it's never been more fun to code, because it's never been more valuable to care about your code, to optimize the details and to write beautiful and compact code. this is the valuable type of code now. it's not just the age of research, it's the age of computer science.
30.12.2025 11:29 — 👍 1 🔁 0 💬 0 📌 0
I can only imagine how crazy it must be to be a PhD student submitting to ML conferences now. The process has always been noisy, but at this point it's selecting for either obfuscation or shallow ideas. You either intimidate the reviewer, or you write a blog post in latex.
16.11.2025 19:34 — 👍 2 🔁 0 💬 0 📌 0

We're excited to present our latest article in Nature Machine Intelligence - Boosting the predictive power of protein representations with a corpus of text annotations.
Link: www.nature.com/articles/s42...
[1/4]
21.08.2025 19:34 — 👍 12 🔁 5 💬 1 📌 0
I’d add data/task understanding as a separate mid layer. Most papers I know break in the transition of high to mid.
12.08.2025 19:36 — 👍 1 🔁 0 💬 1 📌 0
YouTube video by NPR Music
Milton Nascimento & esperanza spalding: Tiny Desk (Home) Concert
the goat of brazilian music w/ the best of (current) american music
www.youtube.com/watch?v=jFUh...
09.08.2025 15:06 — 👍 2 🔁 0 💬 0 📌 0
This is why I personally love TMLR. If it's correct and well-written let's publish. The interesting papers are the ones the community actively recognizes in their work, e.g. citing, extending, turning into products, etc. (independent process of publication).
30.07.2025 23:43 — 👍 1 🔁 0 💬 0 📌 0
I agree with most of your thread, but classifying "uninteresting work" is quite hard nowadays. Papers became this "hype-seeking" game, where out of the 10 hyped papers of the month, at most 1 survives further investigation of the results. And even if we think we're immune to this, what is interest?
30.07.2025 23:43 — 👍 2 🔁 0 💬 1 📌 0

Scaling Laws Are Unreliable for Downstream Tasks: A Reality Check
Downstream scaling laws aim to predict task performance at larger scales from pretraining losses at smaller scales. Whether this prediction should be possible is unclear: some works demonstrate that t...
I loved this new preprint by Lourie/Hu/ @kyunghyuncho.bsky.social . If you really wanna convince someone youre training a foundation model, or proposing better methodology, loss scaling laws aren't enough. It has to be tied w/ downstream performance. it shouldn't be vibes
arxiv.org/abs/2507.00885
26.07.2025 22:43 — 👍 5 🔁 1 💬 0 📌 0
We're at ICML, drop us a line if you're excited about this direction.
📄 Paper: arxiv.org/abs/2507.02083
💻 Code: github.com/h4duan/SciGym
🌍 Website: h4duan.github.io/scigym-bench...
🗂️ Dataset: huggingface.co/datasets/h4d...
16.07.2025 20:16 — 👍 1 🔁 0 💬 0 📌 0

I'm very excited about our new work: SciGym. How can we scale scientific agents' evaluation?
TLDR; Systems biologists have spent decades encoding biochemical networks (metabolic pathways, gene regulation, etc.) into machine-runnable systems. We can use these as "dry labs" to test AI agents!
16.07.2025 20:16 — 👍 2 🔁 0 💬 1 📌 0
Also, I see ITCS more like a “out of the box”, “bold” idea or even new area, I don’t see the papers having simplicity as a goal, but just my experience.
30.06.2025 00:48 — 👍 0 🔁 0 💬 1 📌 0
Mhm, I agree with the idealistic part, I certainly have seen the same. But I know quite a few papers that are aligned w the call, tbh this happens in any venue. I think the message and the openness to this kind of paper is important though
30.06.2025 00:46 — 👍 0 🔁 0 💬 2 📌 0
I wish we had an ML equivalent of SOSA (Symposium On Simplicity in Algorithms). "simpler algorithms manifest a better understanding of the problem at hand; they are more likely to be implemented and trusted by practitioners; they are more easily taught" www.siam.org/conferences-....
