
🧠🔍 Can deep models be verifiably right for the right reasons?
At ICML’s Actionable Interpretability Workshop, we present Neural Concept Verifier—bringing Prover–Verifier Games to concept space.
📅 Poster: Sat, July 19
📄 arxiv.org/abs/2507.07532
#ICML2025 #XAI #NeuroSymbolic
13.07.2025 10:44 — 👍 5 🔁 0 💬 0 📌 0

Can concept-based models handle complex, object-rich images? We think so! Meet Object-Centric Concept Bottlenecks (OCB) — adding object-awareness to interpretable AI. Led by David Steinmann w/ @toniwuest.bsky.social & @kerstingaiml.bsky.social .
📄 arxiv.org/abs/2505.244...
#AI #XAI #NeSy #CBM #ML
07.07.2025 15:55 — 👍 10 🔁 4 💬 0 📌 0
🚨 New #ICML2025 paper!
"Bongard in Wonderland: Visual Puzzles that Still Make AI Go Mad?"
We test Vision-Language Models on classic visual puzzles—and even simple concepts like “spiral direction” or “left vs. right” trip them up. Big gap to human reasoning remains.
📄 arxiv.org/pdf/2410.19546
07.05.2025 13:39 — 👍 17 🔁 3 💬 0 📌 0
Work together with my amazing co-authors @philosotim.bsky.social
Lukas Helff @ingaibs.bsky.social @wolfstammer.bsky.social @devendradhami.bsky.social @c-rothkopf.bsky.social @kerstingaiml.bsky.social ! ✨
02.05.2025 08:00 — 👍 4 🔁 1 💬 0 📌 0


🔥Our work “Where is the Truth? The Risk of Getting Confounded in a Continual World" was accepted with a spotlight poster at ICML!
arxiv.org/abs/2402.06434
-> we introduce continual confounding + the ConCon dataset, where confounders over time render continual knowledge accumulation insufficient ⬇️
02.05.2025 09:48 — 👍 10 🔁 3 💬 2 📌 1

I am happy to share that my dissertation is now officially available online!
Feel free to take a look :) tuprints.ulb.tu-darmstadt.de/29712/
14.04.2025 19:01 — 👍 4 🔁 0 💬 0 📌 0

Sanity Checks for Saliency Maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, Been Kim
Saliency methods have emerged as a popular tool to highlight features in an input deemed relevant for the prediction of a learned model. Several saliency methods have been proposed, often guided by visual appeal on image data. In this work, we propose an actionable methodology to evaluate what kinds of explanations a given method can and cannot provide. We find that reliance, solely, on visual assessment can be misleading. Through extensive experiments we show that some existing saliency methods are independent both of the model and of the data generating process. Consequently, methods that fail the proposed tests are inadequate for tasks that are sensitive to either data or model, such as, finding outliers in the data, explaining the relationship between inputs and outputs that the model learned, and debugging the model. We interpret our findings through an analogy with edge detection in images, a technique that requires neither training data nor model. Theory in the case of a linear model and a single-layer convolutional neural network supports our experimental findings.

Sparse Autoencoders Can Interpret Randomly Initialized Transformers
Thomas Heap, Tim Lawson, Lucy Farnik, Laurence Aitchison
Sparse autoencoders (SAEs) are an increasingly popular technique for interpreting the internal representations of transformers. In this paper, we apply SAEs to 'interpret' random transformers, i.e., transformers where the parameters are sampled IID from a Gaussian rather than trained on text data. We find that random and trained transformers produce similarly interpretable SAE latents, and we confirm this finding quantitatively using an open-source auto-interpretability pipeline. Further, we find that SAE quality metrics are broadly similar for random and trained transformers. We find that these results hold across model sizes and layers. We discuss a number of number interesting questions that this work raises for the use of SAEs and auto-interpretability in the context of mechanistic interpretability.
2018: Saliency maps give plausible interpretations of random weights, triggering skepticism and catalyzing the mechinterp cultural movement, which now advocates for SAEs.
2025: SAEs give plausible interpretations of random weights, triggering skepticism and ...
03.03.2025 18:42 — 👍 95 🔁 15 💬 2 📌 0
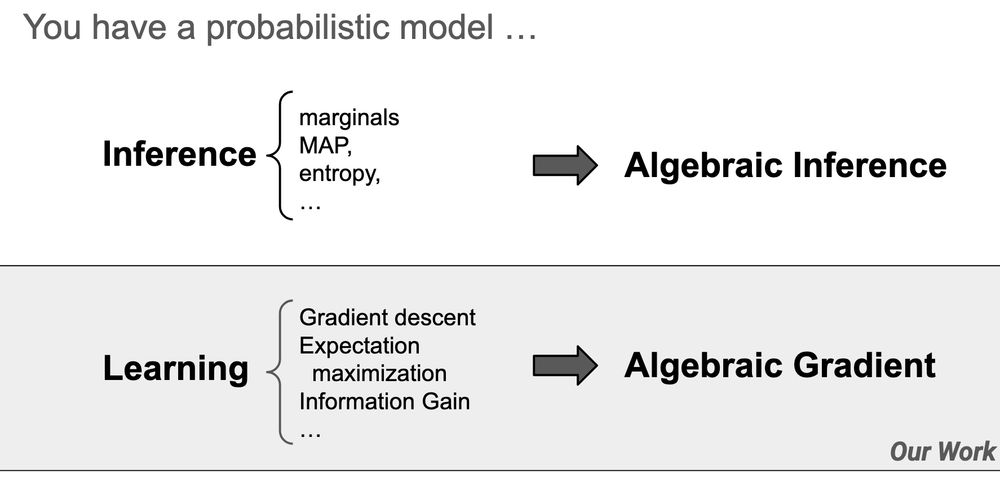
We all know backpropagation can calculate gradients, but it can do much more than that!
Come to my #AAAI2025 oral tomorrow (11:45, Room 119B) to learn more.
27.02.2025 23:45 — 👍 27 🔁 10 💬 1 📌 0


Happy to share that I successfully defended my PhD on Feb 19th with distinction! My work on "The Value of Symbolic Concepts for AI Explanations and Interactions" has been a rewarding journey. Huge thanks to my mentors, peers, and committee for their support! Excited for what’s next! 🚀
24.02.2025 21:01 — 👍 16 🔁 0 💬 3 📌 0




















