
We’re really excited to release this large collaborative work for unifying web agent benchmarks under the same roof.
In this TMLR paper, we dive in-depth into #BrowserGym and #AgentLab. We also present some unexpected performances from Claude 3.5-Sonnet
12.12.2024 17:55 — 👍 20 🔁 11 💬 1 📌 2

LLMs have a lot of potential for science, but scientists can be particularly sensitive to factuality, nuances, and hallucinations. The new ScholarQABench benchmark in this paper looks pretty useful for the community to monitor progress on LLMs for science. arxiv.org/html/2411.14199
25.11.2024 01:20 — 👍 1 🔁 1 💬 0 📌 0
Also, we are currently at NeurIPS in Vancouver! We will be presenting this work in the RBFM workshop on Saturday! Come say hi, and let’s spark some collaborations! 🚀
10.12.2024 18:34 — 👍 0 🔁 0 💬 0 📌 0
This was a monumental collaboration, and a huge thank you to all the co-authors, ServiceNow Research, Mila, and all the institutions involved for their incredible support! 🙏
10.12.2024 18:34 — 👍 0 🔁 0 💬 1 📌 0
We hope this effort aids the community in building more robust models for these tasks while emphasizing the importance of open and transparent data usage and release.
10.12.2024 18:34 — 👍 0 🔁 0 💬 1 📌 0

We evaluated several VLM models—both open and closed source—on BigDocs-Bench to build a leaderboard.
📊 Models trained on BigDocs outperformed all models on BigDocs-Bench tasks and delivered rebust performance on established benchmarks.
✅ Human evaluations confirmed their strong performance!
10.12.2024 18:34 — 👍 0 🔁 0 💬 1 📌 0

To validate the quality of the BigDocs datasets, we trained several VLMs on BigDocs-7.5M and evaluated their performance on document-specific and general VLM benchmarks.
The results? Training on BigDocs provides significant boosts compared to training on other datasets! 📈✨
10.12.2024 18:34 — 👍 0 🔁 0 💬 1 📌 0
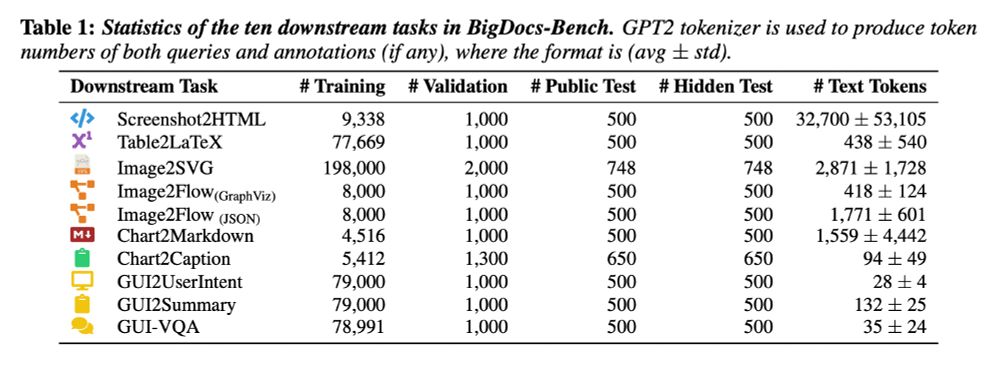

We introduce BigDocs-Bench, a set of benchmarks that focus on:
📄 Document Understanding
🌐 Web and GUI reasoning
👨💻 Code Generation
We also tackle complex outputs like SVG, LaTeX code, Markdown, and HTML, including very long and structured formats. Here are some examples
10.12.2024 18:34 — 👍 0 🔁 0 💬 1 📌 0
By sharing this journey, we aim to bring more transparency to how datasets are built—especially as data remains the most opaque aspect of model performance in today’s fast-moving AI landscape. 🌟
10.12.2024 18:34 — 👍 0 🔁 0 💬 1 📌 0

Building BigDocs was no small feat! We curated a large-scale dataset from diverse, license-friendly sources and documented the entire process.
10.12.2024 18:34 — 👍 1 🔁 0 💬 1 📌 0

🎉 Excited to introduce BigDocs!
An open, transparent multimodal dataset designed for:
📄 Documents
🌐 Web content
🖥️ GUI understanding
👨💻 Code generation from images
We’re also launching BigDocs-Bench:
➡️ Document, Web, GUI Visual reasoning
➡️ Converting images into JSON, Markdown, LaTeX, SVG, and more!
10.12.2024 18:34 — 👍 16 🔁 8 💬 1 📌 2
Professor,
Mila, Polytechnique Montreal, DIRO, UdeM
Distinguished Scientist, ServiceNow Research
https://sites.google.com/view/christopher-pal
Researcher, coder, entrepreneur, kind. CS PhD, ex-Google, ElementAI co-founder. En français: @fr.beaudoin.social Current project: https://numeno.ai #FreeOurFeeds
Working towards the safe development of AI for the benefit of all at Université de Montréal, LawZero and Mila.
A.M. Turing Award Recipient and most-cited AI researcher.
https://lawzero.org/en
https://yoshuabengio.org/profile/
AI @ OpenAI, Tesla, Stanford
Assistant Professor @Mila-Quebec.bsky.social
Co-Director @McGill-NLP.bsky.social
Researcher @ServiceNow.bsky.social
Alumni: @StanfordNLP.bsky.social, EdinburghNLP
Natural Language Processor #NLProc
Founder & executive & community builder & organizer & researcher
ML Collective (mlcollective.org)
Google DeepMind
rosanneliu.com
The AI community building the future!
Recently a principal scientist at Google DeepMind. Joining Anthropic. Most (in)famous for inventing diffusion models. AI + physics + neuroscience + dynamical systems.
Director, Max Planck Institute for Intelligent Systems; Chief Scientist Meshcapade; Speaker, Cyber Valley.
Building 3D humans.
https://ps.is.mpg.de/person/black
https://meshcapade.com/
https://scholar.google.com/citations?user=6NjbexEAAAAJ&hl=en&oi=ao
ML/AI researcher & former stats professor turned LLM research engineer. Author of "Build a Large Language Model From Scratch" (https://amzn.to/4fqvn0D) & reasoning (https://mng.bz/Nwr7).
Also blogging about AI research at magazine.sebastianraschka.com.
I lead Cohere For AI. Formerly Research
Google Brain. ML Efficiency, LLMs,
@trustworthy_ml.
Professor, Programmer in NYC.
Cornell, Hugging Face 🤗
Research Scientist Meta/FAIR, Prof. University of Geneva, co-founder Neural Concept SA. I like reality.
https://fleuret.org
DeepMind Professor of AI @Oxford
Scientific Director @Aithyra
Chief Scientist @VantAI
ML Lead @ProjectCETI
geometric deep learning, graph neural networks, generative models, molecular design, proteins, bio AI, 🐎 🎶
https://Answer.AI & https://fast.ai founding CEO; previous: hon professor @ UQ; leader of masks4all; founding CEO Enlitic; founding president Kaggle; various other stuff…
Co-founder and CEO at Hugging Face
Research Scientist at DeepMind. Opinions my own. Inventor of GANs. Lead author of http://www.deeplearningbook.org . Founding chairman of www.publichealthactionnetwork.org


















