
I’m pleased to share the Second Key Update to the International AI Safety Report, which outlines how AI developers, researchers, and policymakers are approaching technical risk management for general-purpose AI systems.
(1/6)

@tiancheng.bsky.social
PhD student @CambridgeLTL; Previously @DLAB @EPFL; Interested in NLP and CSS. Apple Scholar, Gates Scholar.
I’m pleased to share the Second Key Update to the International AI Safety Report, which outlines how AI developers, researchers, and policymakers are approaching technical risk management for general-purpose AI systems.
(1/6)
Personalization certainly needs boundaries and we show how that could look like!
31.10.2025 17:24 — 👍 0 🔁 0 💬 0 📌 0Great fun working on this with @bminixhofer.bsky.social and Prof. Collier at @cambridgeltl.bsky.social.
Special thanks to Paul Martin, and Arcee AI's Mergekit library.

TL;DR: The alignment-calibration trade-off is real, but you don't have to be stuck with the endpoints.
Model merging provides a simple, powerful dial to find the perfect balance of capability and reliability for YOUR application.
Paper here: arxiv.org/abs/2510.17426 (8/8)

Better calibration has benefits beyond accuracy scores. It helps reduce "mode collapse" in generation tasks, leading to more diverse generations (and higher utility too), as measured on NoveltyBench. It improves model performance on group-level simulation tasks too! (7/8)
30.10.2025 17:00 — 👍 0 🔁 0 💬 1 📌 0
And it gets better with scale! 📈
The benefits of merging, both the accuracy boost and the stability of the "sweet spot", become even more pronounced in larger, more capable models. This echoes prior work which shows merging bigger models are more effective and stable. (6/8)

The Pareto-superior frontier is a general phenomenon we observe across model families (Gemma, Qwen), sizes, and datasets, where we can consistently find a better-balanced model. We show Qwen 2.5 results on BBH and MMLU-Pro below. (5/8)
30.10.2025 17:00 — 👍 0 🔁 0 💬 1 📌 0
It's NOT a zero-sum game between base and instruct.
We find a "sweet spot" merge that is Pareto-superior: it has HIGHER accuracy than both parents while substantially restoring the calibration lost during alignment. (4/8)

Our solution is simple and computationally cheap: model merging.
By interpolating between the well-calibrated base model and its capable but overconfident instruct counterpart, we create a continuous spectrum to navigate this trade-off. No retraining needed.
(3/8)

Let's start by redefining the problem. We argue the "alignment tax" MUST include the severe loss of model calibration.
Instruction tuning doesn't just nudge performance; it wrecks calibration, causing a huge spike in overconfidence. (2/8)
Instruction tuning unlocks incredible skills in LLMs, but at a cost: they become dangerously overconfident.
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
River, Yinhong and I will all be in person and we look forward to the discussions!
29.10.2025 21:12 — 👍 3 🔁 1 💬 0 📌 0
See you next week at EMNLP!
We will be presenting our work: Scaling Low-Resource MT via Synthetic Data Generation with LLMs
📍 Poster Session 13
📅 Fri, Nov 7, 10:30-12:00 - Hall C
📖 Check it out! arxiv.org/abs/2505.14423
@helsinki-nlp.bsky.social @cambridgenlp.bsky.social @emnlpmeeting.bsky.social
Huge thanks to my amazing collaborators @joachimbaumann.bsky.social @Lorenzo Lupo @nigelcollier.bsky.social @dirkhovy.bsky.social and especially @paul-rottger.bsky.social
@cambridgeltl.bsky.social
Work partially done during my visit to @milanlp.bsky.social. Highly recommended!

Check out the paper and data for details!
Paper: arxiv.org/abs/2510.17516
Data: huggingface.co/datasets/pit...
Website: simbench.tiancheng.hu (9/9)
Overall, by making progress measurable, SImBench provides the foundation to build more faithful LLM simulators.
Moving forward, we should work on better training strategies for improving LLM social simulators. These will most likely diverge from advances in chat / coding models. (8/9)
We find simulation ability correlates most strongly with deep, knowledge-intensive general reasoning (MMLU-Pro, r=0.94), rather than competition math (AIME, r=0.48)
To simulate humans well, a model needs a broad, nuanced understanding of the world. (7/9)
Why does this happen? We dug deeper and found two opposing forces:
✅ a helpful direct effect (+6.46 score): models get much better at following instructions
❌ a harmful indirect effect (-1.74 score): models become less diverse
The challenge: how do we get the good without the bad? (6/9)
This echos findings in the calibration literature: currently alignment algorithms typically optimize for the single best answer (improving pass@1), causing overconfidence at the expense of the full distribution.
28.10.2025 16:53 — 👍 2 🔁 0 💬 1 📌 0
There’s also an alignment-simulation tradeoff:
Instruction-tuning (the process that makes LLMs helpful and safe) improves their ability to predict consensus opinions.
BUT, it actively harms their ability to predict diverse, pluralistic opinions where humans disagree. (5/9)

We found a clear log-linear scaling trend.
Across the model families we could test, bigger models are consistently better simulators. Performance reliably increases with model size. This suggests that future, larger models hold the potential to become highly accurate simulators. (4/9)