29.06.2025 17:04 — 👍 3 🔁 0 💬 1 📌 0
this is not my area, but if you think of it in terms of a randomized algorithm (BPP,PP), the hard part is usually the generation, at least for the algorithms we tend to design. e.g. Schwartz-Zippel Lemma. (Although in theory you can have the "hard part" in verification for any problem)
14.06.2025 16:17 — 👍 2 🔁 0 💬 1 📌 0
It takes 1 terrible paper for knowledgeable people to stop reading all your papers, this risk is often not accounted for
09.06.2025 20:01 — 👍 1 🔁 0 💬 1 📌 0
Maybe check Cat s22, it gives you the basics, eg whatsapp+gps and nothing else
08.06.2025 19:40 — 👍 2 🔁 0 💬 0 📌 0
it just sounds like "see you three times" ;) it's like some people named "Sinho" that is often confused with portuguese/brazilians; but from what I heard it's a variation of Singh (not sure though)
30.05.2025 23:02 — 👍 1 🔁 0 💬 1 📌 0
One simple way to reason about this: treatment assignment guarantees you have the right P(T|X). Self-selection changes P(X), a different quantity. Looking at your IPW estimator you can see that changing P(X) will bias regardless of P(T|X).
18.04.2025 15:08 — 👍 3 🔁 2 💬 0 📌 0
I haven't been up to date with the model collapse literature, but it's crazy the amount of papers that consider the case where people only reuse data from the model distribution. This never happens, there's always some human curation or conditioning that yields some type of "real-world, new, data".
13.04.2025 18:26 — 👍 2 🔁 0 💬 0 📌 0
this general idea of using an external world/causal model given by a human and using the LM only for inference is really cool ---it's also the insight behind our work in NATURAL. Do you guys think it's possible to write a more general software for the interface DAG->LLM_inference->estimate?
12.04.2025 18:27 — 👍 2 🔁 0 💬 1 📌 0
Position: Graph Learning Will Lose Relevance Due To Poor Benchmarks
While machine learning on graphs has demonstrated promise in drug design and molecular property prediction, significant benchmarking challenges hinder its further progress and relevance. Current bench...
This is my favourite "graph paper" of the last 1 or 2 years. We also need to start including non-NN baselines, e.g. fingerprints+catboost ---if the goal is real-world impact and not getting it published asap. I also recommend following @wpwalters.bsky.social's blog.
arxiv.org/abs/2502.14546
24.03.2025 17:21 — 👍 7 🔁 1 💬 1 📌 0
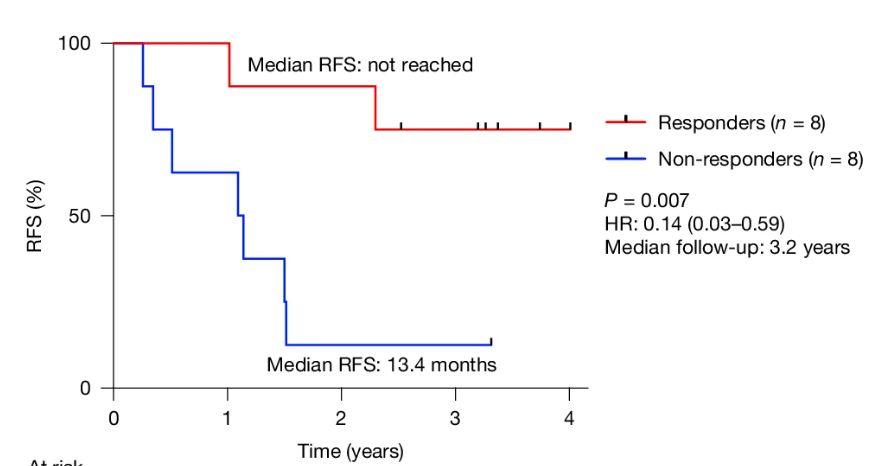
Unbelievable news.
Pancreatic is one of the deadliest cancers.
New paper shows personalized mRNA vaccines can induce durable T cells that attack pancreatic cancer, with 75% of patients cancer free at three years—far, far better than standard of care.
www.nature.com/articles/s41...
