most people want a quick and simple answer to why AI systems encode/exacerbate societal and historical bias/injustice and due to the reductive but common thinking of "bias in, bias out," the obvious culprit often is training data but this is not entirely true
1/
24.11.2024 16:26 — 👍 611 🔁 226 💬 26 📌 44
The biggest update in 3D reconstruction world - VGGT (new weights) has been released for commercial usage as well.
Kudos to @jianyuanwang.bsky.social to make this happen!
github.com/facebookrese...
04.08.2025 08:26 — 👍 12 🔁 3 💬 2 📌 0

AI and Fraternity, Abeba Birhane, AI Accountability Lab
I envision a future where human dignity, justice, peace, kindness, care, respect, accountability, and rights and freedoms serve as the north stars that guide AI development and use. Realising these ideals can’t happen without intentional tireless work, dialogues, and confrontations of ugly realities – even if they are uncomfortable to deal with. This starts with deciphering hype from reality. Pervasive narratives portray AI as a magical, fully autonomous entity approaching a God-like omnipotence and omniscience. In reality, audits of AI systems reveal a consistent failure to deliver on grandiose promises and suffer from all kinds of shortcomings, issues often swept under the rug. AI in general, and GenAI in particular, encodes and exacerbates historical stereotypes, entrenches harmful societal norms, and amplifies injustice. A robust body of evidence demonstrates that — from hiring, welfare allocation, medical care allocation to anything in between — deployment of AI is widening inequity, disproportionately impacting people at the margins of society and concentrating power and influence in the hands of few. Major actors—including Google, Microsoft, Amazon, Meta, and OpenAI—have willingly aligned with authoritarian regimes and proactively abandoned their pledges to fact-check, prevent misinformation, respect diversity and equity, refrain from using AI for weapons development, while retaliating against critique. The aforementioned vision can’t and won’t happen without confrontation of these uncomfortable facts. This is precisely why we need active resistance and refusal of unreliable and harmful AI systems; clearly laid out regulation and enforcement; and shepherding of the AI industry towards transparency and accountability of responsible bodies. "Machine agency" must be in service of human agency and empowerment, a coexistence that isn't a continuation of modern tech corporations’ inequality-widening,
