📣 Call for Contributions: LEXam-v2 – A Benchmark for Legal Reasoning in AI
How well do today’s AI systems really reason about law?
We’re building a global benchmark based on real law school & bar exams.
🧵 Full details, scope, and how to contribute in the thread 👇
28.01.2026 15:11 — 👍 5 🔁 4 💬 1 📌 0

One joy of growing as a scholar & doer has been the pleasure of being supported to pay attention to other people’s excellent work and amplify it.
Next week I am publishing an article summarizing over 170 articles on AI + science + policy and tomorrow I get to email their authors to say thanks <3
15.11.2025 21:23 — 👍 12 🔁 3 💬 1 📌 0
 02.09.2025 07:39 — 👍 0 🔁 0 💬 0 📌 0
02.09.2025 07:39 — 👍 0 🔁 0 💬 0 📌 0
 02.09.2025 07:36 — 👍 0 🔁 0 💬 1 📌 0
02.09.2025 07:36 — 👍 0 🔁 0 💬 1 📌 0
 02.09.2025 05:52 — 👍 1 🔁 0 💬 1 📌 0
02.09.2025 05:52 — 👍 1 🔁 0 💬 1 📌 0

It's remarkable how early Ford Foundation was to law and technology in the midcentury
02.09.2025 01:45 — 👍 2 🔁 0 💬 0 📌 0
 02.09.2025 01:42 — 👍 0 🔁 0 💬 0 📌 0
02.09.2025 01:42 — 👍 0 🔁 0 💬 0 📌 0
 02.09.2025 00:16 — 👍 1 🔁 0 💬 0 📌 0
02.09.2025 00:16 — 👍 1 🔁 0 💬 0 📌 0


this is what you see moments before going down a cyberspace and law rabbit hole
01.09.2025 20:57 — 👍 1 🔁 0 💬 1 📌 0

 30.08.2025 15:59 — 👍 0 🔁 0 💬 0 📌 0
30.08.2025 15:59 — 👍 0 🔁 0 💬 0 📌 0
 30.08.2025 15:58 — 👍 0 🔁 0 💬 1 📌 0
30.08.2025 15:58 — 👍 0 🔁 0 💬 1 📌 0
it finally happened (my 3090 overheated and emergency shut off)
01.08.2025 05:59 — 👍 1 🔁 0 💬 0 📌 0
The Rise of the Compliant Speech Platform
Content moderation is becoming a “compliance function,” with trust and safety operations run like factories and audited like investment banks.
Here’s the article. I’ve had more positive feedback on it than things I spent a year on.
Apparently describing a problem that thousands of Trust and Safety people are seeing but also see the world ignoring is a good way to win hearts and minds :)
www.lawfaremedia.org/article/the-...
01.08.2025 00:09 — 👍 30 🔁 10 💬 1 📌 0

“The possibilities of the pole” @hoctopi.bsky.social
18.07.2025 03:07 — 👍 0 🔁 0 💬 0 📌 0

Eliza asking after an anti-suffering future of reproductive technology (the piece looks incredible)
18.07.2025 03:04 — 👍 0 🔁 0 💬 1 📌 0

@kevinbaker.bsky.social “The rules appear inevitable, natural, reasonable. We forget they were drawn by human hands.”
18.07.2025 02:43 — 👍 9 🔁 0 💬 1 📌 0

At the Kernel 5 issue launch!
18.07.2025 02:43 — 👍 3 🔁 0 💬 1 📌 0
After having such a great time at #CHI2025 and #FAccT2025, I wanted to share some of my favorite recent papers here!
I'll aim to post new ones throughout the summer and will tag all the authors I can find on Bsky. Please feel welcome to chime in with thoughts / paper recs / etc.!!
🧵⬇️:
14.07.2025 17:02 — 👍 55 🔁 10 💬 2 📌 2

Kernel Magazine
Issue 5: Rules Launch Party
July 17
6:30-9pm
SF
Gray Area
The illustration behind this text is a mix of gold chess pieces and purple snakes on a chessboard pattern
lu.ma/k5-sf
i am launching a magazine with @kevinbaker.bsky.social and the rest of the reboot collective on thursday at gray area! you should be there!
open.substack.com/pub/reboothq...
15.07.2025 21:25 — 👍 14 🔁 4 💬 0 📌 0

A close-up view of the Golden Gate Bridge in the fog
I've arrived in the 🌁Bay Area🌁, where I'll be spending the summer as a research fellow at Stanford's RegLab! If you're also here, LMK and let's get a meal / go on a hike / etc!!
01.07.2025 18:58 — 👍 9 🔁 1 💬 0 📌 0

