
Had an amazing time presenting my research @cohereforai.bsky.social yesterday 🎤
In case you could not attend, feel free to check it out 👉
youtu.be/RCA22JWiiY8?...

@gsprd.be.bsky.social
PhD Student doing RL in POMDP at the University of Liège - Intern at McGill - gsprd.be
Had an amazing time presenting my research @cohereforai.bsky.social yesterday 🎤
In case you could not attend, feel free to check it out 👉
youtu.be/RCA22JWiiY8?...

Such an inspiring talk by @arkrause.bsky.social at #ICML today. The role of efficient exploration in Scientific discovery is fundamental and I really like how Andreas connects the dots with RL (theory).
17.07.2025 22:14 — 👍 15 🔁 2 💬 0 📌 0
ICML poster of the paper « A Theoretical Justification for Asymmetric Actor-Critic Algorithms » by Gaspard Lambrechts, Damien Ernst and Aditya Mahajan.
At #ICML2025, we will present a theoretical justification for the benefits of « asymmetric actor-critic » algorithms (#W1008 Wednesday at 11am).
📝 Paper: hdl.handle.net/2268/326874
💻 Blog: damien-ernst.be/2025/06/10/a...
🌟🌟Good news for the explorers🗺️!
Next week we will present our paper “Enhancing Diversity in Parallel Agents: A Maximum Exploration Story” with V. De Paola, @mircomutti.bsky.social and M. Restelli at @icmlconf.bsky.social!
(1/N)

Last week, I gave an invited talk on "asymmetric reinforcement learning" at the BeNeRL workshop. I was happy to draw attention to this niche topic, which I think can be useful to any reinforcement learning researcher.
Slides: hdl.handle.net/2268/333931.

Cover page of the PhD thesis "Reinforcement Learning in Partially Observable Markov Decision Processes: Learning to Remember the Past by Learning to Predict the Future" by Gaspard Lambrechts
Two months after my PhD defense on RL in POMDP, I finally uploaded the final version of my thesis :)
You can find it here: hdl.handle.net/2268/328700 (manuscript and slides).
Many thanks to my advisors and to the jury members.

TL;DR: Do not make the problem harder than it is! Using state information during training is provably better.
📝 Paper: arxiv.org/abs/2501.19116
🎤 Talk: orbi.uliege.be/handle/2268/...
A warm thank to Aditya Mahajan for welcoming me at McGill University and for his precious supervision.
While this work has considered fixed feature z = f(h) with linear approximators, we discuss possible generalizations in the conclusion.
Despite not matching the usual recurrent actor-critic setting, this analysis still provides insights into the effectiveness of asymmetric actor-critic algorithms.
The conclusion is that asymmetric learning is less sensitive to aliasing than symmetric learning.
Now, what is aliasing exactly?
The aliasing and inference terms arise from z = f(h) not being Markovian. They can be bounded by the difference between the approximate p(s|z) and exact p(s|h) beliefs.

Theorem showing the finite-time suboptimality bound for the asymmetric and symmetric actor-critic algorithms. The asymmetric algorithm has four terms: the natural actor-critic term, the gradient estimation term, the residual gradient term, and the average critic error. The symmetric algorithm has an additional term: the inference term.
Now, as far as the actor suboptimality is concerned, we obtained the following finite-time bounds.
In addition to the average critic error, which is also present in the actor bound, the symmetric actor-critic algorithm suffers from an additional "inference term".

Theorem showing the finite-time error bound for the asymmetric and symmetric temporal difference learning algorithms. The asymmetric algorithm has three terms: the temporal difference learning term, the function approximation term, and the bootstrapping shift term. The symmetric algorithm has an additional term: the aliasing term.
By adapting the finite-time bound from the symmetric setting to the asymmetric setting, we obtain the following error bounds for the critic estimates.
The symmetric temporal difference learning algorithm has an additional "aliasing term".

Title page of the paper "A Theoretical Justification for Asymmetric Actor-Critic Algorithms", written by Gaspard Lambrechts, Damien Ernst and Aditya Mahajan.
While this algorithm is valid/unbiased (Baisero & Amato, 2022), a theoretical justification for its benefit is still missing.
Does it really learn faster than symmetric learning?
In this paper, we provide theoretical evidence for this, based on an adapted finite-time analysis (Cayci et al., 2024).