so I am one of the 12 people (including the “god-fathers of AI”) that will be at the Vatican this September for a two full-day working group on the Future of AI
here is my Vatican approved short provocation on 'AI and Fraternity' for the working group
04.08.2025 11:31 — 👍 532 🔁 157 💬 31 📌 16
Deadlines for ICLR 2026 have been communicated on the official site:
Abstract: Sep 19 '25 (Anywhere on Earth)
Paper: Sep 24 '25 (Anywhere on Earth)
iclr.cc/Conferences/...
ICLR 2026 will happen in Brazil! ❤️
(Don't fall for the predatory conferences with the same name)
25.06.2025 09:06 — 👍 23 🔁 8 💬 0 📌 0
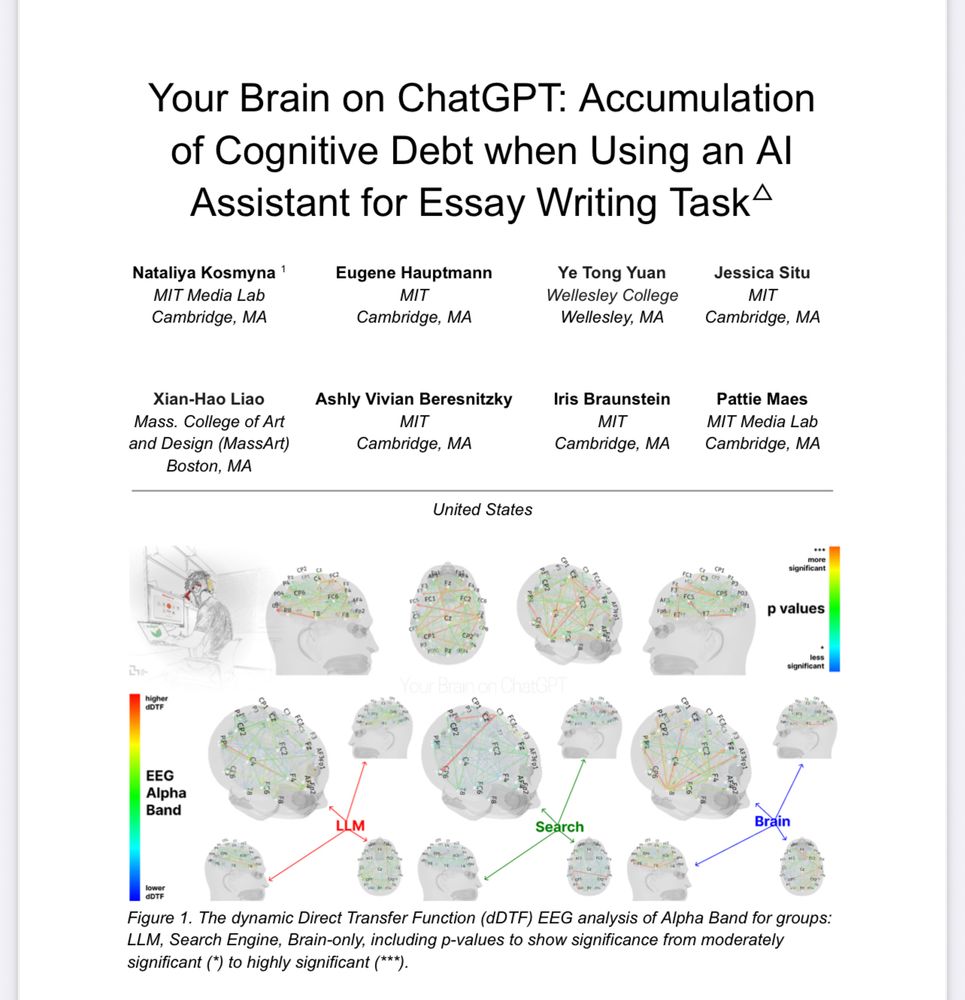
New research from MIT found that those who used ChatGPT can’t remember any of the content of their essays.
Key takeaway: the product doesn’t suffer, but the process does. And when it comes to essays, the process *is* how they learn.
arxiv.org/pdf/2506.088...
18.06.2025 07:32 — 👍 3743 🔁 1542 💬 204 📌 382
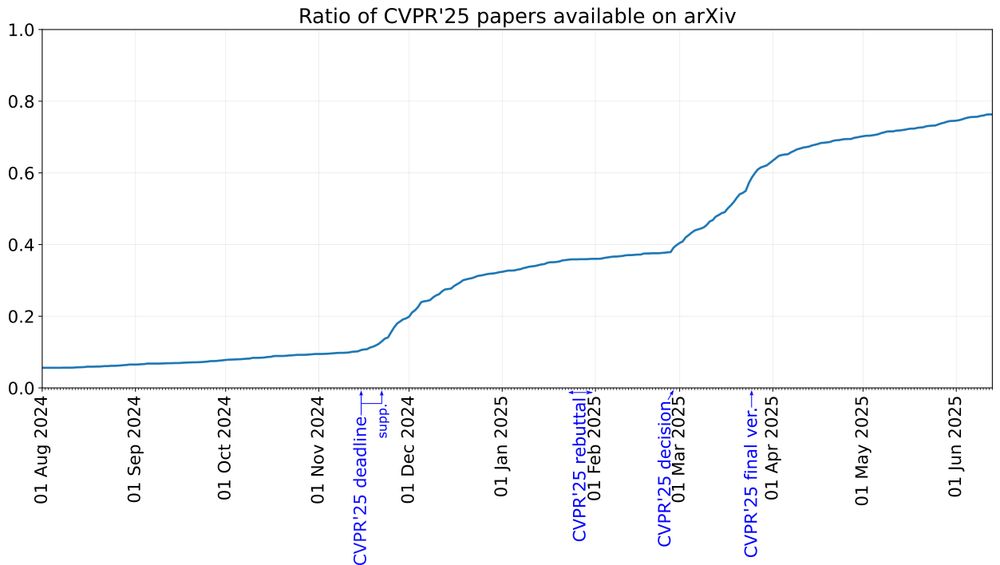
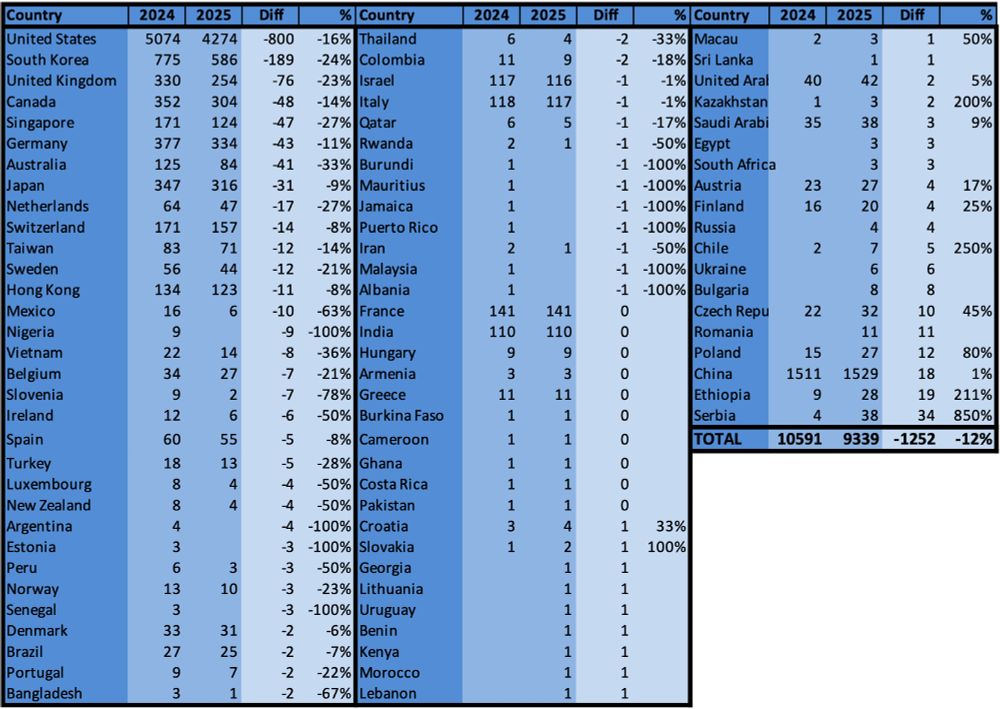