"Bias Delayed is Bias Denied? Assessing the Effect of Reporting Delays on Disparity Assessments"
Conducting disparity assessments at regular time intervals is critical for surfacing potential biases in decision-making and improving outcomes across demographic groups. Because disparity assessments fundamentally depend on the availability of demographic information, their efficacy is limited by the availability and consistency of available demographic identifiers. While prior work has considered the impact of missing data on fairness, little attention has been paid to the role of delayed demographic data. Delayed data, while eventually observed, might be missing at the critical point of monitoring and action -- and delays may be unequally distributed across groups in ways that distort disparity assessments. We characterize such impacts in healthcare, using electronic health records of over 5M patients across primary care practices in all 50 states. Our contributions are threefold. First, we document the high rate of race and ethnicity reporting delays in a healthcare setting and demonstrate widespread variation in rates at which demographics are reported across different groups. Second, through a set of retrospective analyses using real data, we find that such delays impact disparity assessments and hence conclusions made across a range of consequential healthcare outcomes, particularly at more granular levels of state-level and practice-level assessments. Third, we find limited ability of conventional methods that impute missing race in mitigating the effects of reporting delays on the accuracy of timely disparity assessments. Our insights and methods generalize to many domains of algorithmic fairness where delays in the availability of sensitive information may confound audits, thus deserving closer attention within a pipeline-aware machine learning framework.
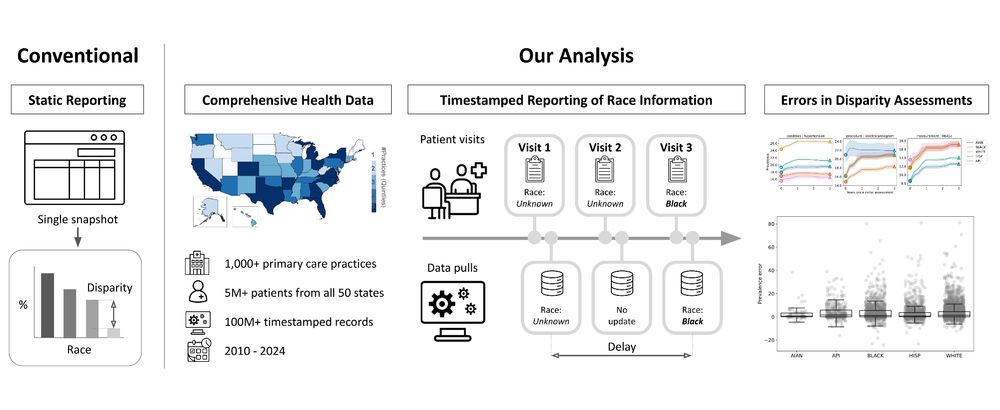
Figure contrasting a conventional approach to conducting disparity assessments, which is static, to the analysis we conduct in this paper. Our analysis (1) uses comprehensive health data from over 1,000 primary care practices and 5 million patients across the U.S., (2) timestamped information on the reporting of race to measure delay, and (3) retrospective analyses of disparity assessments under varying levels of delay.
I am presenting a new 📝 “Bias Delayed is Bias Denied? Assessing the Effect of Reporting Delays on Disparity Assessments” at @facct.bsky.social on Thursday, with @aparnabee.bsky.social, Derek Ouyang, @allisonkoe.bsky.social, @marzyehghassemi.bsky.social, and Dan Ho. 🔗: arxiv.org/abs/2506.13735
(1/n)
24.06.2025 14:51 — 👍 13 🔁 4 💬 1 📌 3