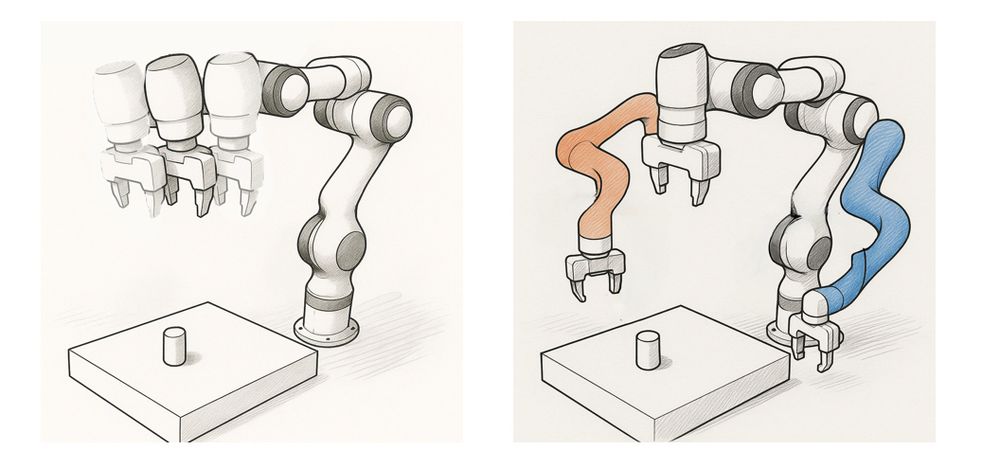
Figure showing the policy being passed the feature z = f(h) of the history, and the critic being passed both the feature z = f(h) of the history and the state s as input. The asymmetric critic and the policy are used together to form the sample policy-gradient expression.
However, with actor-critic algorithms, it can be noticed that the critic is not needed at execution!
As a result, the state can be an input of the critic, which becomes Q(s, z, a) in the asymmetric setting instead of Q(z, a) in the symmetric setting.

Figure showing the history h being compressed into a feature z = f(h) for then being passed to a policy g(a | z).
In a POMDP, the goal is to find an optimal policy π(a|z) that maps a feature z = f(h) of the history h to an action a.
In a privileged POMDP, the state can be used to learn a policy π(a|z) faster.
But note that the state cannot be an input of the policy, since it is not available at execution.

Table showing that the MDP assumes full state observability both during training and execution and that the POMDP assumes partial state observability both during training and execution, while the privileged POMDP assumes full state observability during training but partial state observability during execution.
Typically, classical RL methods assume:
- MDP: full state observability (too optimistic),
- POMDP: partial state observability (too pessimistic).
Instead, asymmetric RL methods assume:
- Privileged POMDP: asymmetric state observability (full at training, partial at execution).

Slide showing three recent successes of reinforcement learning that have used an asymmetric actor-critic algorithm: - Magnetic Control of Tokamak Plasma through Deep RL (Degrave et al., 2022). - Champion-Level Drone Racing using Deep RL (Kaufmann et al., 2023). - A Super-Human Vision-Based RL Agent in Gran Turismo (Vasco et al., 2024).
📝 Our paper "A Theoretical Justification for Asymmetric Actor-Critic Algorithms" was accepted at #ICML!
Never heard of "asymmetric actor-critic" algorithms? Yet, many successful #RL applications use them (see image).
But these algorithms are not fully understood. Below, we provide some insights.

📢 Deadline extended!
Submit your work to EWRL — now accepting papers until June 3rd AoE.
This year, we're also offering a fast track for papers accepted at other conferences ⚡
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/

Typst interface showing an example of Slydst code and the resulting slides.
Slydst, my Typst package for making simple slides, just got its 100th star on Github.
While I would not advise using Typst for papers yet, its markdown-like syntax allows to create slides in a few minutes, while supporting everything we love from LaTeX: equations.
github.com/glambrechts/...
📣 Hiring! I am looking for PhD/postdoc candidates to work on foundation models for science at @ULiege, with a special focus on weather and climate systems. 🌏 Three positions are open around deep learning, physics-informed FMs and inverse problems with FMs.
30.12.2024 12:21 — 👍 79 🔁 35 💬 4 📌 4
Check our work on max entropy RL! We introduce an off-policy method to maximize the entropy of the future state-action visitation distribution, leading to policies that explore effectively and achieve high performance 🎯
Link 📑 arxiv.org/abs/2412.06655
#RL #MaxEntRL #Exploration
How come I didn't know about this BeNeRL seminar series? It focuses on practical RL and seems really great!
www.benerl.org/seminar-seri...
I would have loved to hear Benjamin Eysenbach, Chris Lu and Edward Hu... Next one is on December 19th.
Hi Erfan, for now I am studying the theory of asymmetric actor-critic algorithms for POMDP. Afterwards, I plan on working with SSM-based WM, and maybe also on an asymmetric WM for POMDP. What about you?
27.11.2024 23:03 — 👍 0 🔁 0 💬 0 📌 0Hi Bluesky! I'm a PhD student researching #RL in #POMDP.
If you're also interested in:
- sequence models,
- world models,
- representation learning,
- asymmetric learning,
- generalization,
I'd love to connect, chat, or check out your work! Feel free to reply or message me.



