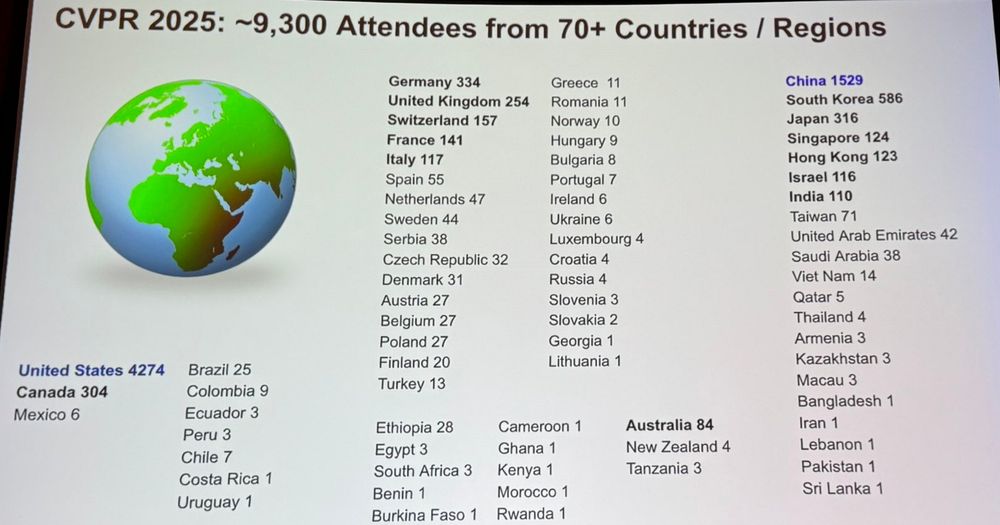
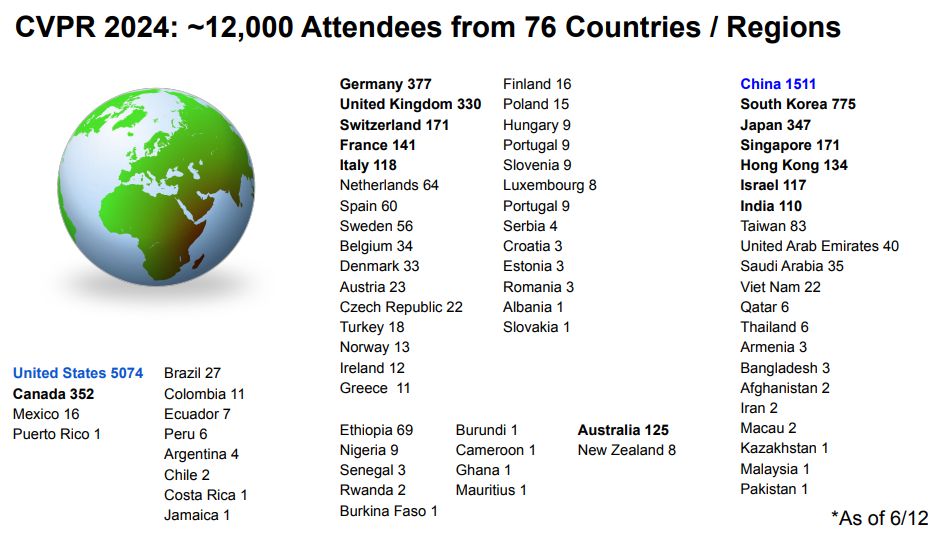
When were #CVPR2025 papers available on arXiv? 👇
17.06.2025 11:52 — 👍 39 🔁 9 💬 2 📌 0
I have created a starter pack with researchers from Naver Labs Europe @naverlabseurope.bsky.social: we are in Grenoble, France, and we do research in AI for robotics, computer vision, NLP, machine learning, HRI.
go.bsky.app/JdTFu4Q
14.06.2025 19:05 — 👍 33 🔁 6 💬 1 📌 1

Our work on "Reasoning in visual navigation..." presented as a "Highlight" by Boris Chidlovskii and Francesco Giuliari at #cvpr2025!
Interactive site, play around with dynamical models:
europe.naverlabs.com/research/pub...
Thanks @weinzaepfelp.bsky.social for the photo.
@steevenj7.bsky.social
14.06.2025 17:33 — 👍 10 🔁 4 💬 0 📌 0
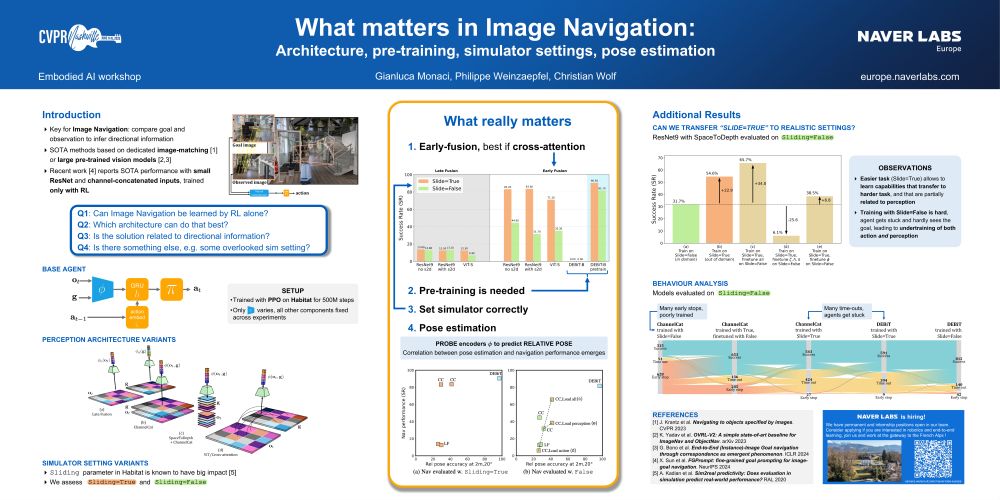

During today's #CVPR2025 workshops, I will present:
- What matters in ImageNav: architecture, pre-training, sim settings, pose (poster & highlight at the Embodied AI workshop)
- CondiMen: Conditional Multi-person Human Mesh Recovery (Poster at the Rhobin workshop and at the 3D Humans workshop)
12.06.2025 12:18 — 👍 10 🔁 4 💬 0 📌 0
Paper: arxiv.org/abs/2503.19777
Code: github.com/vladan-stojn...