A screenshot of our paper's:
Title: A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms
Authors: Emma Harvey, Rene Kizilcec, Allison Koenecke
Abstract: Increasingly, individuals who engage in online activities are expected to interact with large language model (LLM)-based chatbots. Prior work has shown that LLMs can display dialect bias, which occurs when they produce harmful responses when prompted with text written in minoritized dialects. However, whether and how this bias propagates to systems built on top of LLMs, such as chatbots, is still unclear. We conduct a review of existing approaches for auditing LLMs for dialect bias and show that they cannot be straightforwardly adapted to audit LLM-based chatbots due to issues of substantive and ecological validity. To address this, we present a framework for auditing LLM-based chatbots for dialect bias by measuring the extent to which they produce quality-of-service harms, which occur when systems do not work equally well for different people. Our framework has three key characteristics that make it useful in practice. First, by leveraging dynamically generated instead of pre-existing text, our framework enables testing over any dialect, facilitates multi-turn conversations, and represents how users are likely to interact with chatbots in the real world. Second, by measuring quality-of-service harms, our framework aligns audit results with the real-world outcomes of chatbot use. Third, our framework requires only query access to an LLM-based chatbot, meaning that it can be leveraged equally effectively by internal auditors, external auditors, and even individual users in order to promote accountability. To demonstrate the efficacy of our framework, we conduct a case study audit of Amazon Rufus, a widely-used LLM-based chatbot in the customer service domain. Our results reveal that Rufus produces lower-quality responses to prompts written in minoritized English dialects.
I am so excited to be in 🇬🇷Athens🇬🇷 to present "A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms" by me, @kizilcec.bsky.social, and @allisonkoe.bsky.social, at #FAccT2025!!
🔗: arxiv.org/pdf/2506.04419
23.06.2025 14:44 — 👍 31 🔁 10 💬 1 📌 2

"Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese" Abstract:
While the capabilities of Large Language Models (LLMs) have been studied in both Simplified and Traditional Chinese, it is yet unclear whether LLMs exhibit differential performance when prompted in these two variants of written Chinese. This understanding is critical, as disparities in the quality of LLM responses can perpetuate representational harms by ignoring the different cultural contexts underlying Simplified versus Traditional Chinese, and can exacerbate downstream harms in LLM-facilitated decision-making in domains such as education or hiring. To investigate potential LLM performance disparities, we design two benchmark tasks that reflect real-world scenarios: regional term choice (prompting the LLM to name a described item which is referred to differently in Mainland China and Taiwan), and regional name choice (prompting the LLM to choose who to hire from a list of names in both Simplified and Traditional Chinese). For both tasks, we audit the performance of 11 leading commercial LLM services and open-sourced models -- spanning those primarily trained on English, Simplified Chinese, or Traditional Chinese. Our analyses indicate that biases in LLM responses are dependent on both the task and prompting language: while most LLMs disproportionately favored Simplified Chinese responses in the regional term choice task, they surprisingly favored Traditional Chinese names in the regional name choice task. We find that these disparities may arise from differences in training data representation, written character preferences, and tokenization of Simplified and Traditional Chinese. These findings highlight the need for further analysis of LLM biases; as such, we provide an open-sourced benchmark dataset to foster reproducible evaluations of future LLM behavior across Chinese language variants (this https URL).
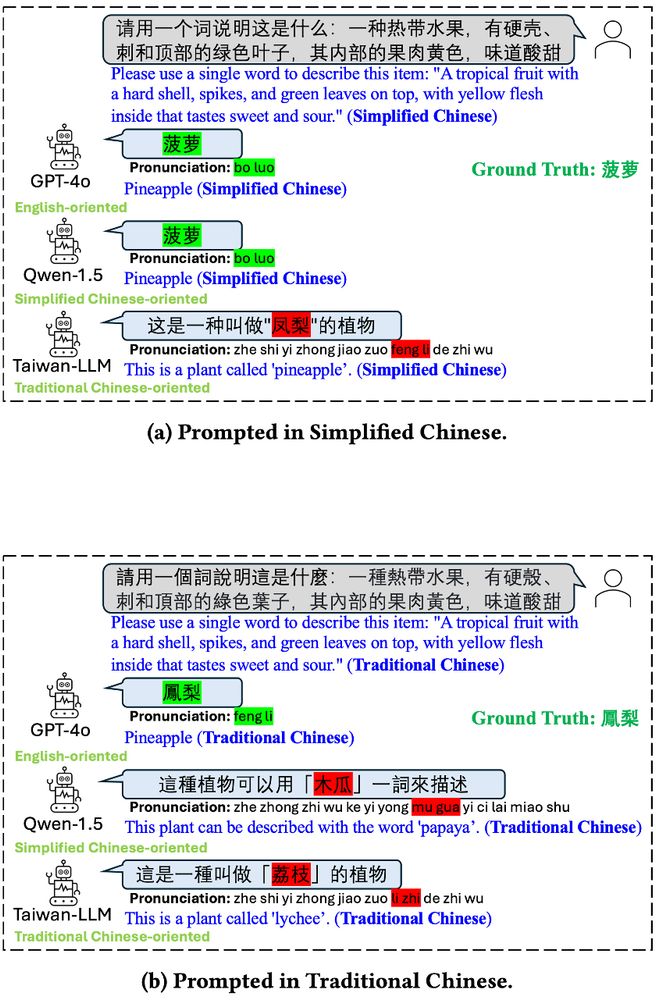
Figure showing that three different LLMs (GPT-4o, Qwen-1.5, and Taiwan-LLM) may answer a prompt about pineapples differently when asked in Simplified Chinese vs. Traditional Chinese.
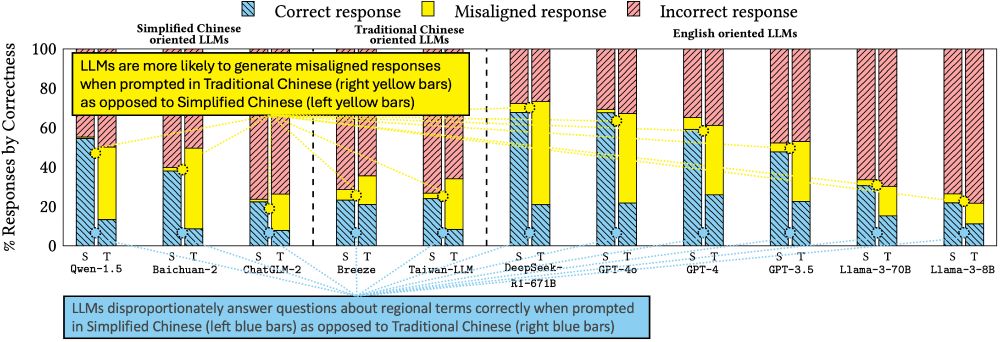
Figure showing that LLMs disproportionately answer questions about regional-specific terms (like the word for "pineapple," which differs in Simplified and Traditional Chinese) correctly when prompted in Simplified Chinese as opposed to Traditional Chinese.
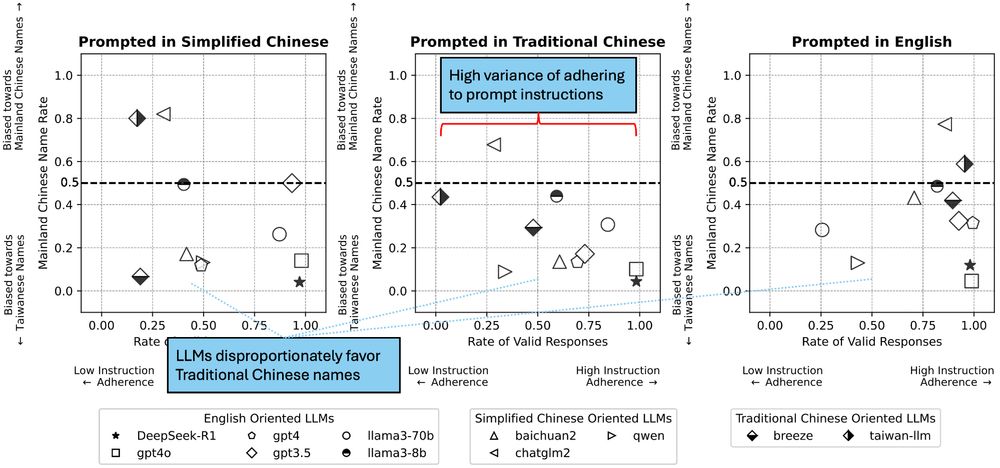
Figure showing that LLMs have high variance of adhering to prompt instructions, favoring Traditional Chinese names over Simplified Chinese names in a benchmark task regarding hiring.
🎉Excited to present our paper tomorrow at @facct.bsky.social, “Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese”, with @brucelyu17.bsky.social, Jiebo Luo and Jian Kang, revealing 🤖 LLM performance disparities. 📄 Link: arxiv.org/abs/2505.22645
22.06.2025 21:15 — 👍 17 🔁 4 💬 1 📌 3
I am at FAccT 2025 in Athens, feel free to grab me if you want to chat.
23.06.2025 08:43 — 👍 9 🔁 1 💬 0 📌 1
Please come see us at the RC Trust Networking Event!
You can sign up with the QR Codes around the venues and get some free drinks! 🙂↕️
#FAccT2025
23.06.2025 13:23 — 👍 4 🔁 3 💬 1 📌 0

New paper available - "Bureaucratic Backchannel: How r/PatentExaminer Navigates #AI Governance" which investigates how examiners navigate dual roles through a qualitative analysis of a Reddit community where U.S. Patent & Trademark Office employees discuss their work🔗📜👇
06.06.2025 20:37 — 👍 2 🔁 1 💬 1 📌 0

