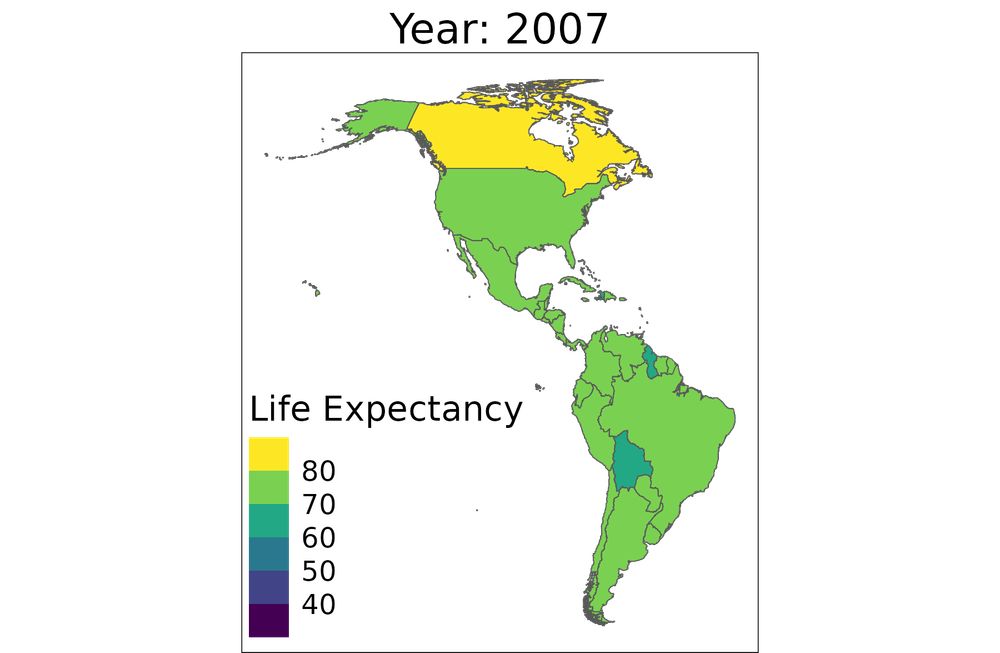
GitHub - ropensci/rnaturalearth: An R package to hold and facilitate interaction with natural earth map data :earth_africa:
An R package to hold and facilitate interaction with natural earth map data :earth_africa: - ropensci/rnaturalearth
I don't regularly do geospatial analysis, but when I do, #rstats' #ggplot2 and a few other packages help me get something together quickly.
Here's some packages and a chapter I've found helpful:
📦 {sf}: r-spatial.github.io/sf/
📦 {rnaturalearth}: ropensci.github.io/rnaturalearth/
1/2
05.08.2025 16:46 — 👍 8 🔁 3 💬 2 📌 0

Is Genocide Happening in Gaza?
[Melanie O’Brien is Associate Professor of International Law at the University of Western Australia, President of the International Association of Genocide Scholars, and Visiting Scholar with the H…
"Whatever the exact moment was of ‘crystallisation’ of these crimes as genocide, it is without a doubt that we are witnessing a genocide now in Gaza..."
Melanie O'Brien, President, International Association of Genocide Scholars
opiniojuris.org/2025/08/04/i...
04.08.2025 18:48 — 👍 0 🔁 3 💬 0 📌 0
"bullshit artisan"
04.08.2025 17:57 — 👍 26 🔁 2 💬 0 📌 0
I sore-heartedlly agree.
04.08.2025 17:46 — 👍 1 🔁 0 💬 0 📌 0
I think everyone interested in AI should read the model cards for the frontier models, especially the safety sections, which give you a sense of known risks:
Gemini Deep Think: storage.googleapis.com/deepmind-med...
Claude 4: www-cdn.anthropic.com/07b2a3f9902e...
o3: cdn.openai.com/pdf/2221c875...
04.08.2025 04:04 — 👍 98 🔁 15 💬 5 📌 1
When your grief is too great to bear, or your emotional detachment is too great to bare, our AI will compose a retro-scope (like a horoscope, but for the great beyond) that will feel crazy-right.
03.08.2025 15:17 — 👍 2 🔁 0 💬 0 📌 0
So, you're a testostymologist?
02.08.2025 23:29 — 👍 0 🔁 0 💬 0 📌 0

