ClickHouse permission tweak + a missing SQL filter → ML feature pipeline down → the internet breaks 🤔
Another case supporting Taleb’s thesis that the world has become more fragile
Other examples that come to mind: the Amazon outage last month and the CrowdStrike-related outage last year
19.11.2025 07:39 — 👍 0 🔁 0 💬 1 📌 0
P.S. Paying to apply may sound provocative and require thoughtful consideration and careful testing. But here, I focus on why price signals may address this problem better than AI-based screening.
24.10.2025 09:21 — 👍 0 🔁 0 💬 0 📌 0
Then I asked myself what this solution has that AI doesn't. That’s how I arrived at the analogy that prices act as model weights: they encode market information. An important difference: prices incorporate signals from dispersed, hard-to-observe data that an AI/ML model may not access.
24.10.2025 06:34 — 👍 0 🔁 0 💬 1 📌 0
Prices as model weights: learning from dispersed data | Evgeny Ivanov
Market design to reduce labor market congestion.
I was thinking about the labor market congestion problem and came up with a solution that is often used in service marketplaces: pay to apply... 🧵
24.10.2025 06:33 — 👍 0 🔁 0 💬 1 📌 0
Another perspective on marshmallow test: market risk and diminishing marginal utility
10.10.2025 07:31 — 👍 2 🔁 0 💬 0 📌 0
In NotebookLM, the output language is global. A per-notebook setting would be much more convenient
31.08.2025 07:02 — 👍 0 🔁 0 💬 0 📌 0
As a non-native English speaker, I don’t want YouTube auto-translating titles, chapters, and descriptions; I want the originals
31.08.2025 07:02 — 👍 0 🔁 0 💬 1 📌 0
It’s astonishing that Google employs so many multilingual people yet designs products as if users speak only one language
31.08.2025 07:01 — 👍 2 🔁 0 💬 1 📌 0
Some mentions of the quote "all models are wrong, but some are useful" should be followed by "the map is not the territory"
17.07.2025 16:03 — 👍 0 🔁 0 💬 0 📌 0

We wanted flying cars, instead we got scooter riders honking at our backs and knocking us off our feet
02.07.2025 07:49 — 👍 0 🔁 0 💬 0 📌 0
Pre-LLM era take-home assignments: focus on evaluating *answers*; LLM era: focus on evaluating *questions*.
"Here is the problem-solving case: […]. Use an LLM to solve it. Provide a summary of your conversation with the LLM, including the questions you asked and the final solution you obtained."
26.05.2025 10:03 — 👍 1 🔁 0 💬 0 📌 0
Every relevant cost can ultimately be framed as an opportunity cost. So, in essence, opportunity cost is the only cost that matters.
13.05.2025 13:01 — 👍 0 🔁 0 💬 0 📌 0
In statistics, answering a wrong question is sometimes called a Type III error. I've already mentioned it in a blog post: e10v.me/ranking-two-...
12.05.2025 12:37 — 👍 0 🔁 0 💬 0 📌 0
From my personal experience, people often skip steps 1 and 3, which can lead to bad decisions or mediocre solutions.
You probably read this in a statistical or data-analysis context. But I believe the framework applies more broadly.
12.05.2025 12:36 — 👍 0 🔁 0 💬 1 📌 0
...
4. What data do we need to apply the model?
5. What conclusions can we draw after applying the model?
12.05.2025 12:36 — 👍 0 🔁 0 💬 1 📌 0
A ladder of questions in analysis:
1. Which question should we ask to address a decision or a problem?
2. Which model should we choose to answer the question?
3. Which assumptions must hold for the model to be valid, and do they hold?
... 🧵
#DecisionIntelligence #ModelThinking #Logic
12.05.2025 12:35 — 👍 0 🔁 0 💬 1 📌 0
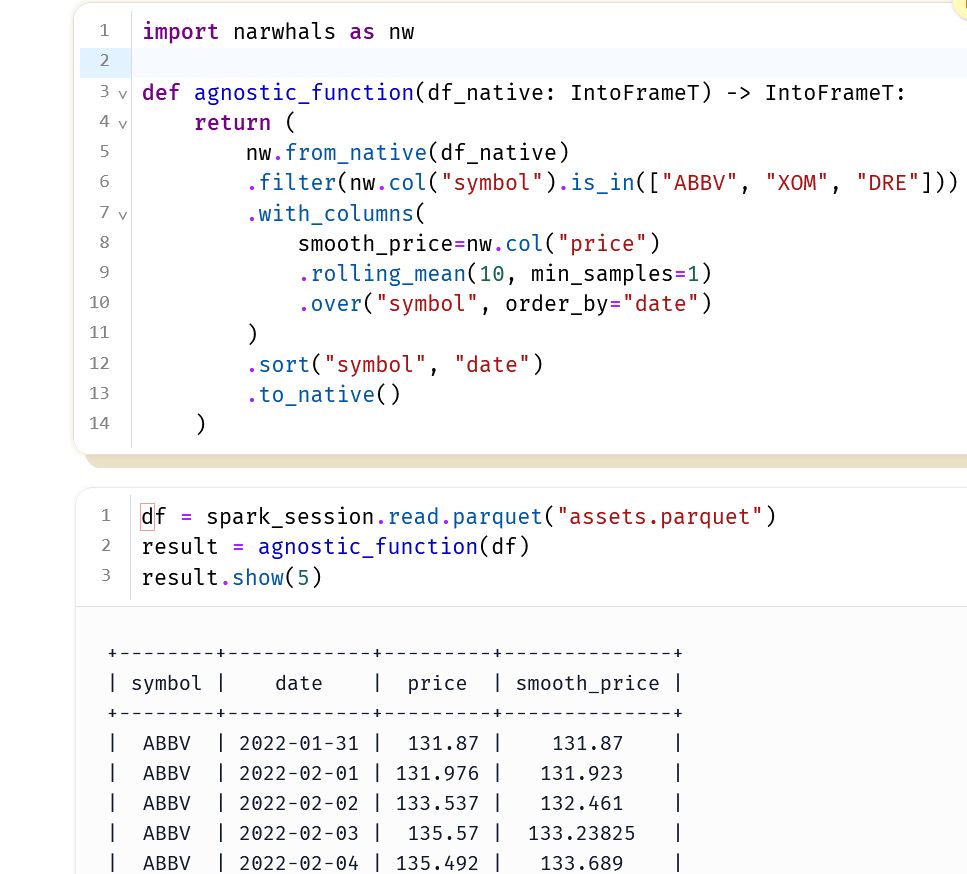
Demo of Narwhals dataframe-agnostic function which supports PySpark
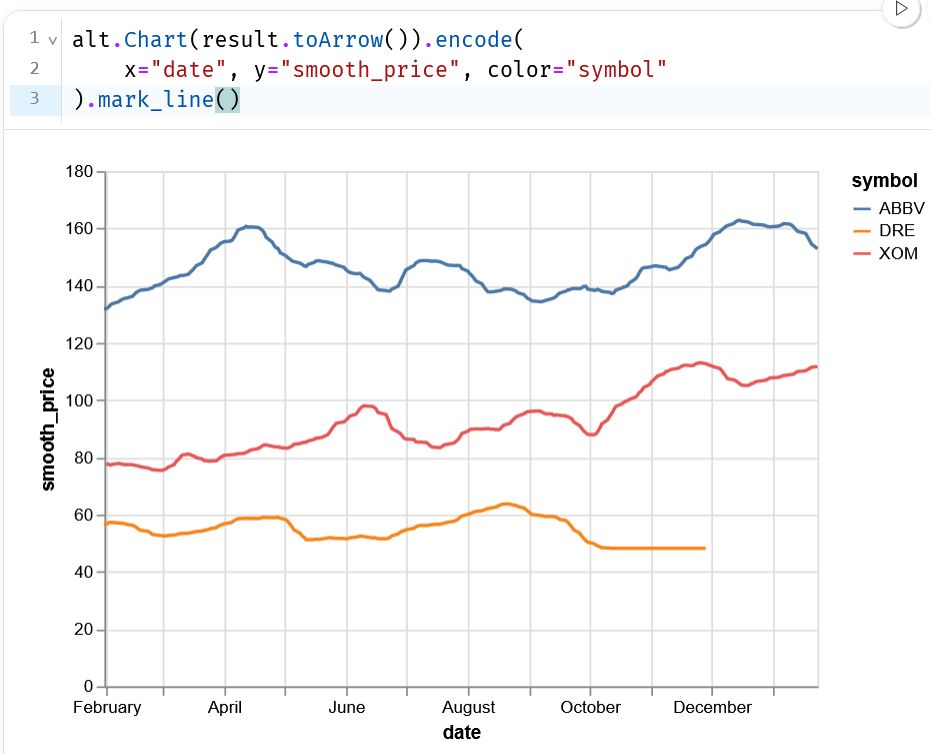
Plot of PySpark dataframe after converting it to PyArrow
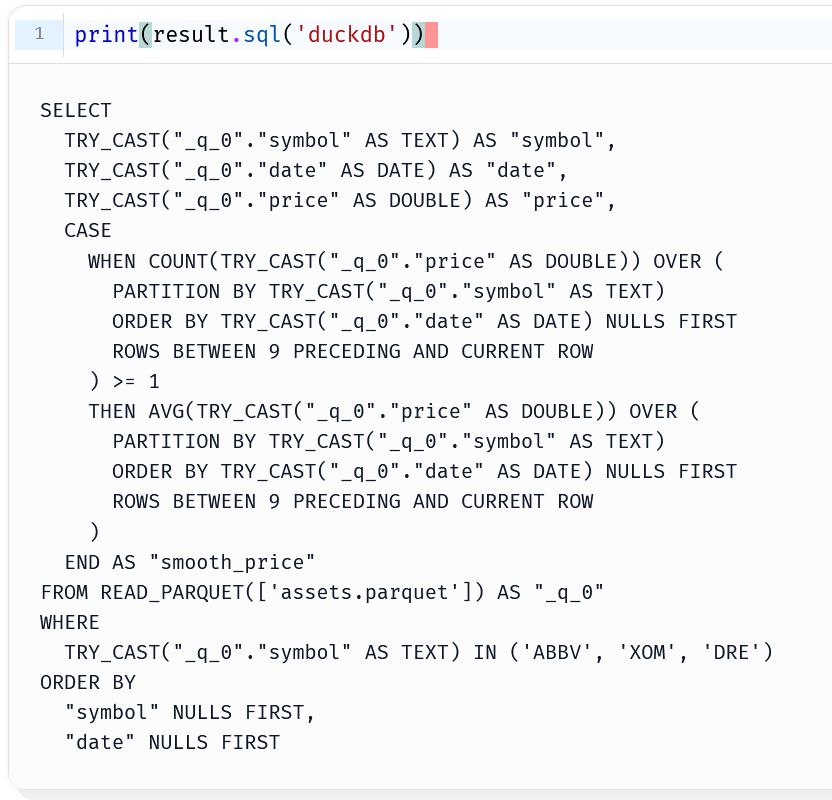
SQL generation from Polars syntax
✨ Narwhals now supports PySpark
🎇 If you have a dataframe-agnostic function, you can pass in `pyspark.sql.DataFrame`
📈 Here's a demo, made with @marimo.io
🎁 BONUS feature: combine with SQLFrame, to generate SQL from @pola.rs syntax 🪄
09.05.2025 13:41 — 👍 1 🔁 1 💬 0 📌 0
A/A tests are useful for identifying potential issues before conducting the actual A/B test. Treatment simulations are great for power analysis—especially when you need a specific uplift distribution or when an analytical formula doesn’t exist.
