Thanks!
03.03.2025 18:11 — 👍 0 🔁 0 💬 0 📌 0
The Influence of AI on Content Moderation and Communication | Tom Cunningham
Tom Cunningham blog
I think the effects of AI on the offense-defense balance across many domains is really important topic & I'm surprised there aren't more people working on it, it seems a perfect fit for econ theorists.
03.03.2025 16:42 — 👍 1 🔁 0 💬 0 📌 0
The Influence of AI on Content Moderation and Communication | Tom Cunningham
Tom Cunningham blog
How does AI change the balance of power in content moderation & communication?
I wrote something on this (pre-OpenAI) with a simple prediction:
1. Where the ground truth is human judgment, AI favors defense.
2. Where the ground truth is facts in the world, AI favors offense.
03.03.2025 16:42 — 👍 1 🔁 0 💬 2 📌 0
Thank you!
31.01.2025 20:51 — 👍 0 🔁 0 💬 0 📌 0

A new post: On Deriving Things
(about the time spent back and forth between clipboard whiteboard blackboard & keyboard)
tecunningham.github.io/posts/2020-1...
31.01.2025 19:14 — 👍 6 🔁 0 💬 1 📌 1
I also talk about the related point that outliers typically have one big cause rather than many small causes.
28.12.2024 00:31 — 👍 1 🔁 0 💬 0 📌 0
2. If a drug is associated with a 5% higher rate of birth defects it’s probably a selection effect, if it’s associated with a 500% higher rate of birth defects it’s probably causal.
28.12.2024 00:31 — 👍 0 🔁 0 💬 1 📌 0
When too much good news is bad news:
1. If an AB test shows an effect of +2% (±1%) it’s very persuasive, but if it shows a an effect of +50% (±1%) then the experiment was probably misconfigured, and it’s not at all persuasive.
28.12.2024 00:31 — 👍 2 🔁 0 💬 1 📌 0
Full post here:
tecunningham.github.io/posts/2023-1...
25.10.2023 15:49 — 👍 0 🔁 0 💬 0 📌 0

Choosing headcount? Increasing headcount on a team will shift out the Pareto frontier of a team, and so you can then sketch out the *combined* Pareto frontier across metrics as you reallocate headcount.
25.10.2023 15:48 — 👍 0 🔁 0 💬 1 📌 0
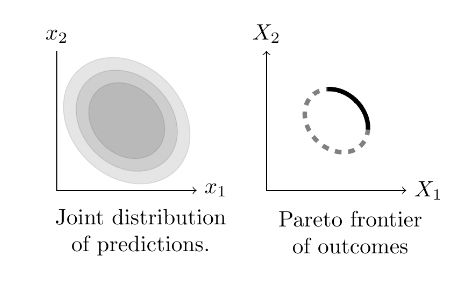
Choosing ranking weights? You can think of the set of classifier scores (pClick,pReport) as drawn from a distribution, and if additive it's easy to calculate the Pareto frontier, and if Gaussian then the Pareto frontier is an ellipse.
25.10.2023 15:48 — 👍 0 🔁 0 💬 1 📌 0

Choosing launch criteria? You can think of the set of experiments as pairs (ΔX,ΔY) from some joint distribution, and if additive it's easy to calculate the Pareto frontier, and if (ΔX,ΔY) are Gaussian then the Pareto frontier is an ellipse.
25.10.2023 15:47 — 👍 0 🔁 0 💬 1 📌 0


New post: Thinking about tradeoffs? Draw an ellipse.
With applications to (1) experiment launch rules; (2) ranking weights in a recommender; and (3) allocating headcount in a company.
25.10.2023 15:47 — 👍 1 🔁 0 💬 1 📌 0
My daughter and I have an arrangement: She does whatever I ask her to do. In return I only ask her to do things that I know she's going to do anyway.
23.10.2023 14:16 — 👍 0 🔁 0 💬 0 📌 0
6. To extrapolate the effect of metric B from metric A, it's best to do a cross-experiment regression, but be careful about bias.
17.10.2023 19:09 — 👍 1 🔁 0 💬 0 📌 0
4. Empirical Bayes estimates are useful but only incorporate some information, so shouldn't be treated as best-guess of true causal effects.
5. Launch criteria should identify "final" metrics with conversion factors from "proximal" metrics. Don't make decisions on stat-significance.
17.10.2023 19:09 — 👍 1 🔁 0 💬 1 📌 0
Claims:
1. Experiments are not the primary way we learn causal relationships.
2. A simple Gaussian model gives you a robust way of thinking about challenging cases.
3. The Bayesian approach makes it easy to think about things that are confusing (multiple testing, peeking, selective reporting).
17.10.2023 19:08 — 👍 1 🔁 0 💬 1 📌 0
Experimentation Interpretation and Extrapolation | Tom Cunningham
A long and partisan note about experiment interpretation based on experience at Meta and Twitter.
The common thread is that people are pretty good intuitive Bayesian reasoners, so just summarize the relevant evidence and let a human be the judge:
tecunningham.github.io/posts/2023-0...
17.10.2023 19:07 — 👍 1 🔁 0 💬 1 📌 0

The most interesting mechanisms: (1) AI can find patterns which humans didn't know about; (2) AI can use human tacit knowledge, not available to our conscious brain.
06.10.2023 20:07 — 👍 0 🔁 0 💬 0 📌 0

It requires formalizing the relationship between the AI, the human, and the world. Interestingly there are a number of reasons why the AI, who only encounters the real world via mimicking human responses, can have a superior understanding of the world. Can describe this visually:
06.10.2023 20:06 — 👍 1 🔁 0 💬 1 📌 0
An AI Which Imitates Humans Can Beat Humans | Tom Cunningham
I wrote a long blog post working through the different ways in which an AI trained to *imitate* humans could *outperform* humans: tecunningham.github.io/posts/2023-0...
06.10.2023 20:04 — 👍 4 🔁 0 💬 1 📌 0
Statistician, Data Scientist.
Digital data/machine learning/economics, focused on developing economies. Faculty at Columbia. dan.bjorkegren.com
Mostly on LinkedIn:
https://www.linkedin.com/in/misha-teplitskiy
Economics in Oslo/Scandinavia
karlharmenberg.com
computer security person. former helpdesk
I’m a bot real-time posting/skeeting M 1.0+ earthquakes in the San Francisco Bay Area.
Built by @djcentos7.bsky.social
Fully automated luxury queer space georgist into effective altruism, liberalism, and feminism. More of a nyan-binary than a catgirl. I accept every pronoun (not "it") but mostly use "they" for myself. I try to post good news and actionable information
I am an Economist leveraging the assignment mechanism in the field to test theory and help non-profits, govts, and anyone who will listen! My goal is to (hopefully!) change the world for the better. My picture is with my oldest son!
Research Professor of Philosophy at Harvard University.
Minnesota guy.
"This particular activist will not stop." Sen. Chris Murphy
associate editor at liberal currents. neonliberal. she/her.
Economics Professor at Brown, studying discrimination, education, healthcare, and applied econometrics. I like IV
https://sites.google.com/site/aboutpeterhull/home