NP.
Check-out counters at my grocery store used to display not only the old-timey National Enquirer (BREAKING! News about someone who died when we were teens) but also glossy upstarts UNCOVERING! secret infidelities of fictitious soap-opera characters).
AIDoms are training us to lick up both.
02.08.2025 22:46 — 👍 1 🔁 0 💬 0 📌 0
Source?
02.08.2025 17:00 — 👍 0 🔁 0 💬 0 📌 0

Impromptu survey. Please complete:
" I ... " is not research.
E.g. "I asked GPT"
02.08.2025 16:59 — 👍 0 🔁 0 💬 0 📌 0

Kohut (1972) offers clarity on how policies are formulated by leaders of mafia states:
Harvesting narcissistic supply and soothing narcissistic rage.
mindsplain.com/wp-content/u...
02.08.2025 11:00 — 👍 18 🔁 13 💬 1 📌 1
I feel like I don’t post on here nearly enough about geography things.
I think I’m going to return to my weekly geography threads. This fall, I’ll do Indigenous geographies on Tuesdays and political & economic geography on Thursdays.
02.08.2025 02:22 — 👍 115 🔁 9 💬 4 📌 1

Screenshot of embedding atlas showing the embedding view on the left, a table at the bottom and charts on the right.
🚀 We've just open-sourced Embedding Atlas – a tool for exploring large embedding spaces through rich, interactive visualizations 📊.
01.08.2025 08:24 — 👍 120 🔁 34 💬 3 📌 3
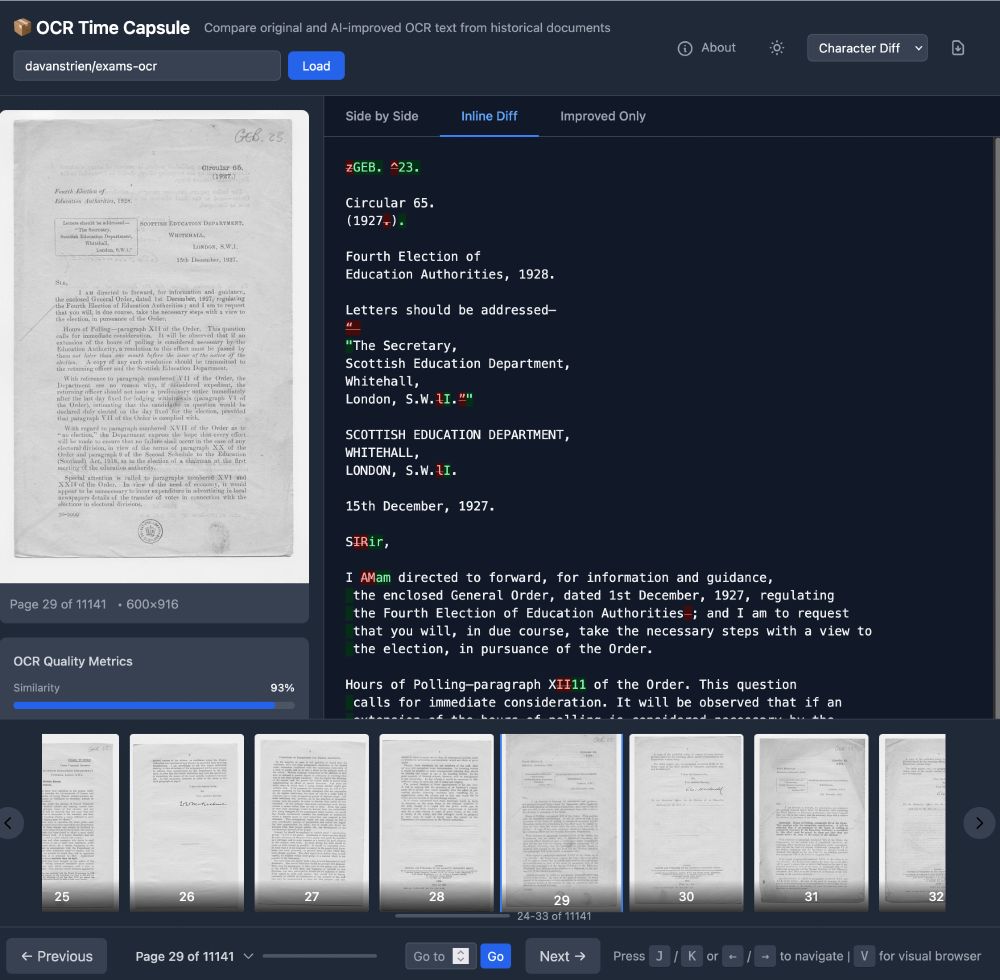
Screenshot of the app showing a page from a book + different views of existing and new ocr.
Many VLM-based OCR models have been released recently. Are they useful for libraries and archives?
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
01.08.2025 15:09 — 👍 47 🔁 15 💬 4 📌 1
This and I will die on this hill.
31.07.2025 19:10 — 👍 31 🔁 9 💬 0 📌 0