05.05.2025 13:43 — 👍 0 🔁 0 💬 1 📌 0
@marimo.io is not only a great tool for reproducible and interactive research—it's also perfect for interactive documentation where users can play with examples. You can run them as WASM notebooks entirely in your browser—no local setup needed. I personally love marimo's attention to detail.
05.05.2025 13:43 — 👍 0 🔁 0 💬 1 📌 0
The version 1.0 of tea-tasting, a Python package for the statistical analysis of A/B tests, is now available. Notable improvements:
- Interactive user guides built with @marimo_io notebooks.
- Simulated experiments, including A/A tests.
#abtesting #statistics #datascience
05.05.2025 13:42 — 👍 0 🔁 0 💬 1 📌 0

Wow, ChatGPT is really smart now 😜
But better check for yourself: github.com/e10v/tea-tas...
#abtesting #statistics #chatgpt #ai
31.03.2025 09:14 — 👍 0 🔁 0 💬 0 📌 0
It's actually Cunningham's Law... Wait... Dammit!
26.12.2024 15:10 — 👍 2 🔁 0 💬 1 📌 0
Does atom count?
e10v.me/atom.xml
15.12.2024 07:06 — 👍 1 🔁 0 💬 1 📌 0
And at least one package from the long tail now also uses Narwhals under-the-hood (tea-tasting)
14.12.2024 22:08 — 👍 1 🔁 0 💬 0 📌 0
How's your work on the new streaming engine? Can't wait to try it.
04.12.2024 20:14 — 👍 0 🔁 0 💬 0 📌 0
Another improvement is that columns are now cast to float before aggregation by variant, which is important for PostgreSQL and databases based on PostgreSQL like Greenplum.
02.12.2024 13:00 — 👍 0 🔁 0 💬 1 📌 0
An open-source reactive Python notebook: reproducible, git-friendly, execute as scripts, share as apps!
GitHub: https://github.com/marimo-team/marimo
Discord: https://marimo.io/discord?ref=bsky
Building the @marimo.io notebook: https://github.com/marimo-team/marimo.
PyMDE, CVXPY, & ex TensorFlow developer. Minimum-Distortion Embedding book author. Stanford BS/MS/PhD.
Principal Architect @posit.co, GP Composed Ventures, Co-founder Voltron Data. Open source: Apache Arrow, pandas, Ibis. "Python for Data Analysis" book
🧑🏾💻OSS Contributor (dasBlog)
🏢PM @ Microsoft (Visual Studio, Core AI)
🏀📖🎸
✝️
poppastring.com/blog
Associate Prof. of Databases @ Carnegie Mellon.
Senior Software Engineer at Quansight Labs
Pretty focused on Narwhals and Polars these days, generally interested in dataframes and time series
Clinical director of intensive mental health services for children and youth in Canada (ret.). Believer in Truth and Reconciliation. Denier of Denialism. Student of semantics and statistics. "AI" too.
https://Answer.AI & https://fast.ai founding CEO; previous: hon professor @ UQ; leader of masks4all; founding CEO Enlitic; founding president Kaggle; various other stuff…
Dataframes powered by a multithreaded, vectorized query engine, written in Rust.
Author and Founder of Polars
Developing PyO3 to bring Rust 🦀 and Python 🐍 together.
Working with the team at Pydantic to build software that developers love.
Independent AI researcher, creator of datasette.io and llm.datasette.io, building open source tools for data journalism, writing about a lot of stuff at https://simonwillison.net/
evals evals evals. https://evals.info
Building Pydantic Logfire - uncomplicated observability for Python. Sequoia Scout.
Economics Research at OpenAI.
#MicrosofFabric Customer advocate, interests in Small Data & Self Service #Microsoftemployee since Dec 2023 , but my tweets are my own
I blog about making correct decisions. I used to be an equity research analyst and portfolio manager. I run on chaos energy, please be understanding
CEO @prefect.io. Building FastMCP. Mostly harmless.
 19.11.2025 07:47 — 👍 1 🔁 0 💬 0 📌 0
19.11.2025 07:47 — 👍 1 🔁 0 💬 0 📌 0