Demo: huggingface.co/spaces/stojn...
Work with @skamalas.bsky.social, Jiri Matas, and @gtolias.bsky.social.
13.06.2025 12:02 — 👍 2 🔁 1 💬 0 📌 0
Wanna the outstanding performance of MASt3R while using a ViT-B or ViT-S encoder instead of its ViT-L one? Don't miss how we build DUNE, a single encoder for diverse 2D & 3D tasks, at this afternoon #CVPR2025 poster session (poster #376).
paper: arxiv.org/abs/2503.14405
code: github.com/naver/dune
15.06.2025 12:02 — 👍 18 🔁 6 💬 0 📌 0
Are you at @cvprconference.bsky.social? Come by our poster!
📅 Sat 14/6, 10:30-12:30
📍 Poster #395, ExHall D
13.06.2025 05:09 — 👍 17 🔁 9 💬 0 📌 0

💜 Huge thanks to our amazing organizers for making #WiCV
@cvprconference.bsky.social 2025 possible! 🙌
After 6+ months of near-daily work by 9 dedicated organizers, it’s exciting to see everything come together.
So proud of this amazing team! 💪✨
12.06.2025 20:55 — 👍 15 🔁 3 💬 0 📌 0
wait a minute... is this the Acro... :P
11.06.2025 13:52 — 👍 1 🔁 0 💬 1 📌 0
You woke up early in the morning jet-lagged and having a hard time deciding for a workshop today @cvprconference.bsky.social ?
Here's a reliable choice for you: our workshop on 🛟 Uncertainty Quantification for Computer Vision!
🗓️ Day: Wed, Jun 11
📍Room: 102 B
#CVPR2025 #UNCV2025
11.06.2025 11:33 — 👍 9 🔁 3 💬 0 📌 0

Have you heard about HD-EPIC?
Attending #CVPR2025
Multiple opportunities to know about the most highly-detailed video dataset with a digital twin, long-term object tracks, VQA,…
hd-epic.github.io
1. Find any of the 10 authors attending @cvprconference.bsky.social
– identified by this badge.
🧵
10.06.2025 21:48 — 👍 5 🔁 3 💬 1 📌 0
Check out our new paper in #CVPR2025! We test the limits of multi-teacher distillation to get one of the most versatile encoders yet. Mixing DINOv2 semantics 🦕, MASt3R multi-view reconstruction 📸📸...📸 and Human Mesh Recovery 🕺💃...🏌️♂️
Check our project page: europe.naverlabs.com/research/pub...
09.06.2025 14:05 — 👍 3 🔁 1 💬 0 📌 0
10/ 💬 Both papers tackle generalization head-on —
One by building a universal encoder from heterogeneous knowledge, the other by refining language-driven predictions without training.
Don't forget to check them out at #CVPR2025 in Nashville! 🎸
09.06.2025 11:07 — 👍 5 🔁 1 💬 0 📌 0
GitHub - vladan-stojnic/LPOSS: Code for LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation (CVPR2025)
Code for LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation (CVPR2025) - vladan-stojnic/LPOSS
9/ 📈 Results:
→ Substantial mIoU boost on 8 datasets
→ LPOSS+ especially shines for boundary precision
→ Outperforms many VLM-based methods without training
Work w/ Vladan @stojnicv.xyz and Giorgos @gtolias.bsky.social from CTU in Prague
Code: github.com/vladan-stojn...
Demo: hf.co/spaces/stojn...
09.06.2025 11:07 — 👍 5 🔁 0 💬 1 📌 0
8/ 🔁 LPOSS stages:
🔸 LPOSS: Refines patch-level predictions
🔹 LPOSS+: Refines on pixel-level using upsampled LPOSS output
✅ Uses DINO features + spatial cues for affinity
✅ Totally training-free!
