We are looking for someone to join the group as a postdoc to help us with scaling implicit transfer operators. If you are interested in this, please reach out to me through email. Include CV, with publications and brief motivational statement. RTs appreciated!
27.05.2025 13:23 — 👍 14 🔁 8 💬 1 📌 2
what is so misunderstood about (3)?
26.05.2025 17:28 — 👍 0 🔁 0 💬 2 📌 0

2025 CHAIR Structured Learning Workshop -- Apply to attend: ui.ungpd.com/Events/60bfc...
06.05.2025 10:02 — 👍 9 🔁 3 💬 0 📌 0
cool work
25.04.2025 14:15 — 👍 0 🔁 0 💬 0 📌 0
best of luck marvin :)
19.03.2025 14:35 — 👍 2 🔁 0 💬 1 📌 0
ist auch logisch, dass greenpeace/foodwatch bspw den grünen näherstehen, da die ja die themen bespielen. neutralität wäre da ja eher lächerlich
27.02.2025 13:51 — 👍 0 🔁 0 💬 0 📌 0
was ist an der studie falsch
18.02.2025 23:23 — 👍 0 🔁 0 💬 0 📌 0
Score-Based Generative Models Detect Manifolds
interesting point, but i would say (true) memorization is mathematically impossible. the underlying question is what generalization means when we are given finite training samples. it depends on the model and how long you train, see proceedings.neurips.cc/paper_files/... and arxiv.org/abs/2412.20292
18.02.2025 10:56 — 👍 0 🔁 0 💬 0 📌 0
yes i agree, but for diffusion such a constant velocity/score field does not even exist
07.02.2025 13:04 — 👍 1 🔁 0 💬 1 📌 0
so in diffusion models the time schedule is so that we cannot have straight paths velocity fields (i.e., v_t(x_t) is constant in time), as opposed to flow matching/rectified flows where it is possible to obtain such paths (although it requires either OT/rectifying...)
06.02.2025 20:11 — 👍 0 🔁 0 💬 1 📌 0
yes lol thank you!
23.01.2025 12:08 — 👍 0 🔁 0 💬 0 📌 0
Check out our github and give it a try yourself! Lots of potential in exploring stuff like this also to other domains (medical imaging, protein/bio stuff)!
github.com/annegnx/PnP-...
Also credit goes to my awesome collaborators Anne Gagneux, Sego Martin and Gabriele Steidl!
23.01.2025 11:05 — 👍 0 🔁 0 💬 1 📌 0

Compared to diffusion methods, we can handle arbitrary latent distributions and also get (theoretically) straighter paths! We evaluate on multiple image datasets against flow matching+diffusion+standard PnP based restoration methods!
23.01.2025 11:00 — 👍 0 🔁 0 💬 1 📌 0
