Submit your talk proposals here!
docs.google.com/forms/d/1gee...
14.02.2025 18:41 — 👍 3 🔁 3 💬 0 📌 0
Reminder that we are organizing the second edition of the /dev/games conference! If you’d like to speak about cool stuff that you’ve done gimme a shout 😊
21.01.2025 14:05 — 👍 5 🔁 1 💬 0 📌 0
Excited to see where this goes, making every character interactable, with their own stories and narratives has always fascinated me. Would like to see more immersive worlds, this could be great.
11.01.2025 08:49 — 👍 0 🔁 0 💬 0 📌 0

GitHub - Pagghiu/SaneCppLibraries: Sane C++ Libraries
Sane C++ Libraries. Contribute to Pagghiu/SaneCppLibraries development by creating an account on GitHub.
Sane C++ Libraries is 1 year old! 🎉🎂
✅ Fast compile time
✅ Bloat free
✅ Simple readable code
✅ Easy to integrate
⛔️ No C++ Standard Library
⛔️ No third party build dependencies
github.com/Pagghiu/SaneCppLibraries
Blog
pagghiu.github.io/site/blog/2024-12-23-SaneCpp1Year.html
🙏repost if you like it!❤️
23.12.2024 01:29 — 👍 34 🔁 8 💬 2 📌 0
We are organising the next edition of the /Dev/Games conference in beautiful Rome! Come join us and hit me up if you would like to be part of the presenters!
18.12.2024 16:09 — 👍 7 🔁 2 💬 0 📌 1
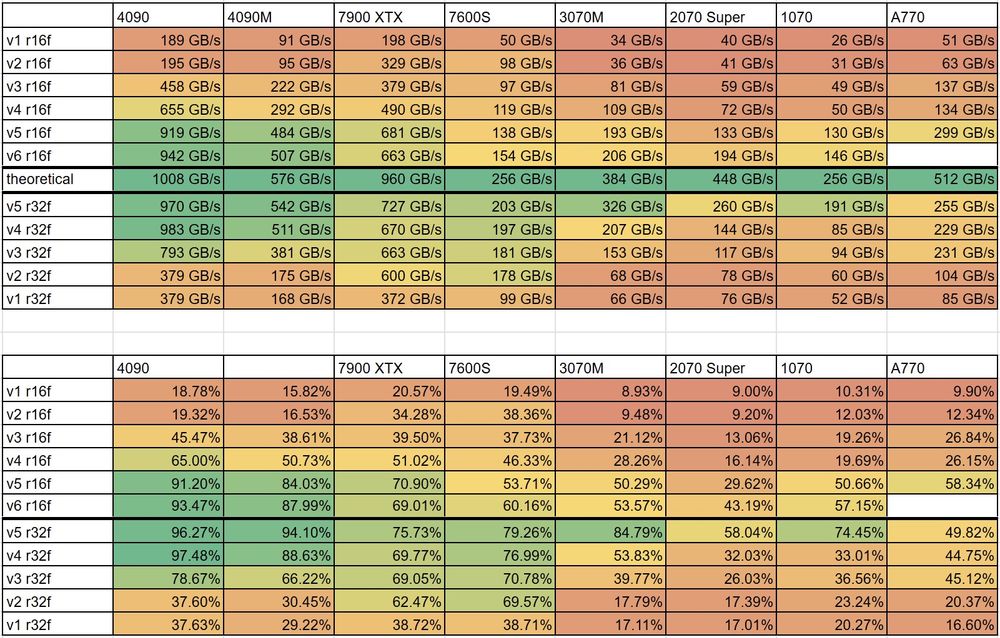
A table showing the experimental results of applying 6 different compute shader versions of a simple 3x3x3 box blur on a 512x512x512 texture using either GL_R16F or GL_R32F internal format for storage for a eight different GPUs spanning several GPU architectures and vendors.
The upper table shows the absolute effective bandwidth (measured as the sum of total bytes read and written divided by execution time), whereas the lower table shows the effective bandwidth relative to the theoretical bandwidth as a percentage.
Each row corresponds to a specific shader variant (except for the "theoretical" row, which displays the theoretical bandwidth according to the GPU specification), and each column corresponds to a specific GPU. The color coding is per column in the upper table, and it's a single color coding on the entire lower table.
Each version will be explained in detail in the subsequent posts.
Version 6 applies uses half precision floating point for the shared memory cache, and the relevant extension does not exist in the Intel drivers for Windows. Likewise this version is not applied to the GL_R32F internal format benchmarks since that would destroy the precision of the backing format anyway.
The code was written and initially tested on a desktop 4090 (the first column), which naturally skews the results a bit since everything was evaluated and tested on that GPU. Had I used another GPU I might have picked slightly different compromises, and the results would have been slightly different.
One interesting observation is that the RTX 4000 series (Ada Lovelace architecture) significantly overperform everything else, with 7900 XTX (RDNA3) slightly behind. A large part of these overwhelmingly efficient results is due to the massive caches these devices sport (72 MiB on the desktop 4090, 64 MiB on the laptop 4090, etc.), which really helps reach peak bandwidth a lot easier.
Let's wrap up this lovely week with a nice technical post
This is the "case study" from my Masterclass at GPC, where I apply a series of optimizations to improve the effective bandwidth of a 3x3x3 blur (a proxy for a huge set of operations on volumetric data)
Check ALT text for (a lot of) context.
17.11.2024 22:59 — 👍 134 🔁 25 💬 4 📌 4
Quick and dirty post on implementing hot shader reload with DXC: wallisc.github.io/rendering/20...
16.11.2024 19:13 — 👍 46 🔁 9 💬 2 📌 0
Well I guess it's time to be more active on here!
15.11.2024 10:10 — 👍 3 🔁 0 💬 0 📌 0