I keep seeing the Microsoft paper on AI use at work being used as a list of which jobs will be destroyed.
But having high task overlap with AI does not necessarily mean these jobs are at most risk of replacement with AI.
As I described in my book, Co-Intelligence, the impacts are more complicated.
31.07.2025 20:18 — 👍 79 🔁 7 💬 4 📌 1
Viz. Norm Macdonald and the Mangrate.
31.07.2025 20:59 — 👍 0 🔁 0 💬 0 📌 0
Horny is the new anxious?
31.07.2025 20:58 — 👍 4 🔁 0 💬 1 📌 0
@seancarleton.bsky.social
31.07.2025 14:21 — 👍 1 🔁 0 💬 0 📌 0
Read this: “There are really better ways to fight fascism than focusing on what magical ponies we’ll ride if we “win.”
31.07.2025 11:19 — 👍 64 🔁 21 💬 1 📌 0
A new report by Thomson Reuters highlights the intersection between missing Indigenous women and human trafficking in Canada.
The report says Winnipeg and Edmonton are among the most MMIWG cases, and that women swiftly go from missing to appearing on sex ads.
31.07.2025 00:04 — 👍 115 🔁 68 💬 7 📌 10
As a medical historian, the only thing I can think when seeing this caricature is that scene from Deadwood. You know which one. 😂👀
31.07.2025 00:12 — 👍 32 🔁 6 💬 1 📌 0

Multiple Fill and Colour Scales in ggplot2
Use multiple fill and colour scales in ggplot2.
Today I learned about the {ggnewscale} #rstats package. It's useful for when you need to define multiple scales for a #ggplot2 plot. I found it helpful for creating a gradient color scale based on both variables within a scatter plot .
Check it out: eliocamp.github.io/ggnewscale/
30.07.2025 06:26 — 👍 28 🔁 3 💬 2 📌 0
Internet ID verification is just a racket for private companies to turn the entire internet into one massive data harvesting operation
31.07.2025 00:06 — 👍 33 🔁 11 💬 0 📌 1
As a book history/digital humanities scholar, I immensely enjoyed this @rarebookschool.bsky.social talk on Warren's term, computational bibliography, as a set of tools to connect the study of artifact (microscopic/Hinman) to ideology (systemic/Darnton). (1/7)
30.07.2025 23:15 — 👍 25 🔁 9 💬 3 📌 0

At @thelancet.com today, entitled:
"A crisis of credibility: the global cost of US vaccine misinformation"
www.thelancet.com/journals/lan...
30.07.2025 22:48 — 👍 199 🔁 55 💬 5 📌 4

