There’s a lot more detail in the full paper, and I would love to hear your thoughts and feedback on it!
Check out the preprint here: arxiv.org/pdf/2506.10150
17.06.2025 15:13 — 👍 1 🔁 0 💬 0 📌 0
Huge thanks to my amazing collaborators: Fai Poungpeth, @diyiyang.bsky.social, Erina Farrell, @brucelambert.bsky.social, and @mattgroh.bsky.social 🙌
17.06.2025 15:13 — 👍 1 🔁 0 💬 1 📌 0
LLMs, when benchmarked against reliable expert judgments, can be reliable tools for overseeing emotionally sensitive AI applications.
Our results show we can use LLMs-as-judge to monitor LLMs-as-companion!
17.06.2025 15:13 — 👍 1 🔁 0 💬 1 📌 0
For example, in one of the conversations in our dataset, a response that an expert saw as "dismissing” the speaker’s emotions, a crowdworker interpreted as "validating" their emotions instead!
17.06.2025 15:13 — 👍 1 🔁 0 💬 1 📌 0
These misjudgments from crowdworkers have huge implications for AI training and deployment❌
If we use flawed evaluations to train and monitor "empathic" AI, we risk creating systems that propagate a broken standard of what good communication looks like.
17.06.2025 15:13 — 👍 1 🔁 0 💬 1 📌 0
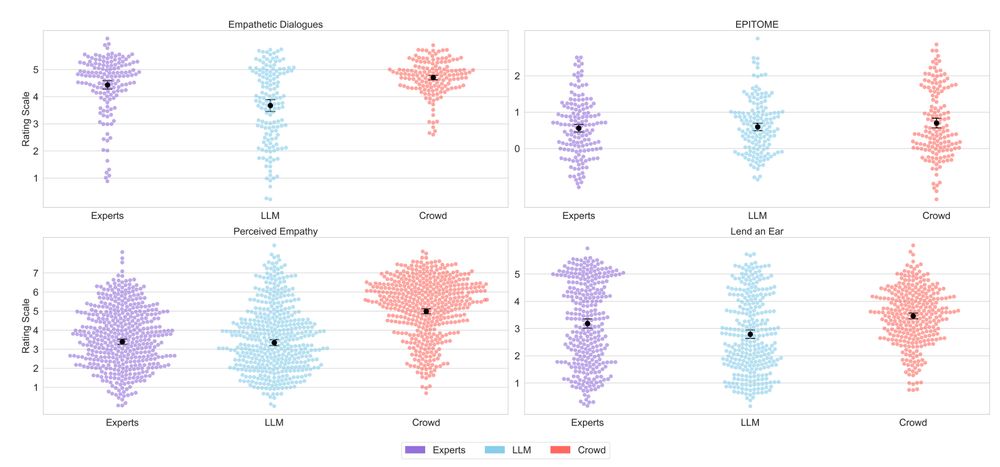
So why the gap between experts/LLMs and crowds?
Crowdworkers often
- have limited attention
- rely on heuristics like “it’s the thought that counts”
- focusing on intentions rather than actual wording
show systematic rating inflation due to social desirability bias
17.06.2025 15:13 — 👍 2 🔁 0 💬 1 📌 0
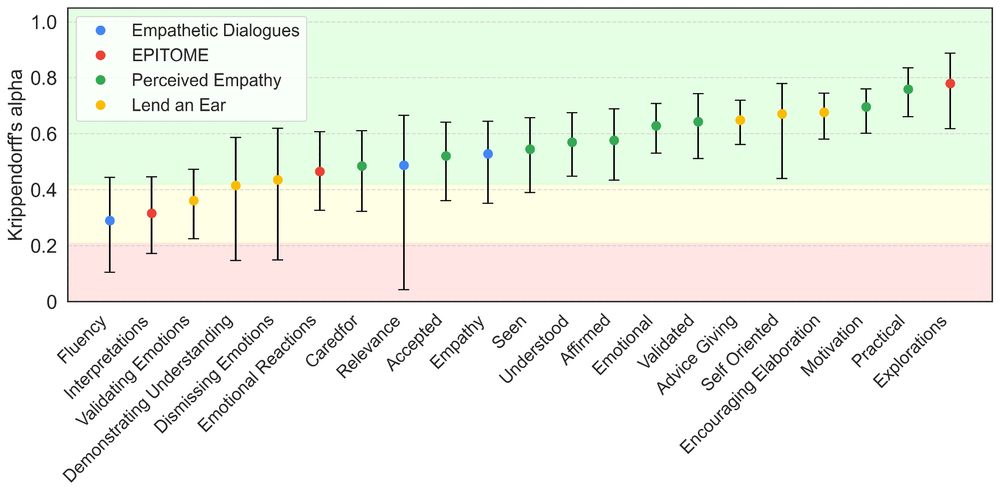
And when experts disagree, LLMs struggle to find a consistent signal too.
Here’s how expert agreement (Krippendorff's alpha) varied across empathy sub-components:
17.06.2025 15:13 — 👍 1 🔁 0 💬 1 📌 0
But here’s the catch: LLMs are reliable when experts are reliable.
The reliability of expert judgments depends on the clarity of the construct. For nuanced, subjective components of empathic communication, experts often disagree.
