Very happy that @PNASNews agreed to publish our (w/ @romanececchi.bsky.social) response to Prakhar's thought-provoking study! You can find the final version at the link below. See the following tweet for Prakhar's response to our response. Happy to hear your thoughts!
www.pnas.org/doi/10.1073/...
03.02.2026 20:41 —
👍 19
🔁 6
💬 1
📌 0
Thanks for the kind mention @nclairis.bsky.social ! And congrats to the authors – really interesting to see mood being explored across species
30.04.2025 17:18 —
👍 2
🔁 0
💬 0
📌 0
OSF
9/9 🙌 Huge thanks to @sgluth.bsky.social & @stepalminteri.bsky.social!
📄 Read the full preprint: doi.org/10.31234/osf...
💬 Feedback and discussion welcome!
#reinforcementlearning #attention #computationalneuroscience #eyetracking
🧵/end
22.04.2025 16:57 —
👍 4
🔁 0
💬 0
📌 0
8/9 🎯 Conclusion
Attention doesn’t just follow value – it shapes it.
We showed that:
👁️ Gaze during learning causally biases value encoding
⏱️ Stimulus-directed attention sets the stage for processing the outcomes
🧩 Our model offers a mechanistic account of why mid-value options are undervalued in RL
22.04.2025 16:57 —
👍 1
🔁 0
💬 1
📌 0

7/9 ⏱️ When does attention matter?
🏆 Best fit? The stimulus-only model – consistent across experiments.
➕ Complemented by fine-grained gaze analysis:
👉 Value computation relies mainly on fixations during stimulus presentation, with minimal contribution from outcome-related fixations.
22.04.2025 16:57 —
👍 1
🔁 0
💬 1
📌 0
6/9 🧩 Modeling attention in value learning
We formalized these findings in an attentional range model, where visual fixations modulate absolute value before range normalization.
We tested 3 versions using:
• Only stimulus fixations
• Only outcome fixations
• A weighted combination
22.04.2025 16:57 —
👍 3
🔁 0
💬 1
📌 0
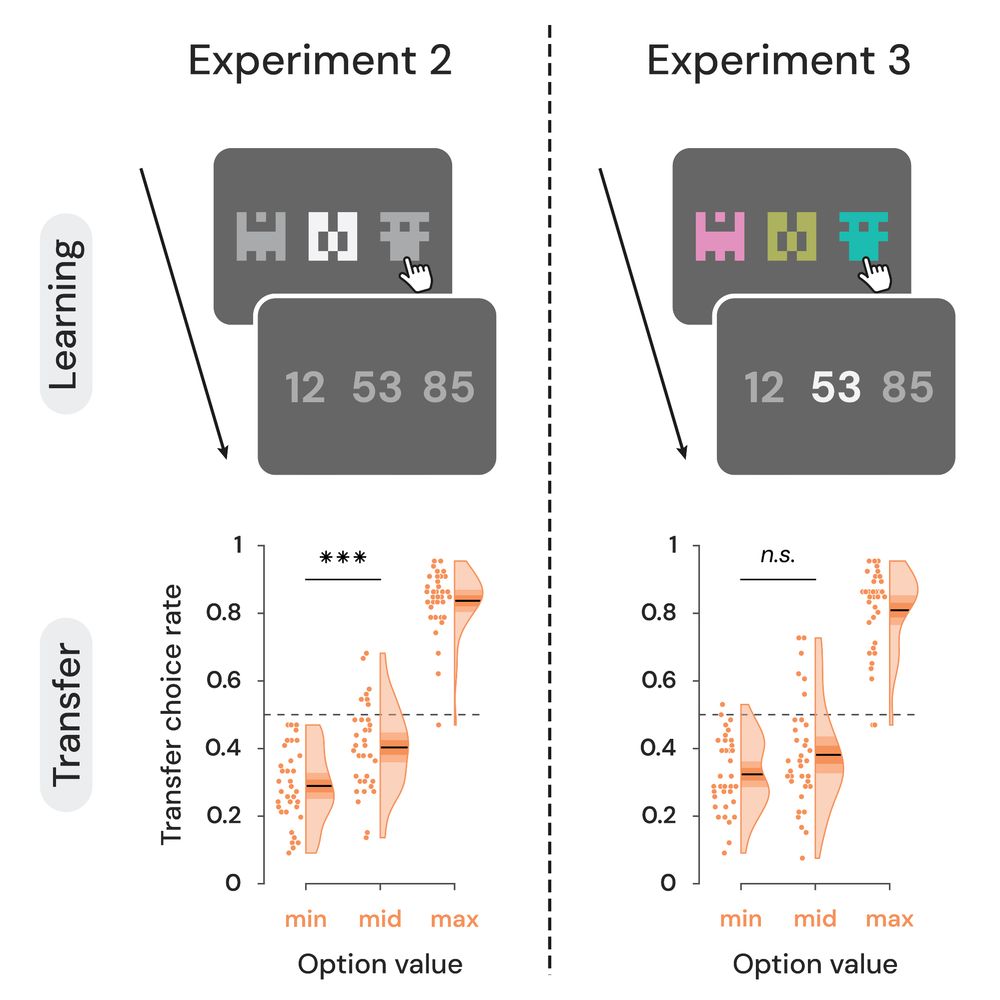
5/9 ⬆️ Exp 2 & 3: Bottom-up manipulation
We used saliency to guide gaze to the mid-value option:
• Exp 2: Salient stimulus → higher valuation in transfer
• Exp 3: Salient outcome → no significant effect
👉 Only attention to stimuli during learning influenced value formation
22.04.2025 16:57 —
👍 1
🔁 0
💬 1
📌 0