09.06.2025 11:07 — 👍 4 🔁 0 💬 1 📌 0
7/ 🚫 VLMs are great at training-free segmentation, but:
* Predictions are patch-based (low-res)
* Predictions are performed independently at each patch (noisy)
LPOSS improves this with test-time label propagation, without fine-tuning.
09.06.2025 11:07 — 👍 5 🔁 0 💬 1 📌 0
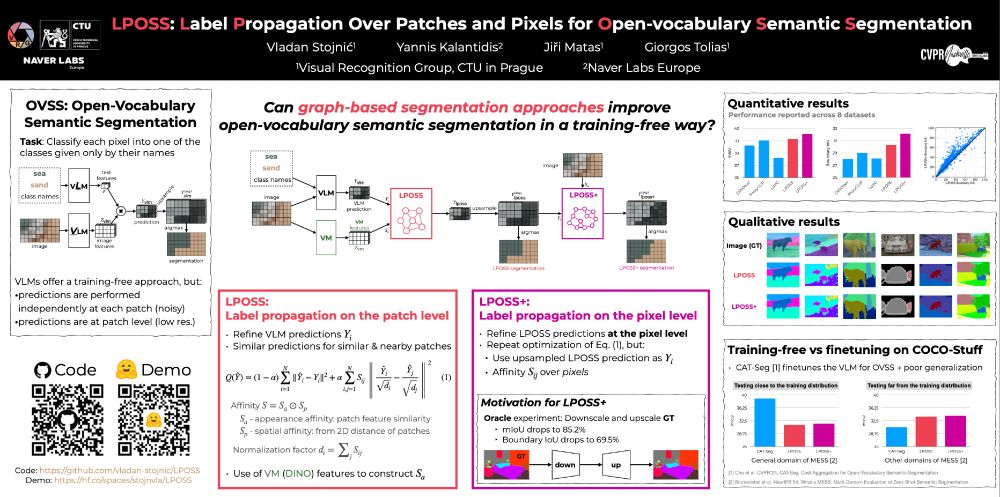
6/ 📄 Paper 2:
"LPOSS: Label Propagation Over Patches and Pixels for Open-Vocabulary Semantic Segmentation"
Can graph-based label propagation refine weak, patch-level predictions from VLMs like CLIP? We say yes — introducing LPOSS and LPOSS+.
09.06.2025 11:07 — 👍 7 🔁 1 💬 1 📌 0

DUNE: Distilling a Universal Encoder from heterogenous 2D and 3D teachers
CVPR 2025 publication
5/ Project page: europe.naverlabs.com/dune
Work with Bulent Sariyildiz @mbsariyildiz.bsky.social Diane Larlus @dlarlus.bsky.social Philippe Weinzaepfel @weinzaepfelp.bsky.social Pau de Jorge @pdejorge.bsky.social and Thomas Lucas at NAVER LABS Europe @naverlabseurope.bsky.social
09.06.2025 11:07 — 👍 4 🔁 0 💬 1 📌 0
3/ 🔍 DUNE is trained from heterogeneous teachers using heterogeneous data:
🟧 DINOv2 (2D foundation model - Oquab et al @ Meta)
🟥 MAST3R (3D foundation model - @vincentleroy.bsky.social et al @ NAVER LABS Europe - )
🟨 Multi-HMR (3D human perception - @fbaradel.bsky.social et al @ NAVER LABS Europe)
09.06.2025 11:07 — 👍 6 🔁 0 💬 1 📌 0
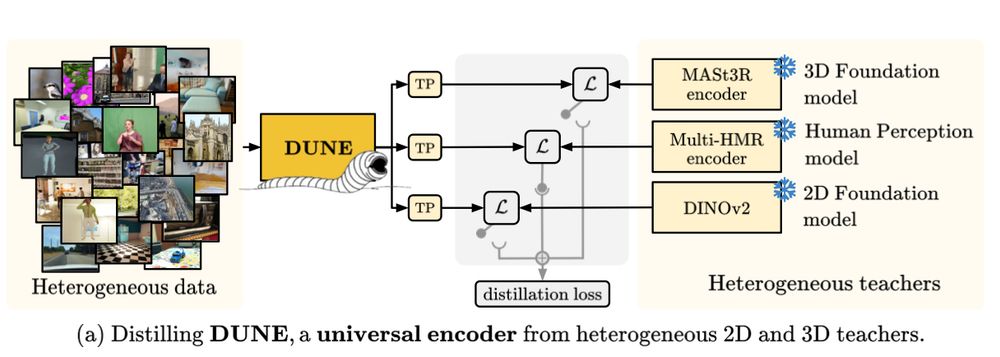
2/ 🧠 Why DUNE?