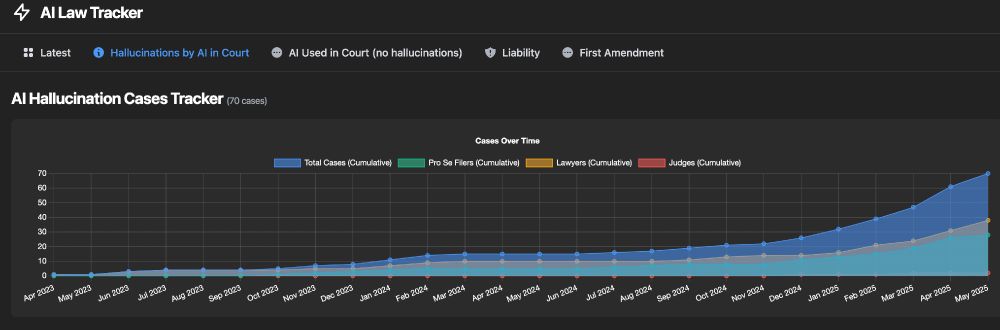
Another hallucinated citation in court. At this point, our tracker is up to ~70 cases worldwide of hallucinated citations in court, including hallucinations from 2 adjudicators.
New Case: storage.courtlistener.com/recap/gov.us...
Tracker: www.polarislab.org/ai-law-track...
21.05.2025 22:41 — 👍 6 🔁 3 💬 0 📌 0

American Dragnet | Data-Driven Deportation in the 21st Century
One of two American adults is in a law enforcement face recognition database. An investigation.
Three years ago, we released “American Dragnet: Data-Driven Deportation in the 21st Century.” The report describes the surveillance apparatus that Trump is using to target immigrants, activists and anyone else who challenges his agenda. We’re re-releasing it today with a new foreword.
15.05.2025 14:49 — 👍 20 🔁 14 💬 1 📌 1
Research Scientist @ Stanford Cyber Policy Center. Studying online information seeking, influence, and ways to more accurately model how people interact with online systems.
Behavioral Scientist.
Lately, I've been thinking (and posting) about: AI+Psych, Personal Finance, Consumer Behavior. Civically engaged, so I occasionally post about that too.
Working Group of the NYC Democratic Socialists of America investigating the political, social, and economic effects of new technology.
https://linktr.ee/nycdsatechaction
Researcher, technologist, artist. 🐚 Public interest tech at Data & Society @datasociety.bsky.social. she/her 〰️
Prev: Head of Open Source Research & Investigations @mozilla.org Foundation, Tech Fellow @hrw.org, engineering & art @ITP-NYU.
nyc/slc
💼 Assistant Professor @Yale.edu & Just Tech Fellow @SSRC.org
🎓 Research on #Data + #Work + #Platforms
🌐 https://posada.website/
investigative journalist @consumerreports.org • tech podcastin’ @twit.tv • previously @ The Information & Wired • @parismartineau on the other site
send tips: paris@cr.org, or securely via Signal (267.797.8655) or Proton (tips@paris.nyc)
👩💻 paris.nyc
Solidarity Bioeconomy and thoughts about books.
she/ella. not exactly the voice of reason. scaffolding @eff. centroamericana. cartas al abismo en https://www.cartasalabismo.com/
Futures of work. Writing, researching, teaching, lefting. Ruthless everything, existing. http://dmgreene.net
newsletters @ nyt. ex qz, chicago mag, chicago reader. i'm not a miracle worker, i'm a janitor
director of creative research @ the metro ny library council; resigned full professor of media studies, art history + anthropology
architecture, archives, 🎨, cities, 🐕, infrastructure, libraries, 🗺️, sound++
nyc + upstate
wordsinspace.net
online ecosystem keystone species (uc davis ecology phd), they/them
She/her. Data Science Manager and Algorithmic Justice Specialist at ACLU. Personal account.
No longer in good standing with the New York State bar
My newsletter: StringinaMaze.net
Associate professor of social computing at UW CSE, leading @socialfutureslab.bsky.social
social.cs.washington.edu
assistant professor in information, university of michigan. i have big intellectual feelings about language and technology.
https://tisjune.github.io/
she/her
Associate Professor at UM School of Information researching social computing, HCI, designing trans tech, social media, identity transitions, content moderation. 🏳️⚧️ he/him
CS PhD Student at the University of Rochester
Legal scholar & Philosopher. Assistant Professor of Law @UofT Law. Author of 'Algorithmic Rule By Law' (CUP, 2025). Previously at EU Commission's AI HLEG, Council of Europe's CAI, KU Leuven & NYU Law. UChicago alum.





