4/9 ⬇️ Exp 1: Top-down manipulation
We made the high-value option unavailable on some trials – forcing attention to the mid-value one.
Result: participants looked more at the mid-value option – and later valued it more.
👉 Attention during learning altered subjective valuation.
22.04.2025 16:57 —
👍 1
🔁 0
💬 1
📌 0

3/9 Design
We ran 3️⃣ eye-tracking RL experiments, combining:
• A 3-option learning phase with full feedback
• A transfer test probing generalization & subjective valuation
Crucially, we manipulated attention via:
• Top-down control (Exp 1)
• Bottom-up saliency (Exp 2 & 3)
22.04.2025 16:57 —
👍 1
🔁 0
💬 1
📌 0
2/9 💡 Hypothesis
Could attention be the missing piece?
Inspired by the work of @krajbichlab.bsky.social, @yaelniv.bsky.social, @thorstenpachur.bsky.social and others, we asked:
👉 Does where we look during learning causally shape how we encode value?
22.04.2025 16:57 —
👍 2
🔁 0
💬 1
📌 0

1/9 🎨 Background
When choosing, people don’t evaluate options in isolation – they normalize values to context.
This holds in RL... but in three-option settings, people undervalue the mid-value option – something prior models fail to explain (see @sophiebavard.bsky.social).
❓Why the distortion?
22.04.2025 16:57 —
👍 1
🔁 0
💬 1
📌 0
OSF
🧵 New preprint out!
📄 "Elucidating attentional mechanisms underlying value normalization in human reinforcement learning"
👁️ We show that visual attention during learning causally shapes how values are encoded
w/ @sgluth.bsky.social & @stepalminteri.bsky.social
🔗 doi.org/10.31234/osf...
22.04.2025 16:57 —
👍 16
🔁 6
💬 1
📌 1

Epistemic biases in human reinforcement learning: behavioral evidence, computational characterization, normative status and possible applications.
A quite self-centered review, but with a broad introduction and conclusions and very cool figures.
Few main takes will follow
osf.io/preprints/ps...
23.01.2025 15:47 —
👍 38
🔁 19
💬 1
📌 0
New preprint! 🚨
Performance of standard reinforcement learning (RL) algorithms depends on the scale of the rewards they aim to maximize.
Inspired by human cognitive processes, we leverage a cognitive bias to develop scale-invariant RL algorithms: reward range normalization.
Curious? Have a read!👇
10.12.2024 18:02 —
👍 14
🔁 7
💬 1
📌 1
OSF
🚨New preprint alert!🚨
Achieving Scale-Invariant Reinforcement Learning Performance with Reward Range Normalization.
Where we show that things we discover in psychology can be useful for machine learning.
By the amazing
@maevalhotellier.bsky.social and Jeremy Perez.
doi.org/10.31234/osf...
05.12.2024 15:22 —
👍 23
🔁 10
💬 1
📌 0
