


𝗛𝗔𝗠𝗦𝘁𝟯𝗥: 𝗛𝘂𝗺𝗮𝗻-𝗔𝘄𝗮𝗿𝗲 𝗠𝘂𝗹𝘁𝗶-𝘃𝗶𝗲𝘄 𝗦𝘁𝗲𝗿𝗲𝗼 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻
Sara Rojas, Matthieu Armando, Bernard Ghamen ... Gregory Rogez
arxiv.org/abs/2508.16433
Trending on www.scholar-inbox.com

@weinzaepfelp.bsky.social
Principal Research Scientist in Computer Vision at Naver Labs Europe https://philippeweinzaepfel.github.io/
𝗛𝗔𝗠𝗦𝘁𝟯𝗥: 𝗛𝘂𝗺𝗮𝗻-𝗔𝘄𝗮𝗿𝗲 𝗠𝘂𝗹𝘁𝗶-𝘃𝗶𝗲𝘄 𝗦𝘁𝗲𝗿𝗲𝗼 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻
Sara Rojas, Matthieu Armando, Bernard Ghamen ... Gregory Rogez
arxiv.org/abs/2508.16433
Trending on www.scholar-inbox.com




𝗛𝗢𝗦𝘁𝟯𝗥: 𝗞𝗲𝘆𝗽𝗼𝗶𝗻𝘁-𝗳𝗿𝗲𝗲 𝗛𝗮𝗻𝗱-𝗢𝗯𝗷𝗲𝗰𝘁 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝗳𝗿𝗼𝗺 𝗥𝗚𝗕 𝗶𝗺𝗮𝗴𝗲𝘀
Anilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel ... Grégory Rogez
arxiv.org/abs/2508.16465
Trending on www.scholar-inbox.com
HOSt3R (Keypoint-free Hand-Object 3D Reconstruction from RGB images) builds upon DUSt3R for unconstrained hand-object 3D reconstruction - example 3D shape output below.
Paper: arxiv.org/abs/2508.16465
More info on @naverlabseurope.bsky.social
@iccv.bsky.social ➡️ tinyurl.com/2p9kcb86
2/2🧵
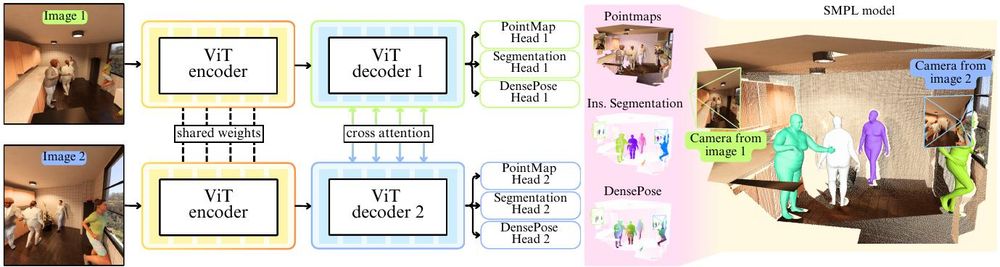
Announcing 2 new members of the *St3R family for human-centric 3D vision tasks!
Meet HAMst3R & HOSt3R
@iccv.bsky.social
- HAMSt3R (Human-Aware Multi-view Stereo 3D Reconstruction) extends MASt3R to handle scenes involving people.
Paper: arxiv.org/abs/2508.16433
1/2 🧵
🤩wooo I was always lost with the default setting, thanks for the tip!
12.08.2025 10:59 — 👍 2 🔁 0 💬 1 📌 0
Major announcement ✨registration is OPEN✨
AI for Robotics workshop (4th edition): Spatial AI
🗓️Nov 21-22 Grenoble, France!
Details: tinyurl.com/bdtk2nzs
⭐⭐ 14 confirmed speakers ⭐⭐: 🧵2/3
Poster submissions (travel grant possible): 🧵 3/3
Spread the word!
Oo, I would have loved to be there for the bicycle trip in addition to the meeting 😀
23.07.2025 06:57 — 👍 1 🔁 0 💬 1 📌 0This is what you do when you set allow_sliding=true in your Habitat simulator. If you want to run test with sim2real transfer, you might want to consider wearing a helmet !
04.07.2025 17:20 — 👍 5 🔁 1 💬 0 📌 0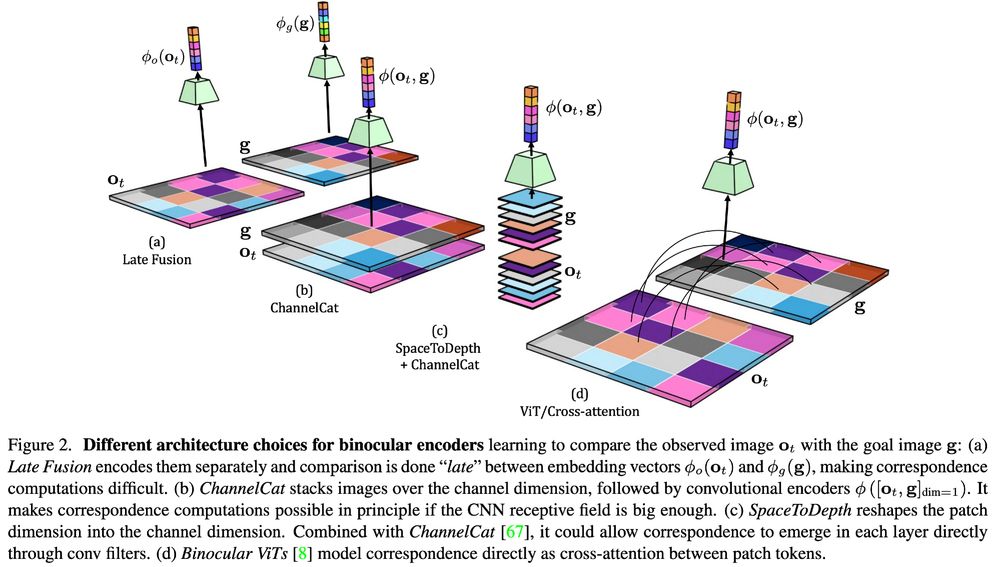
In a new paper led by Gianluca Monaci, with @weinzaepfelp.bsky.social and myself, we explore the relationship between rel pose estimation and image goal navigation and study different architectures: late fusion, channel cat (w/ or w/o space2depth) and cross-attention.
arxiv.org/abs/2507.01667
🧵1/5