The best model we tested on release, Claude 3.7 Sonnet, scores just 40.8 out of 100. A lot of room for improvement for LLM social simulators! Interestingly, more test-time compute doesn’t help. This suggests that simulation requires a different type of reasoning than math / coding. (3/9)
28.10.2025 16:53 — 👍 3 🔁 0 💬 1 📌 0 28.10.2025 16:53 — 👍 3 🔁 1 💬 1 📌 0
28.10.2025 16:53 — 👍 3 🔁 1 💬 1 📌 0
SimBench is a big, unified benchmark built from 20 diverse datasets with a global participant pool.
It spans moral dilemmas, economic games, psych assessments & more to rigorously test how well LLMs can predict group-level human responses across a wide range of tasks. (2/9)
Can AI simulate human behavior? 🧠
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
Excited to share a "Key Update" from the International AI Safety Report, which I was proud to contribute to.
We took a rigorous, evidence-based look at the latest AI developments. If you want a clear view of where things stand, this is a must-read. 👇
SimBench: Benchmarking the Ability of Large
Language Models to Simulate Human Behaviors, SRW Oral, Monday, July 28, 14:00-15:30
I will be presenting:
iNews: A Multimodal Dataset for Modeling Personalized Affective Responses to News, Poster Session 1, Monday, July 28, 11:00-12:30; Also at LAW workshop
Heading to Vienna today to attend #ACL2025NLP! Let's chat if you are interested in LLM social simulation, personalization, character training and human-centered AI!
26.07.2025 11:21 — 👍 3 🔁 0 💬 1 📌 0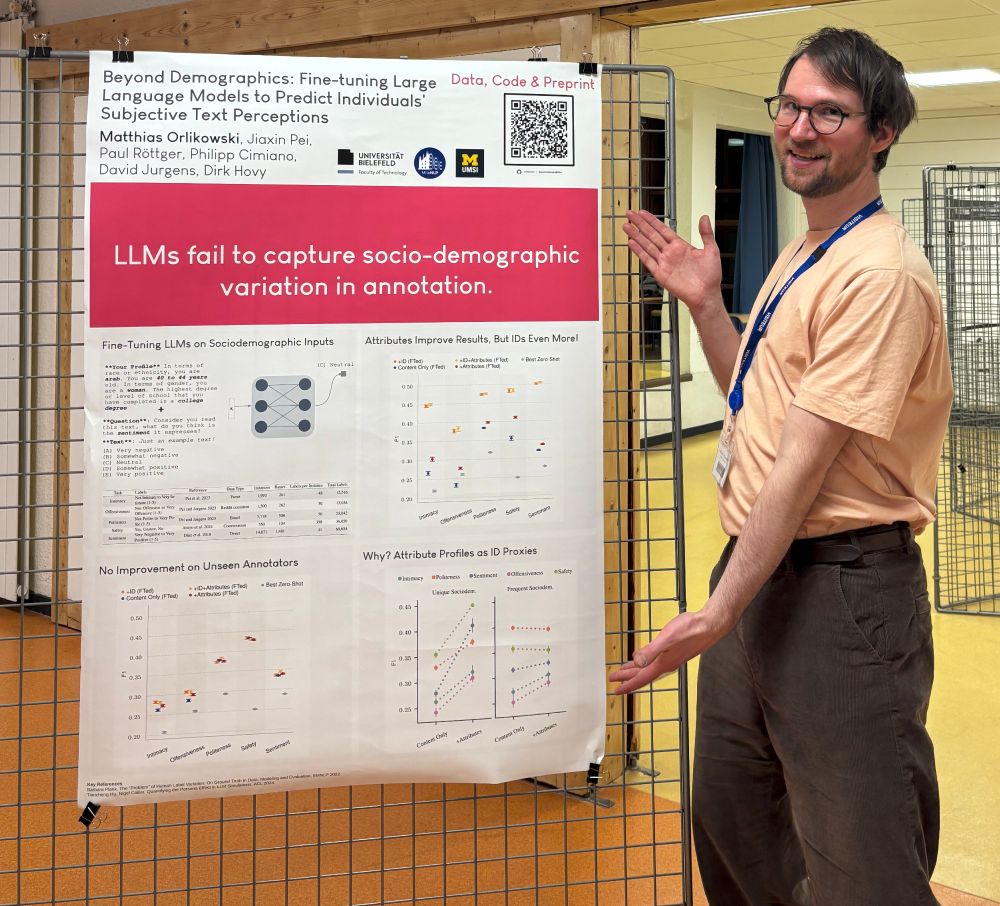
Picture of Matthias Orlikowski presenting a poster on the paper titled "Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals’ Subjective Text Perceptions". The poster is similar to the one that will be presented at ACL 2025, showing a number of figures about the key results.
I will be at #acl2025 to present "Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals’ Subjective Text Perceptions" ✨
Huge thank you to my collaborators Jiaxin Pei @paul-rottger.bsky.social Philipp Cimiano @davidjurgens.bsky.social @dirkhovy.bsky.social 🍰
more below





















