
Nathan Godey receiving the 2025 ATALA best thesis prize at CORIA-TALN 2025.
🏆🤩 We are excited to share the news that @nthngdy.bsky.social, supervised by @bensagot.bsky.social and Éric de la Clergerie, has received the 2025 ATALA Best PhD Dissertation Prize!
You can read his PhD online here: hal.science/tel-04994414/
17.07.2025 09:40 — 👍 9 🔁 1 💬 1 📌 0
PS: I am looking for an academic post-doc on related topics (efficiency, sparsity, sequence compression, spectral analysis of LLMs, among others), feel free to reach out if you are interested :)
06.03.2025 16:02 — 👍 3 🔁 4 💬 0 📌 0

SLLM@ICLR 2025
Workshop Summary
This work was the final touch to my PhD at @inriaparisnlp.bsky.social and was just accepted to the SLLM workshop at ICLR 2025 (sparsellm.org) 🎉
06.03.2025 16:02 — 👍 1 🔁 0 💬 1 📌 0
Thanks a lot to all my amazing co-authors @alessiodevoto.bsky.social @sscardapane.bsky.social @yuzhaouoe.bsky.social @neuralnoise.com Eric de la Clergerie @bensagot.bsky.social
And a special thanks to @edoardo-ponti.bsky.social for the academic visit that made this work possible!
06.03.2025 16:02 — 👍 2 🔁 1 💬 1 📌 0

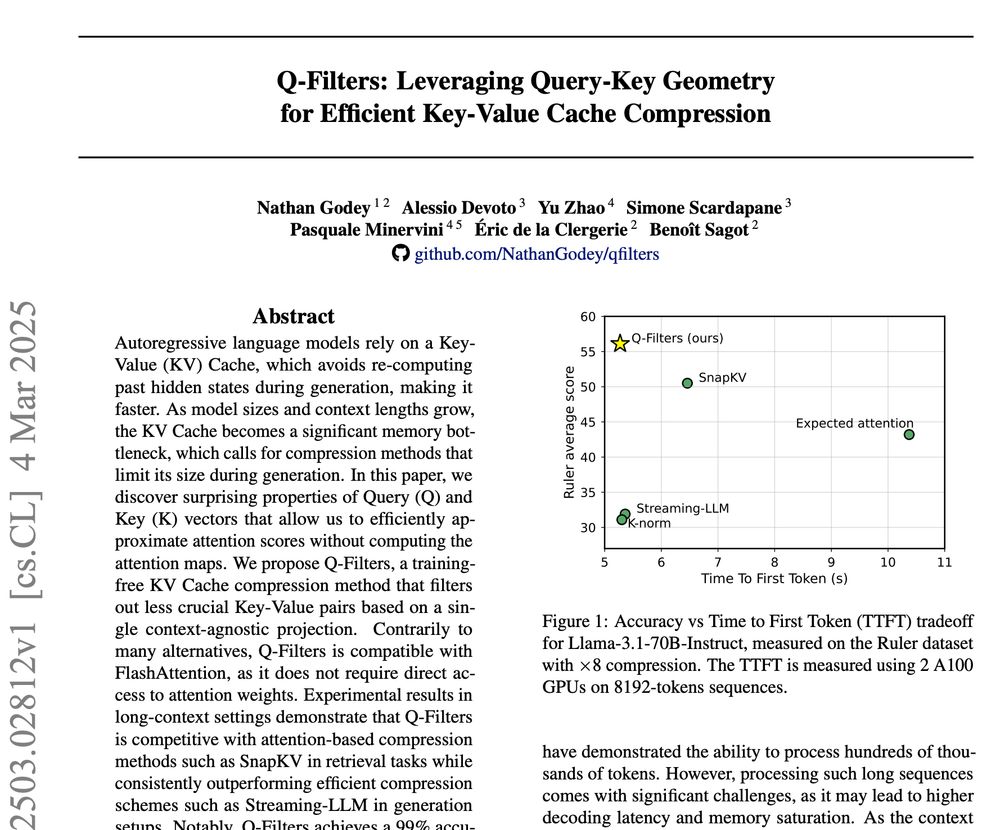
Our method is also competitive in the prompt compression setup, especially for some synthetic token retrieval tasks such as needle-in-a-haystack or variable tracking, allowing reasonable error rates with up to x32 compression ratios:
06.03.2025 16:02 — 👍 2 🔁 0 💬 1 📌 0

Q-Filters - a nthngdy Collection
Pre-computed Q-Filters for efficient KV cache compression.
This Q-Filter direction is context-agnostic, which means that it can be pre-computed once and for all for any attention head in a given model.
We release a collection of pre-computed Q-Filters for various models ranging from 1.5B to 405B parameters:
huggingface.co/collections/...
06.03.2025 16:02 — 👍 1 🔁 0 💬 1 📌 0

The projection of a Key vector on this direction strongly correlates with the averaged attention weights given to this K along generation, providing a finer KV pair ranking compared to previous work ( arxiv.org/abs/2406.11430 ):
06.03.2025 16:02 — 👍 1 🔁 0 💬 1 📌 0

