
PhD student @ ETH Zürich | all aspects of NLP but mostly evaluation and MT | go vegan | https://vilda.net
PhD candidate at University of Amsterdam, working on LLM efficiency.
PhD student @ImperialCollege. Research Scientist Intern @Meta prev. @Cohere, @GoogleAI. Interested in generalisable learning and reasoning. She/her
lisaalaz.github.io





