These jobs range from coding the ideology of manifestos to identifying types of protest events to detecting certain political valences in speeches. The idea is to precisely calibrate exactly
how replicable one can expect machines to be in practice, and where (what types of tasks) we can expect better (lower variance, more replication) or worse performance. The human
workers provide a baseline comparison in terms of replicability. At a high level, the news is bad: while it is true that LMs can be (very) accurate relative to a gold standard, they also show considerable variance over time. And this is to say nothing of cases where they simply will not run at all, and thus fail the most basic requirement (see, e.g., Benureau and Rougier, 2018) of computational replication. Contrary to popular belief, the problems do not go away even if one sets "temperatures" (or equivalent tunings) to zero; indeed, this induces new but unpredictable problems with replication. Unsurprisingly, this variance affects the substantive answers we get downstream-that is, in subsequent analysis in which the labels
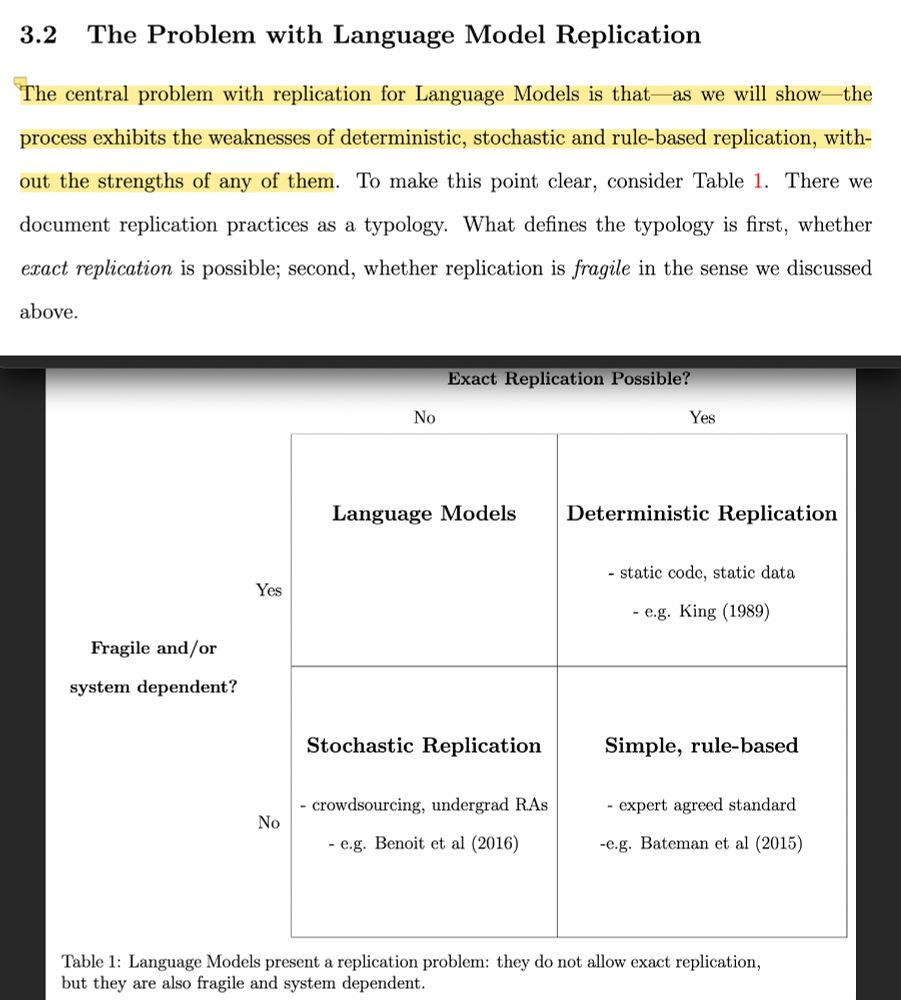
3.2 The Problem with Language Model Replication
The central problem with replication for Language Models is that as we will show-the process exhibits the weaknesses of deterministic, stochastic and rule-based replication, without the strengths of any of them. To make this point clear, consider Table 1. There we document replication practices as a typology. What defines the typology is first, whether exact replication is possible; second, whether replication is fragile in the sense we discussed above.
With a 2x2 table showing that LLms are not exactly replicable and are fragile

Full results for each outcome and run are displayed in Figures 8 to 10 in SI C. We also give descriptions of what we found. For now, we summarize our main observations:
1. For the manifestos, the crowdworkers perform very well (by LM standards) and their variance is generally lower than the LMs.
2. For the protests crowdworkers are less accurate than the LMs, but very consistent in their performance.
3. Crowdworkers struggle in predictable ways: for example, they are least accurate when manifestos should have 'extreme' codings (far left /far right).
4. LMs struggle in unpredictable ways: for example, GPT made errors on more moderate (liberal manifestos, but it is hard to know why.
5. Comparing across LMs, errors and performances appears to be idiosyncratic: for example, Llama has recall on some tasks on a par with GPT but generally much lower
variance.
6. Open LMs have the best replication performance, at least in terms of low variance.
For instance, on the static tasks, Llama has practically zero variance in its coding performance.