Excited to share our latest work in the *St3R family. PanSt3R, accepted at #ICCV25 proposes a unified and integrated approach for panoptic 3D scene reconstruction and panoptic segmentation in a single forward pass.
www.arxiv.org/abs/2506.21348
We extended MUSt3R with semantic awareness and multi-view panoptic segmentation capabilities in PanSt3R, accepted at #ICCV2025
www.arxiv.org/abs/2506.21348
Also valid for overleaf 😀
27.06.2025 16:40 — 👍 1 🔁 0 💬 1 📌 0Yeah, I am making the stats for ~2 years and it seems pretty similar with about 35-40% before final decision and 75-80% at the start of the conference.
19.06.2025 12:02 — 👍 2 🔁 0 💬 0 📌 0Yeah I was expecting also lower. But scholar-inbox indeed finds quite a lot of relevant papers that I was not aware of.
[Note: the stat is done by searching titles on arXiv (with some manual matching for small differences), but this might not be perfect when titles has changed too much.]
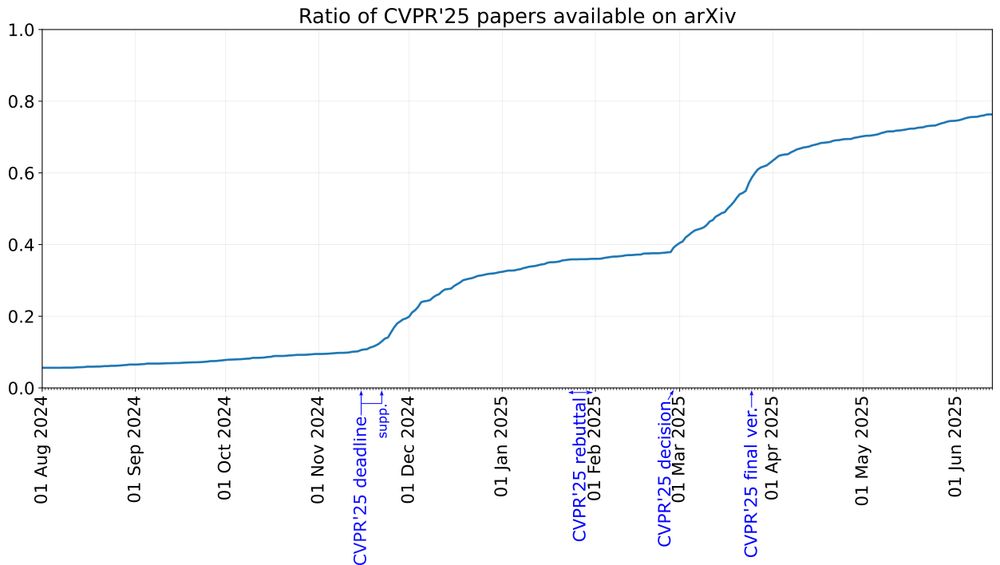
When were #CVPR2025 papers available on arXiv? 👇
17.06.2025 11:52 — 👍 39 🔁 9 💬 2 📌 0Wanna the outstanding performance of MASt3R while using a ViT-B or ViT-S encoder instead of its ViT-L one? Don't miss how we build DUNE, a single encoder for diverse 2D & 3D tasks, at this afternoon #CVPR2025 poster session (poster #376).
paper: arxiv.org/abs/2503.14405
code: github.com/naver/dune

