I’m really excited about Diffusion Steering Lens, an intuitive and elegant new “logit lens” technique for decoding the attention and MLP blocks of vision transformers!
Vision is much more expressive than language, so some new mech interp rules apply:
25.04.2025 13:36 — 👍 11 🔁 3 💬 0 📌 0


We also validated DSL’s reliability through two interventional studies (head importance correlation & overlay removal). Check out our paper for details!
(6/7)
25.04.2025 09:37 — 👍 0 🔁 0 💬 1 📌 0

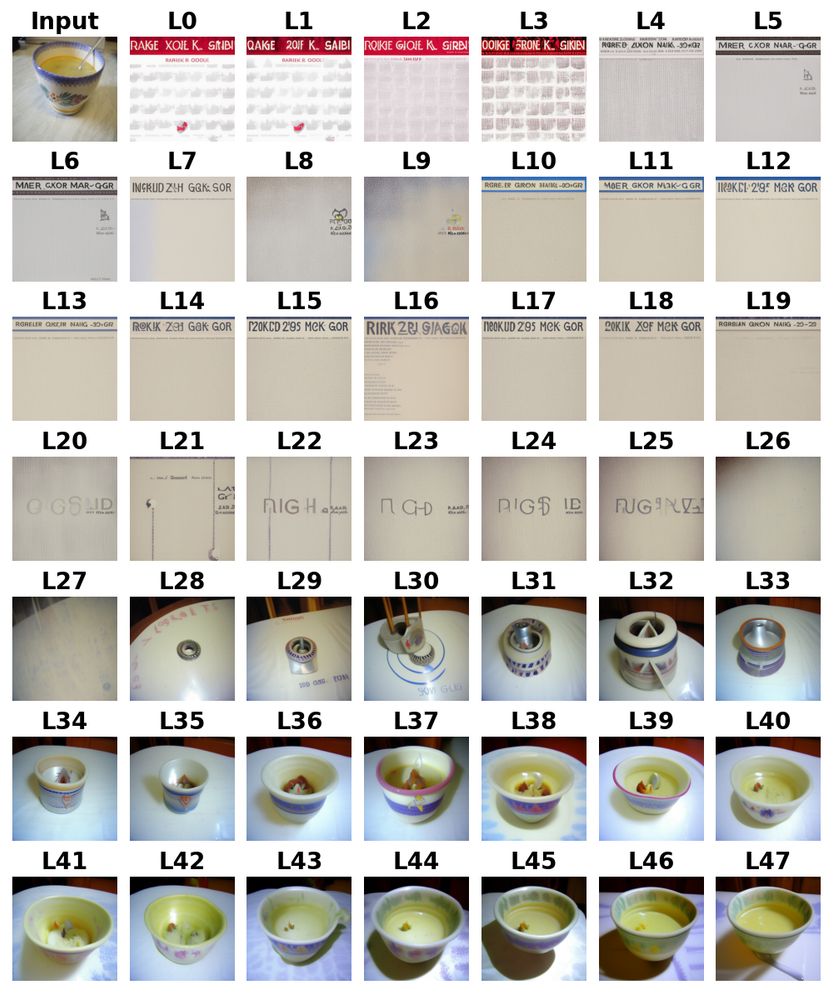
Below are the top-10 head DSL visualizations by similarity to the input, consistent with residual-stream visualizations from Diffusion Lens.
(5/7)
25.04.2025 09:37 — 👍 0 🔁 0 💬 1 📌 0

To fix this, we propose Diffusion Steering Lens (DSL), a training-free method that steers a specific submodule’s output, patches its subsequent indirect contributions, and then decodes it with the diffusion model.
(4/7)
25.04.2025 09:37 — 👍 0 🔁 0 💬 1 📌 0

