


Full house at BlackboxNLP at #EMNLP2025!! Getting ready for my 1.45PM keynote 😎 Join us in A102 to learn about "Memorization: myth or mystery?"
09.11.2025 03:04 — 👍 12 🔁 1 💬 0 📌 0
@vernadankers.bsky.social
Postdoc at Mila & McGill University 🇨🇦 with a PhD in NLP from the University of Edinburgh 🏴 memorization vs generalization x (non-)compositionality. she/her 👩💻 🇳🇱
Full house at BlackboxNLP at #EMNLP2025!! Getting ready for my 1.45PM keynote 😎 Join us in A102 to learn about "Memorization: myth or mystery?"
09.11.2025 03:04 — 👍 12 🔁 1 💬 0 📌 0


🏆 full house at the IJCAI-JAIR Best Paper Award #talk delivered by Verna Dankers on Compositionality Decomposed: How do Neural Networks Generalise?! #IJCAI2025
20.08.2025 15:43 — 👍 5 🔁 1 💬 0 📌 0Thanks Jelle!! I'll make sure to prominently feature UvA in the talk tomorrow 😎 all discussions for Compositionality Decomposed were held back at Nikhef!
20.08.2025 03:57 — 👍 0 🔁 0 💬 0 📌 0
Congratulations to the winners of the 2025 IJCAI–JAIR Prize for their paper “Compositionality Decomposed: How Do Neural Networks Generalise?” — Dieuwke Hupkes, Verna Dankers, Mathijs Mul, and Elia Bruni! Presented by Edith Elkind, Northwestern University arxiv.org/abs/1908.08351
#IJCAI2025


Proud to accept a 5y outstanding paper award
@ijcai.org 🏆 from the Journal of AI Research for the impact Compositionality Decomposed has had, on behalf of the team (Dieuwke Hupkes, Elia Bruni & Mathijs Mul)!🧡 Come to room 513 on Wed@11.30 to learn about rethinking compgen evaluation in the LLM era🤖