27.02.2025 17:03 — 👍 7267 🔁 1925 💬 140 📌 315
Oh gotcha. I think it’s just super cheesy to quote feynman at this point haha but it’s a good philosophy to embrace
20.02.2025 01:14 — 👍 0 🔁 0 💬 0 📌 0
In what contexts do you think it’s misused? Just curious, I’m a big fan and might be overusing it 😅
20.02.2025 01:11 — 👍 0 🔁 0 💬 1 📌 0

The Ultra-Scale Playbook - a Hugging Face Space by nanotron
The ultimate guide to training LLM on large GPU Clusters
After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
19.02.2025 18:10 — 👍 180 🔁 52 💬 2 📌 5
if you're feeling uninspired and getting nan's everywhere, you can give your codebase, describe the problem and ask for suggestions to try or debug. I think of it more as a debugger assistant than a code generator.
19.02.2025 15:02 — 👍 2 🔁 0 💬 0 📌 0
I've always hated the "reasoning models" for code assistance since I think the most useful application of LLMs is really writing the boring helper functions and letting us focus on the hard work. However, I found o3 to be particularly useful when debugging ML code, e.g., 1/2
19.02.2025 15:02 — 👍 1 🔁 0 💬 1 📌 0
Reconstruction for Powerful Graph Representations
if you remove one at a time you get reconstruction gnns 🙃 proceedings.neurips.cc/paper/2021/h...
14.02.2025 23:00 — 👍 1 🔁 0 💬 0 📌 0
100%. Also, sometimes the use/task might be the same, but the user's notion of bias can vary. Eg people might expect group or individual notions of fairness.
14.02.2025 12:03 — 👍 0 🔁 0 💬 0 📌 0
it's a website (and a podcast, and a newsletter) about humans and technology, made by four journalists you might already know. like and subscribe: 404media.co
Creator of Flask • earendil.com ♥︎ writing and giving talks • Excited about AI • Husband and father of three • Inhabits Vienna; Liberal Spirit • “more nuanced in person” • More AI content on https://x.com/mitsuhiko
More stuff: https://ronacher.eu/
Cofounded and lead PyTorch at Meta. Also dabble in robotics at NYU.
AI is delicious when it is accessible and open-source.
http://soumith.ch
Computational Chemist @ Francis Crick Institute. #WomenInSTEM
📍 London, UK.
AI Scientist @PMCC @UHN @Vector Institute, Previously PhD @SickKids @UofT
ML for Healthcare | Computational Biology | Precision Medicine | Responsible AI
Senior Lecturer #USydCompSci at the University of Sydney. Postdocs IBM Research and Stanford; PhD at Columbia. Converts ☕ into puns: sometimes theorems. He/him.
Assistant Professor of Technology, Operations, and Statistics @ NYU Stern
Interested in Computational Social Science, Digital Persuasion, and Wisdom of Crowds
Genomics, Machine Learning, Statistics, Big Data and Football (Soccer, GGMU)
Foundations of AI. I like simple and minimal examples and creative ideas. I also like thinking about the next token 🧮🧸
Google | PhD, CMU |
https://arxiv.org/abs/2504.15266 | https://arxiv.org/abs/2403.06963
vaishnavh.github.io
personalized cancer immunotherapy = genomics + immunology + machine learning + oncology
(pirl.unc.edu)
Statistician and computational biologist; uw alum; jhu student. He/him. http://ekernf01.github.io
DC. political philosopher at Georgetown, editor at @hammerandhope.bsky.social, rhythm guitarist + vox for @femiandfoundation.bsky.social. #COYS
IBM research, DREAM challenges director, rabdomante, Sys Bio,👃🏽alma-mater UNAM
Avid rower who sometimes thinks about biomolecular dynamics. Asst Prof @uwbiochem.bsky.social
https://waymentsteelelab.org/
Assistant Professor at Imperial College London | EEE Department and I-X.
Neuro-symbolic AI, Safe AI, Generative Models
Previously: Post-doc at TU Wien, DPhil at the University of Oxford.
PhD Student @ Cambridge & Vector Institute | Prev: AWS AI Lab | Do not go gentle into that good night 🧗 | ryan0v0.github.io
Assistant Professor @ École Polytechnique, IP Paris |
Interested in GNNs and Graph Representation Learning |
Website: johanneslutzeyer.com
Public policy professor, Price School USC @priceschool.usc.edu, father, poverty/social policy/racial inequality/immigration/policymakers, posts do not speak for employer, https://bradydave.wordpress.com






