We first adapted Diffusion Lens (Toker et al., 2024) to decode residual streams in the Kandinsky 2.2 image encoder (CLIP ViT-bigG/14) via the diffusion model.
We can visualize how the predictions evolve through layers, but individual head contributions stay largely hidden.
(3/7)
25.04.2025 09:37 — 👍 0 🔁 0 💬 1 📌 0
Classic Logit Lens projects residual streams to the output space. It works surprisingly well on ViTs, but visual representations are far richer than class labels.
www.lesswrong.com/posts/kobJym...
(2/7)
25.04.2025 09:37 — 👍 0 🔁 0 💬 1 📌 0
🔍Logit Lens tracks what transformer LMs “believe” at each layer. How can we effectively adapt this approach to Vision Transformers?
Happy to share our “Decoding Vision Transformers: the Diffusion Steering Lens” was accepted at the CVPR 2025 Workshop on Mechanistic Interpretability for Vision!
(1/7)
25.04.2025 09:37 — 👍 5 🔁 0 💬 1 📌 1
hello world
24.04.2025 07:01 — 👍 2 🔁 0 💬 0 📌 0
29th Annual Meeting of the Association for the Scientific Study of Consciousness. Santiago de Chile June 30-July 3 #ASSC29
ERC Research Fellow at the Sussex Centre for Consciousness Science (Anil Seth’s lab)
I'm a scientist at Tufts University; my lab studies anatomical and behavioral decision-making at multiple scales of biological, artificial, and hybrid systems. www.drmichaellevin.org
Postdoctoral Research Fellow at SCCS, University of Sussex| Cognitive science, time and consciousness
Account of the Editors of Neuroscience of Consciousness
https://academic.oup.com/nc
Athena Demertzi (co-EiC) @ademertzi
Thomas Andrillon (co-EiC) @thomasandrillon
Ben Kozuch (DepEd) @benjikozuch
Florence G. Kline Prof & Curators’ Distinguished Prof @ MU. Barwise Prize winner. Author, Neurocognitive Mechanisms (OUP 2020). Resist fascism, address climate change, support Ukraine!
I post mainly about Neuroscience, Machine Learning, Complex Systems, or Stats papers.
Working on neural learning /w @auksz.bsky.social CCNB/BCCN/Free University Berlin.
I also play bass in a pop punk band:
https://linktr.ee/goodviewsbadnews
Assistant Prof at VU Amsterdam. Neuroscience of consciousness, decision making. Computational modeling. Pet method: EEG. Critical of subjective measures. Co-PI in the http://consciousbrainlab.com with @svangaal.bsky.social and @timostein.bsky.social.
Neuroscience,Insular cortex
I do not reply to direct messages
Twitter @leafs_s
mastdon @leafs_s@mstdn.science
I make sure that OpenAI et al. aren't the only people who are able to study large scale AI systems.
Professor at Wharton, studying AI and its implications for education, entrepreneurship, and work. Author of Co-Intelligence.
Book: https://a.co/d/bC2kSj1
Substack: https://www.oneusefulthing.org/
Web: https://mgmt.wharton.upenn.edu/profile/emollick
Waiting on a robot body. All opinions are universal and held by both employers and family. ML/NLP.
Professor Cognitive Psychologist at UMass Dartmouth. She focuses: embodied cognition and Learning
Free access:
https://direct.mit.edu/books/oa-edited-volume/5306/Movement-MattersHow-Embodied-Cognition-Informs
https://embodiedcognitionandlearning.com/
#NLP Postdoc at Mila - Quebec AI Institute & McGill University
mariusmosbach.com
Researcher at Google and CIFAR Fellow, working on the intersection of machine learning and neuroscience in Montréal (academic affiliations: @mcgill.ca and @mila-quebec.bsky.social).
Mostly 3D+AI+voice. Building https://mixreel.ai
Flutter/Dart/C++/PyTorch/Blender
https://github.com/nmfisher/thermion
https://nick-fisher.com
https://playmixworld.com
https://bit.ly/3RkzFfH
ML, λ • language and the machines that understand it • https://ocramz.github.io
Brain, minds, & consciousness. Also interested in design, visual arts, biology, space, typography, and anticipation. Also known as « Axel from Belgium »





