Based on arxiv.org/pdf/2401.12143, we find that they share a single biased direction which encodes a selection mechanism in self-attention: K vectors with a strong component in this direction are ignored by the model.
06.03.2025 16:02 — 👍 1 🔁 0 💬 1 📌 0

We vastly improve over similar counterparts in the compress-as-you-generate scenario, where we reach similar generation throughputs while reducing the perplexity gap by up to 65% in the case of Llama-70B!
06.03.2025 16:02 — 👍 1 🔁 0 💬 1 📌 0

Q-Filters is very efficient which allows streaming compression at virtually no latency cost, just like Streaming-LLM...
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)
06.03.2025 16:02 — 👍 2 🔁 0 💬 1 📌 0
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
06.03.2025 16:02 — 👍 21 🔁 7 💬 1 📌 1
Thanks a lot to all my amazing co-authors
@alessiodevoto.bsky.social @sscardapane.bsky.social @yuzhaouoe.bsky.social @neuralnoise.com Eric de la Clergerie @bensagot.bsky.social
And a special thanks to @edoardo-ponti.bsky.social for the academic visit that made this work possible!
06.03.2025 13:40 — 👍 0 🔁 0 💬 0 📌 0
Our method is also competitive in the prompt compression setup, especially for some synthetic token retrieval tasks such as needle-in-a-haystack or variable tracking, allowing reasonable error rates with up to x32 compression ratios:
06.03.2025 13:40 — 👍 0 🔁 0 💬 1 📌 0
Q-Filters - a nthngdy Collection
Pre-computed Q-Filters for efficient KV cache compression.
This Q-Filter direction is context-agnostic, which means that it can be pre-computed once and for all for any attention head in a given model.
We release a collection of pre-computed Q-Filters for various models ranging from 1.5B to 405B parameters:
huggingface.co/collections/...
06.03.2025 13:40 — 👍 0 🔁 0 💬 1 📌 0
The projection of a Key vector on this direction strongly correlates with the averaged attention weights given to this K along generation, providing a finer KV pair ranking compared to previous work (arxiv.org/abs/2406.11430):
06.03.2025 13:40 — 👍 0 🔁 0 💬 1 📌 0
Based on arxiv.org/pdf/2401.12143, we find that they share a single biased direction which encodes a selection mechanism in self-attention: K vectors with a strong component in this direction are ignored by the model.
06.03.2025 13:40 — 👍 0 🔁 0 💬 1 📌 0
We vastly improve over similar counterparts in the compress-as-you-generate scenario, where we reach similar generation throughputs while reducing the perplexity gap by up to 65% in the case of Llama-70B!
06.03.2025 13:40 — 👍 0 🔁 0 💬 1 📌 0
Q-Filters is very efficient which allows streaming compression at virtually no latency cost, just like Streaming-LLM...
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)
06.03.2025 13:40 — 👍 1 🔁 1 💬 1 📌 0
Post-doc @ VU Amsterdam, prev University of Edinburgh.
Neurosymbolic Machine Learning, Generative Models, commonsense reasoning
https://www.emilevankrieken.com/
research scientist @ naver labs europe
Interests on bsky: ML research, applied math, and general mathematical and engineering miscellany. Also: Uncertainty, symmetry in ML, reliable deployment; applications in LLMs, computational chemistry/physics, and healthcare.
https://shubhendu-trivedi.org
ML PhD student at UT Austin
acnagle.com
Professor, Programmer in NYC.
Cornell, Hugging Face 🤗
PhD in ML/AI | Researching Efficient ML/AI (vision & language) 🍀 & Interpretability | @SapienzaRoma @EdinburghNLP | https://alessiodevoto.github.io/ | ex @NVIDIA
Researcher in ML/NLP at the University of Edinburgh (faculty at Informatics and EdinburghNLP), Co-Founder/CTO at www.miniml.ai, ELLIS (@ELLIS.eu) Scholar, Generative AI Lab (GAIL, https://gail.ed.ac.uk/) Fellow -- www.neuralnoise.com, he/they
PhD at ALMAnaCH/Inria Paris,
@aubmindlab Alumni
Interested in AI, NLP, Video Games
wissamantoun.com
Researcher in NLP in the ALMAnaCH team (Inria Paris)
ALMAnaCH, the Inria Paris NLP research team.
Directeur de recherche at Inria, former invited professor at Collège de France, co-founder of opensquare
Postdoc in ML/NLP at the University of Edinburgh.
Interested in Bottlenecks in Neural Networks; Unargmaxable Outputs.
https://grv.unargmaxable.ai/
Assistant professor in Natural Language Processing at the University of Edinburgh and visiting professor at NVIDIA | A Kleene star shines on the hour of our meeting.
PhD Student in Machine Learning | NLP & Fairness
PhD Student @ Université Paris-Saclay / Centrale Supélec, working on multimodal summarization.
seeking for a PhD research internship during summer 2025
official Bluesky account (check username👆)
Bugs, feature requests, feedback: support@bsky.app



