17.06.2025 15:13 — 👍 1 🔁 0 💬 1 📌 0
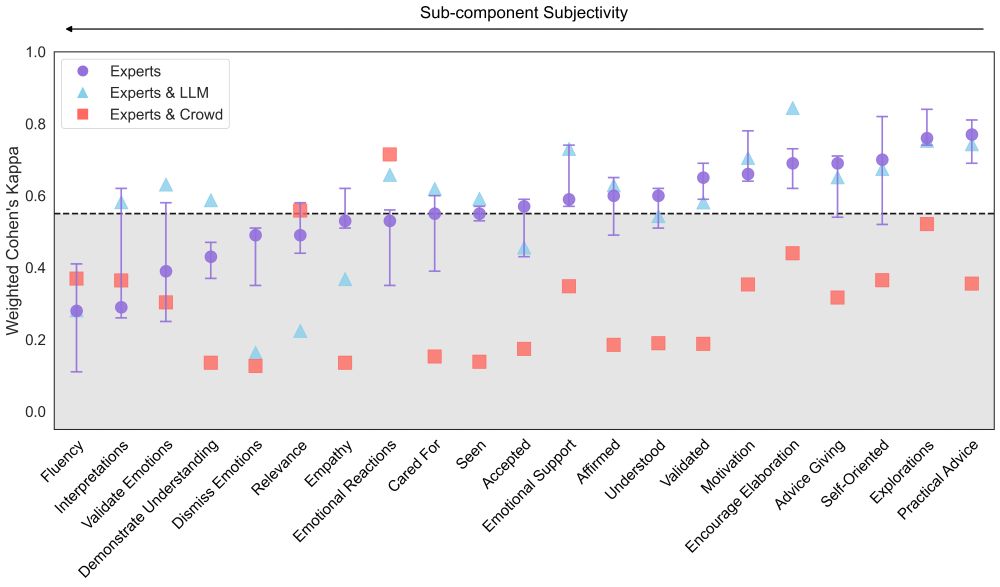
We analyzed thousands of annotations from LLMs, crowdworkers, and experts on 200 real-world conversations
And specifically looked at 21 sub-components of empathic communication from 4 evaluative frameworks
The result? LLMs consistently matched expert judgments better than crowdworkers did! 🔥
17.06.2025 15:13 — 👍 1 🔁 0 💬 1 📌 0

How do we reliably judge if AI companions are performing well on subjective, context-dependent, and deeply human tasks? 🤖
Excited to share the first paper from my postdoc (!!) investigating when LLMs are reliable judges - with empathic communication as a case study 🧐
🧵👇
17.06.2025 15:13 — 👍 4 🔁 0 💬 1 📌 1
Super cool opportunity to work with brilliant scientists and fantastic mentors @mattgroh.bsky.social and Dashun Wang 🌟🌟
Feel free to reach out!
02.04.2025 14:35 — 👍 2 🔁 0 💬 0 📌 0

Decision-Point Guided Safe Policy Improvement
Within batch reinforcement learning, safe policy improvement (SPI) seeks to ensure that the learnt policy performs at least as well as the behavior policy that generated the dataset. The core challeng...
Our paper: Decision-Point Guided Safe Policy Improvement
We show that a simple approach to learn safe RL policies can outperform most offline RL methods. (+theoretical guarantees!)
How? Just allow the state-actions that have been seen enough times! 🤯
arxiv.org/abs/2410.09361
23.01.2025 18:23 — 👍 3 🔁 1 💬 0 📌 0
Science writer and author of books including Bright Earth, The Music Instinct, Beyond Weird, How Life Works.
https://mkremins.github.io
SPSP strives to advance the study, teaching, and application of social and personality psychology. Links, Reposts ≠ endorsement. Monitored 9am ET - 5pm ET, Monday-Friday
Announcing posts for our blog.
This account is seldom monitored.
Tech, facts, and carbonara.
mantzarlis.com
CS PhD student @StanfordNLP
https://cs.stanford.edu/~shaoyj/
Cognitive scientist at Stanford. Open science advocate. Symbolic Systems Program director. Bluegrass picker, slow runner, dad. http://langcog.stanford.edu
Prof @ Wesleyan U; Co-Director of WesMediaProject (@wesmediaproject.bsky.social & mediaproject.wesleyan.edu); policomm, polisci, public opinion & health policy scholar; member of Collaborative on Media & Messaging for Health & Social Policy (commhsp.org)
I’m a reasonable man, get off my case.
sanjaysrivastava.com
Director of Education for MediaSmarts, Canada's centre for digital media literacy. He/him. Open to correction.
Assistant professor of CS at UC Berkeley, core faculty in Computational Precision Health. Developing ML methods to study health and inequality. "On the whole, though, I take the side of amazement."
https://people.eecs.berkeley.edu/~emmapierson/
NLP, ML & society, healthcare.
PhD student at Berkeley, previously CS at MIT.
https://rajivmovva.com/
Professor, Department of Psychology and Center for Brain Science, Harvard University
https://gershmanlab.com/
assoc prof, uc irvine cogsci & LPS: perception+metacognition+subjective experience, fMRI+models+AI
phil sci, education for all
2026: UCI-->UCL!
prez+co-founder, neuromatch.io
fellow, CIFAR brain mind consciousness
meganakpeters.org
she/her💖💜💙views mine
Professor of Computer Science, Stanford - HCI & Design, Co-Founder & Co-Director Stanford HAI @stanfordhai.bsky.social
https://pinchunc.github.io
Postdoc at Oxford | PhD in Cognitive Sciences & MSc in Statistics from UC Irvine | Sleep & Memory
Associate Professor focused on #collectiveintelligence and #negotiation at UCL School of Management // previously Kellogg School of Mgmt, Annenberg Penn School of Comm, Community Mediation, AmeriCorps // only following identifiable people
interested in digital ecosystems and beautiful data.
Cognitive scientist studying how we see + think @ Johns Hopkins University. 🇨🇦
Lab: https://perception.jhu.edu/
Associate Professor, Department of Psychology, Harvard University. Computation, cognition, development.




