Our algorithm proceeds as follows: we do a gradient step on the data fidelity, reproject onto the flow matching path and then denoise using our flow matching model. This is super cheap to do!
23.01.2025 10:58 — 👍 0 🔁 0 💬 1 📌 0
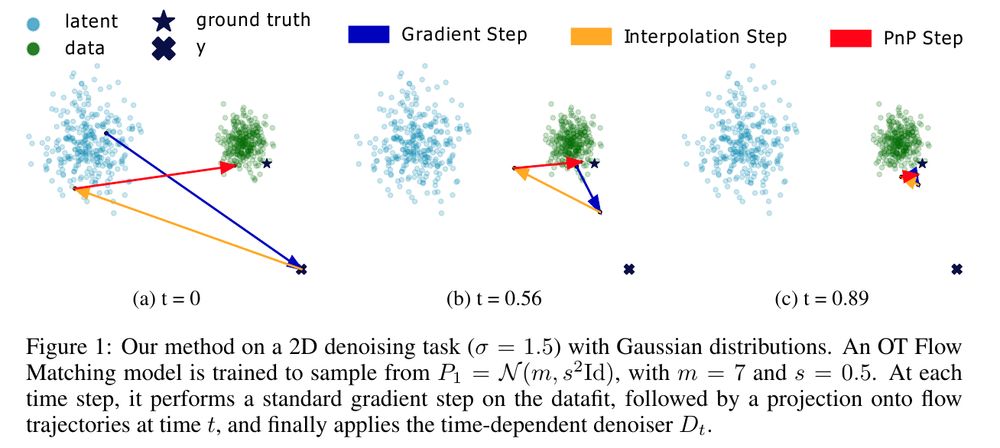
Therefore, we use the plug and play framework and rewrite our velocity field (which predicts a direction) to instead denoise the image x_t (i.e., predict the MMSE image x_1). Then we obtain a "time" conditional PnP version, where we solve do the forward backward PnP at the current time and reproject
23.01.2025 10:57 — 👍 0 🔁 0 💬 1 📌 0
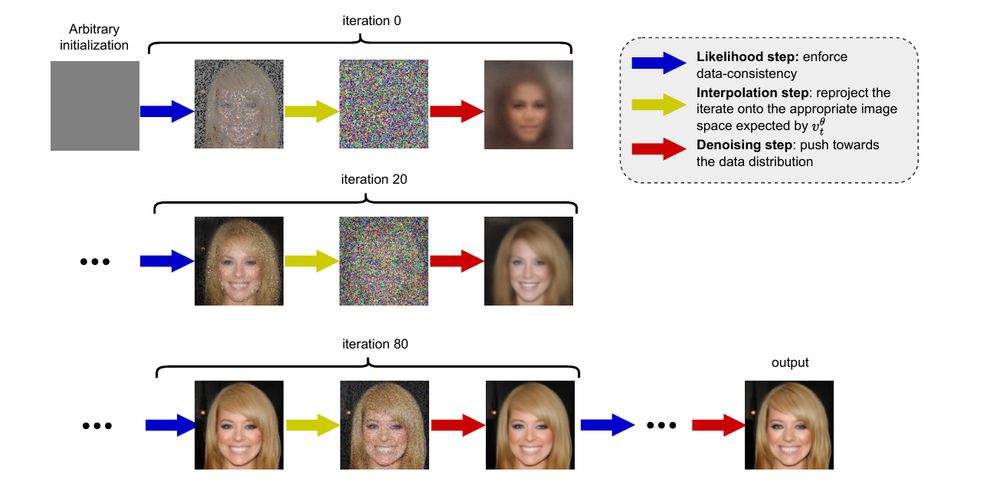
Our paper "PnP-Flow: Plug-and-Play Image Restoration with Flow Matching" has been accepted to ICLR 2025. Here a short explainer: We want to restore images (i.e., solve inverse problems) using pretrained velocity fields from flow matching. However, using change of variables is super costly.
23.01.2025 10:53 — 👍 15 🔁 5 💬 1 📌 2
very nice paper, only had a quick glimpse, but another aspect is that the optimal score estimator explodes if we approach t -> 0, which NNs ofc cannot replicate. how does this influence the results?
01.01.2025 15:51 — 👍 1 🔁 0 💬 1 📌 0
you might be onto sth haha
28.11.2024 10:26 — 👍 1 🔁 0 💬 0 📌 0
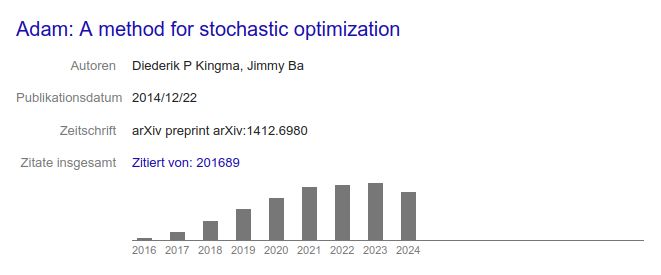
i guess the adam paper is a pretty good indicator how much ml papers are being published. looks like we are saturating since 2021
28.11.2024 10:16 — 👍 2 🔁 0 💬 1 📌 0
same experience here. i am not sure we need actual conference reviewing at all. why do we not all publish on openreview and if i use your paper/build upon/read it, i can write my opinion on it? without the accept reject stamp.
24.11.2024 13:14 — 👍 0 🔁 0 💬 0 📌 0
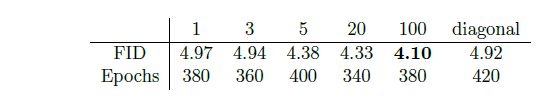
Here, one can see FID results for different beta! Indeed it seems to be fruitful to restrict mass movement in Y for class conditional cifar! We apply this also to other interesting inverse problems, the article can be found at arxiv.org/abs/2403.18705
20.11.2024 09:14 — 👍 1 🔁 0 💬 0 📌 0
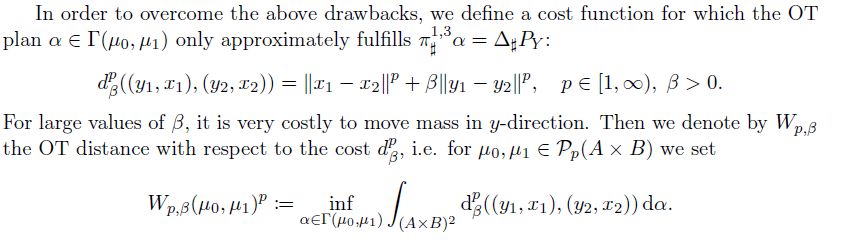
We want to approximate this distance with standard OT solvers, and therefore introduce a twisted cost function. With this at hand, we can now do OT flow matching for inverse problems! The factor beta controls how much mass leakage we allow in Y.