→ 2D & 3D vision models (e.g., segmentation, mono- or binocular depth, human mesh, 3D reconstruction) are siloed.
→ Can we distill their knowledge into a single universal encoder?
Yes — using multi-teacher distillation with transformer projectors, teacher dropping, and more.
09.06.2025 11:07 — 👍 5 🔁 0 💬 1 📌 0

1/ 📄 Paper 1:
"DUNE: Distilling a UNiversal Encoder from Heterogeneous 2D and 3D Teachers"
We propose DUNE: a ViT-based encoder distilled from multiple specialized 2D & 3D foundation models to unify visual tasks across 2D, 3D and human understanding.
09.06.2025 11:07 — 👍 18 🔁 5 💬 2 📌 2
🧵 Two new papers at #CVPR2025 on generalization in visual representations — covering both universal encoders for 2D and 3D tasks, and open-vocabulary semantic segmentation
Let's dive in! 👇
09.06.2025 11:07 — 👍 23 🔁 3 💬 1 📌 0
Tackling climate change with machine learning. We facilitate cooperation and provide resources for those working in this area. Share is not endorsement. // https://www.climatechange.ai/
AI, robotics, and other stuff. Currently AI @ agility robotics
Former Hello Robot, NVIDIA, Meta.
Writing about robots https://itcanthink.substack.com/
All opinions my own
🇪🇺 ELLIOT is a Horizon Europe project developing the next generation of open and trustworthy Multimodal Generalist Foundation Models — advancing open, general-purpose AI rooted in European values. 🤖📊
it's a website (and a podcast, and a newsletter) about humans and technology, made by four journalists you might already know. like and subscribe: 404media.co
Senior Researcher at the CVG Group at ETH Zurich
Principal research scientist at Naver Labs Europe, I am interested in most aspects of computer vision, including 3D scene reconstruction and understanding, visual localization, image-text joint representation, embodied AI, ...
CNRS Researcher in maths & computer science. My (current) focus is machine learning and optimization. I live & work in Nice 🇫🇷
website: https://samuelvaiter.com
Anti-cynic. Towards a weirder future. Reinforcement Learning, Autonomous Vehicles, transportation systems, the works. Asst. Prof at NYU
https://emerge-lab.github.io
https://www.admonymous.co/eugenevinitsky
Workshop on Fine-Grained Visual Categorization (FGVC) - CVPR
Nashville, June 11, 9am-17pm
Room: 104 E
https://sites.google.com/view/fgvc12
PhD student in computer vision at Imagine, ENPC
🇹🇷🇨🇭 PhD student @ ETH Zurich & Max Planck Institute.
Working on generative video models and 3D vision.
https://three-bee.github.io
Research Scientist at Naver Labs Europe | ex PhD at Oxford
Current: Researcher @ Denso IT lab (Tokyo).
Prev: PhD @UPC, Postdoc @ NII
ML Engineer at NVIDIA. Previously: Stealth GPU startup; Stability AI; AMD; Autodesk; CEO of 2 startups (3D + AI). Toronto, Canada
Postdoctoral Researcher @ Inria Montpellier (IROKO, Pl@ntNet)
SSL for plant species and diseases recognition in images
Interested in Computer Vision, Natural Language Processing, and Machine Listening
Website: ilyassmoummad.github.io
M.Eng. ECE NTUA, Intern at Visual Recognition Group CTU. Interested in Computer Vision Research.
Director of Science, NAVER LABS Europe
PhD student with Andreas Geiger and IMPRS-IS.
Studying embodied intelligence via autonomous driving.
The AI Now Institute produces diagnosis and actionable policy research on artificial intelligence.
Find us at https://ainowinstitute.org/