Our work on "Reasoning in visual navigation..." presented as a "Highlight" by Boris Chidlovskii and Francesco Giuliari at #cvpr2025!
Interactive site, play around with dynamical models:
europe.naverlabs.com/research/pub...
Thanks @weinzaepfelp.bsky.social for the photo.
@steevenj7.bsky.social
Checkout MUSt3R and Pow3R during this morning session at #CVPR2025 (posters 82 & 84) and give a try to their code.
Get the Pow3R to integrate priors into your 3D reconstructions; and obtain nice SfM/SLAM reconstructions with MUSt3R by leverating a memory mechanism.
MUSt3R and Pow3R code the same day 😮!
All @naverlabseurope.bsky.social code & data can be accessed here europe.naverlabs.com/research/code/
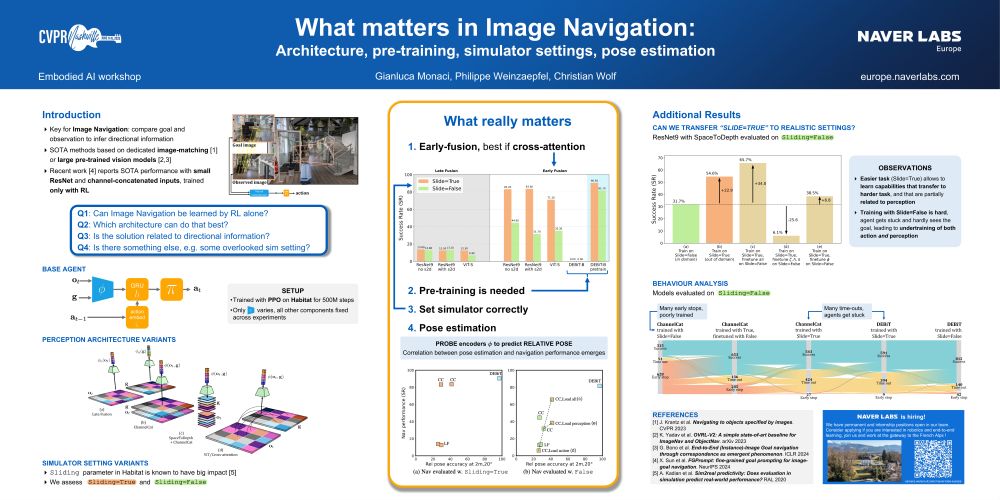

During today's #CVPR2025 workshops, I will present:
- What matters in ImageNav: architecture, pre-training, sim settings, pose (poster & highlight at the Embodied AI workshop)
- CondiMen: Conditional Multi-person Human Mesh Recovery (Poster at the Rhobin workshop and at the 3D Humans workshop)
Apparently, it is supposed to be a 1:1 replica of the Parthenon
11.06.2025 16:00 — 👍 2 🔁 0 💬 0 📌 0Somewhere on the greenway along the cumberland river
11.06.2025 14:20 — 👍 3 🔁 0 💬 0 📌 0



Good morning Nashville !
Few pics from an (really) early jet-lagged run
There should be some best poster design award at conferences 😀
06.06.2025 15:16 — 👍 7 🔁 1 💬 0 📌 0
Thanks Christian for the advertisement.
github link: github.com/naver/dune
There are likely pretty much related, but model merging is restricted to the exact same architecture, even for tiny details: like what if you wanna directly merge Dust3r or Mast3r that uses RoPE positional embed with another model that uses absolute pos. embed (like ViT models).
06.06.2025 12:42 — 👍 4 🔁 1 💬 0 📌 0Incorporating physics into embodied AI has massive impact on out-of-the-box robot navigation! @steevenj7.bsky.social & @chriswolfvision.bsky.social share what was learned in moving from simulation to the real world with #spatialAI ➡️ tinyurl.com/k83svt8a
03.06.2025 14:51 — 👍 12 🔁 5 💬 0 📌 1We have a new blog post on how we optimized end-to-end training of navigation in simulation with physical models, allowing fast and precise motion. The post is simplified, animated, and should be very accessible. Great work by the Spatial AI team, writing by Steeven, myself and the NLE Coms team.
03.06.2025 16:36 — 👍 9 🔁 2 💬 0 📌 0🔊 Only a few days left to apply to the #PAISS2025 summer school !!
This is a fantastic opportunity to learn and to network, especially for students 🎓
Watch till the end 😀
06.04.2025 12:36 — 👍 6 🔁 0 💬 0 📌 0





