3. Consider open models that allow offline versioning. We found that, uniquely, our open-weights implementations were replicable to a high standard if that standard is low variance. That is, if the goal is something approaching the Deterministic 'code and data' replication vision above, then local, versioned models are the way to go. These may not deliver top of the line performance (e.g. accuracy) but should be checked as a first resort. We acknowledge that an open LM may not be "transparent" in the sense that it is "easy" to understand how it produces predictions even if one has the weights. But it is obviously a boon to replication insofar as being able to verify that
the original researcher did indeed see the results they reported. What is more, recent research into LM interpretability points the way toward more model understanding and control but only if weights are accessible (Cunningham et al., 2023).
Finally got to read this new paper by @cbarrie.bsky.social & @lexipalmer.bsky.social & Arthur Spirling on the lack of replicability in LLM-based research and polisci and it's so good and concise and well-reasoned! arthurspirling.org/documents/Ba...
31.07.2025 01:02 — 👍 37 🔁 10 💬 2 📌 2
Creating & writing about data vis for @datawrapper.de
Visualization, data, AI/ML. Professor at CMU (@dig.cmu.edu, @hcii.cmu.edu) and researcher at Apple. Also sailboats ⛵️ and chocolate 🍫.
www.domoritz.de
Caricaturist for Spitting Image & other TV. Co-author/illustrator of award-winning kids' non-fic. Open for fine-art caricature commissions. No AI or NFTs. www.etsy.com/uk/shop/TealCartoons
Work enquiries email: Teal.Cartoons@yahoo.com
www.adrianteal.com
Ex-Hasid now fighting for a true pluralistic democracy | Writer: democracy, peace, extremism, antisemitism, & marketing | MSNBC, DailyBeast, HuffPo, the Forward & more | Founder: justicemarketing.io | Newsletter: eladnehorai.substack.com
We’re a nonpartisan organization fighting for your rights to connect and communicate.
Learn more: FreePress.net
Cute drawings and bad thoughts, courtesy of your favorite trans dork (she/her) 🏳️⚧️
All the news, opinion and analysis from Israel, the Middle East and the Jewish World
Independent Senator-Alberta, Senate of Canada. 🇨🇦
Teacher. Former Canada Research Chair for the Public Understanding of Sexual and Gender Minority Youth. Co-founder, Pride Tape. 🏒🏳️🌈
Treaty Six. He/Him.
Correspondent on the Daily Show. Standup Comic & Emmy-nominated writer. Listen to the Josh Johnson Show podcast on Spotify + Apple
https://linktr.ee/joshjohnsoncomedy
Professor at the University of Virginia School of Law; Vice President of the Cyber Civil Rights Initiative; #MacFellow; Author of The Fight for Privacy: Protecting Dignity, Identity, and Love in the Digital Age (2022) and Hate Crimes in Cyberspace (2014) 🍋
Former organizer with the Ontario Coalition Against Poverty (OCAP).
"The way to right wrongs is to turn the light of truth upon them."
Ida B. Wells
Professor, Political Science, Brock University
Knowledge governance, IPE, Sydney Swans tragic
Co-author, with Natasha Tusikov, The New Knowledge: Information, Data and the Remaking of Global Power (Rowman & Littlefield, 2023).
fmr. publisher of jewish worker, jewschool, & orthodox anarchist. ex-tech lead at nylon mag, jta news, & repair the world. led kol nidre at occupy wall street. aft & iww. never again to anyone. syracuse, ny.
🔗 https://self.agency
Information Visualization 📊📉✍🏼 at University of Twente
Core project: The Languages of Visualization, with Clive Richards
Also at UT Climate Centre @utclimate.bsky.social
LinkedIn: https://linkedin.com/in/yuriengelhardt
Mastodon: https://vis.social/@yuri
Professor of Cancer Virology, University of Leeds.
Co-Chair, Independent SAGE
Nonviolence3.com focuses on innovative strategies and tactics that enable activists to more effectively resist corporate and government power through social justice campaigns.
Based in Raleigh, NC.
Videos, graphics, stories & essays at fragmentsweb.org
Things are terrible
(we follow our contributors)