Had a blast at #ACL2025 connecting with new/familiar faces, explaining the many affiliations on my badge, chatting about memorisation--generalisation, and visiting stunning Schönbrunn. A shoutout to the co-organisers & speakers of the successful @l2m2workshop.bsky.social 🧡 I learnt a lot from you!
04.08.2025 02:36 — 👍 7 🔁 0 💬 0 📌 0Main takeaway: students excel both by mimicking teachers and deviating from them & be careful with distillation, students may inherit teachers’ pros and cons. Work done during a Microsoft internship. Find me 👋🏼 Weds at 11 in poster session 4 arxiv.org/pdf/2502.01491 (5/5)
27.07.2025 15:37 — 👍 0 🔁 0 💬 0 📌 0...identifying scenarios in which students *outperform* teachers through SeqKD’s amplified denoising effects. Lastly, we establish that through AdaptiveSeqKD (briefly finetuning your teacher prior to distillation with HQ data) you can strongly decrease memorization and hallucinations. (4/5)
27.07.2025 15:37 — 👍 0 🔁 0 💬 1 📌 0
Students showed increases in verbatim memorization, large increases in extractive memorization, and also hallucinated much more than baselines! We go beyond average-case performance through additional analyses of how T, B, and S perform on data subgroups... (3/5)
27.07.2025 15:37 — 👍 0 🔁 0 💬 1 📌 0
SeqKD is still widely applied in NMT to obtain strong & small deployable systems, but your student models do not only inherit good things from teachers. In our short paper, we contrast baselines trained on the original corpus to students (trained on teacher-generated targets). (2/5)
27.07.2025 15:37 — 👍 0 🔁 0 💬 1 📌 0
Thrilled to be in Vienna to learn about all the papers & catch up with NLP friends 🇦🇹 You'll find me at the ACL mentorship session (Mon 2PM), at our @l2m2workshop.bsky.social (Fri) and at my poster (Wed 11AM)! I'll present work w/ @vyraun.bsky.social on memorization in NMT under SeqKD #ACL2025 (1/5)
27.07.2025 15:37 — 👍 8 🔁 0 💬 1 📌 0I miss Edinburgh and its wonderful people already!! Thanks to @tallinzen.bsky.social and @edoardo-ponti.bsky.social for inspiring discussions during the viva! I'm now exchanging Arthur's Seat for Mont Royal to join @sivareddyg.bsky.social's wonderful lab @mila-quebec.bsky.social 🤩
01.07.2025 21:33 — 👍 15 🔁 1 💬 3 📌 0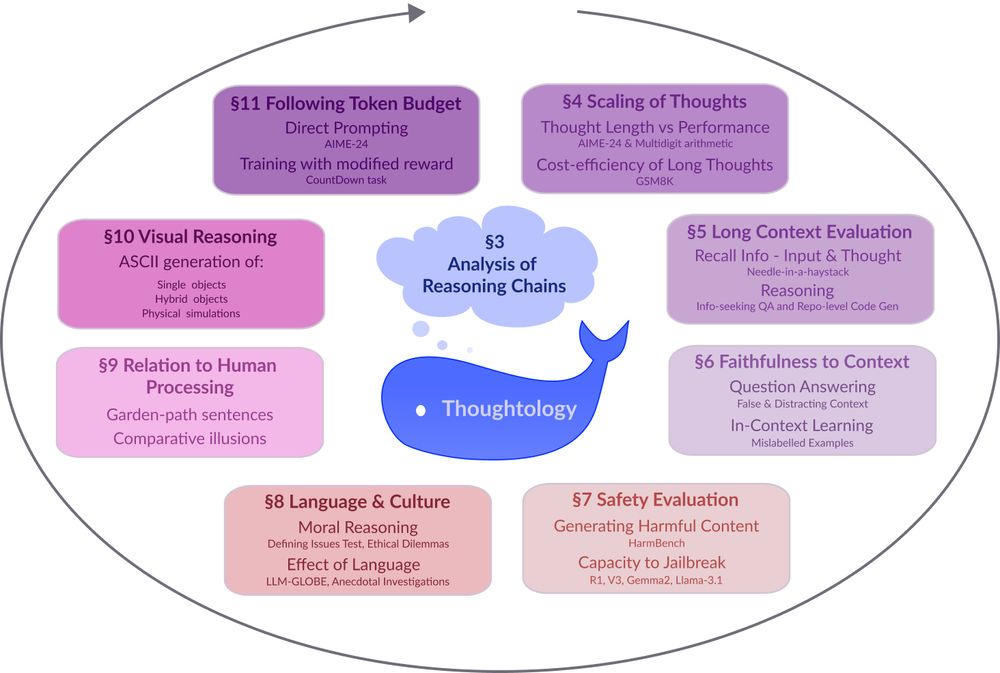
A circular diagram with a blue whale icon at the center. The diagram shows 8 interconnected research areas around LLM reasoning represented as colored rectangular boxes arranged in a circular pattern. The areas include: §3 Analysis of Reasoning Chains (central cloud), §4 Scaling of Thoughts (discussing thought length and performance metrics), §5 Long Context Evaluation (focusing on information recall), §6 Faithfulness to Context (examining question answering accuracy), §7 Safety Evaluation (assessing harmful content generation and jailbreak resistance), §8 Language & Culture (exploring moral reasoning and language effects), §9 Relation to Human Processing (comparing cognitive processes), §10 Visual Reasoning (covering ASCII generation capabilities), and §11 Following Token Budget (investigating direct prompting techniques). Arrows connect the sections in a clockwise flow, suggesting an iterative research methodology.
Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour.
🔗: mcgill-nlp.github.io/thoughtology/
👋
11.03.2025 01:02 — 👍 1 🔁 0 💬 0 📌 0Super excited about the First L2M2 (Large Language Model Memorization) workshop at #ACL2025 in Vienna @l2m2workshop.bsky.social! 🥳 Submit via ARR in February, or directly to the workshop in March! Archival and non-archival contributions are welcome. 🗒️ sites.google.com/view/memoriz...
27.01.2025 22:03 — 👍 2 🔁 0 💬 0 📌 0
thinking of calling this "The Illusion Illusion"
(more examples below)



