20.11.2024 09:12 — 👍 2 🔁 0 💬 1 📌 0
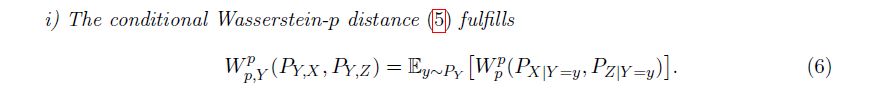
This object has already been of some interest, i.e., it pops up in the theory of gradient flows. It generalizes the KL property quite nicely, and unifies some ideas present in conditional generative modelling. For instance, its dual is the loss usually used in conditional wasserstein gans.
20.11.2024 09:10 — 👍 0 🔁 0 💬 1 📌 0

Now does the same hold for the Wasserstein distance? Unfortunately not, since moving mass in Y-direction can be more efficient for some measures. However, we can fix that if we restrict the suitable couplings to ones, that only move mass in Y-direction.
20.11.2024 09:08 — 👍 0 🔁 0 💬 1 📌 0
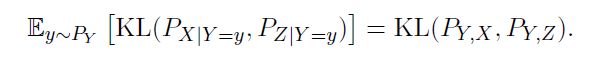
In a somewhat recent paper we introduced conditional Wasserstein Distances. They generalize a property that basically explains why KL works well for generative modelling, the chain rule of KL!
It says that if one wants to approximate the posterior, one can also minimize the KL between joints.
20.11.2024 09:07 — 👍 15 🔁 0 💬 1 📌 0
I created a starter pack for simulation-based inference (aka. likelihood-free inference).
Let me know if you’d like me to add you.
go.bsky.app/GVnJRoK
17.11.2024 15:14 — 👍 42 🔁 18 💬 16 📌 2
would love to be added :)
19.11.2024 00:44 — 👍 0 🔁 0 💬 1 📌 0
look at my handle haha
19.11.2024 00:43 — 👍 1 🔁 0 💬 0 📌 0
feel the ai
17.11.2024 19:05 — 👍 2 🔁 0 💬 0 📌 0
Computational physical chemist. Currently Postdoc@BAM (Bundesanstalt für Materialforschung-und prüfung). Real Football and American Football Enthusiast
ML Research scientist. Interested in geometry, information theory and statistics 🧬🎗️
Opinions are my own. :)
AI4science research, density functional theory @ Microsoft Research Amsterdam. PhD on generative modeling, flows, diffusion @ Mila Montreal
Bundesanstalt für Materialforschung und -prüfung (BAM) | federal research institution | safety in technology & chemistry | imprint / data protection: http://bam.de/imprint
IOP Publishing is a society-owned scientific publisher, providing impact, recognition and value for the scientific community. IOP Publishing’s portfolio includes more than 90 journals.
Politikwissenschaftlerin usw
Assistant Professor at Mila and UdeM
https://necludov.github.io/
Incoming postdoc @univie.ac.at (from September)
Researches the Milky Way & star clusters with machine learning
Founded the Astronomy feeds (@astronomy.blue)
🏳️🌈 🏳️⚧️ (she/her), Ⓥ
Website: https://emily.space
GitHub: https://github.com/emilyhunt
Postdoctoral researcher at ENSAE interested in Optimal Transport.
More information at: https://clbonet.github.io/
Hier skeetet die Gruppe Kommunikation und Medien des GFZ in Deutsch und auf Englisch | Skeets by Communications and Media of GFZ Helmholtz Centre for Geosciences
Das Deutsche Krebsforschungszentrum (DKFZ) ist die größte biomedizinische Forschungseinrichtung in Deutschland. Wir forschen für ein Leben ohne Krebs.
Webseite: www.dkfz.de
https://wonderl.ink/@dkfz
Impressum: www.dkfz.de/impressum
{ML,Statistics}@{Materials,Bioinformatics}
https://bamescience.github.io
NEW to Bluesky | Director @ Deloitte | Voice of Cloud, Data & AI | Writer, Speaker, and Performer | Visit my blog
MdB und Fraktionsvorsitzende von Bündnis 90/Die Grünen im Bundestag. Kölnerin. Direkt gewählte Abgeordnete für Ehrenfeld, Nippes und Chorweiler. 💚
Bildung, Beteiligung, Demokratie.




















