Will be at ACL this week! #ACL2025 #ACL2025NLP
Presenting Tian Yun’s paper on abstract reasoners at CoNLL on Thursday.
I’ve been investigating how LLMs internally compose functions lately. Happy to chat about that (among other things) and hang out in Vienna!
28.07.2025 05:09 — 👍 0 🔁 0 💬 1 📌 0
Curious how many papers were assigned to reviewers on average! Review quality seems better than average from my small sample size. Wondering if that correlates with a lower reviewer load? E.g. I only received 2 papers to review.
29.05.2025 18:49 — 👍 0 🔁 0 💬 0 📌 0
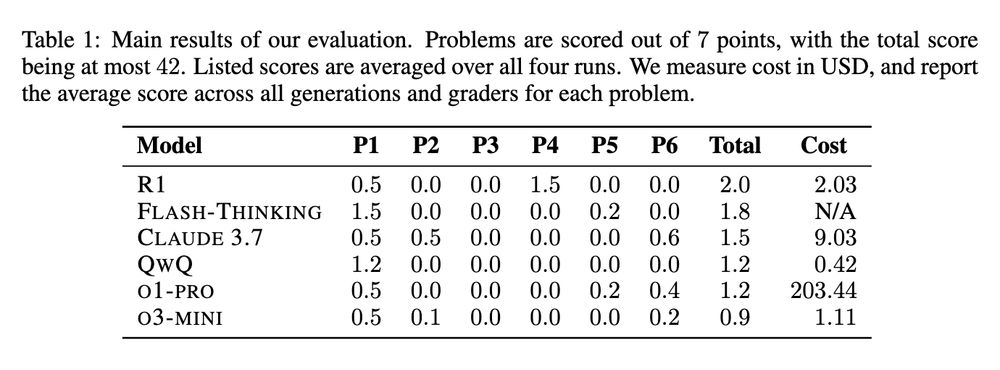
Scores of R1, Flash-thinking, Claude 4.7, QwQ, o1-pro, o3-mini on USAMO 2025. Scores less than 5% of max score.
Tests on USAMO immediately after problems were posted yield surprisingly bad model performance. Suggests there's much more training on test than expected.
arxiv.org/abs/2503.219...
31.03.2025 19:08 — 👍 29 🔁 8 💬 7 📌 0
Just read that AI’s energy consumption in data centers is nothing to be worried about because most of the hyperscale datacenters running AI are "powered by renewable energy or low-carbon nuclear power."
Let's debunk that, shall we?
19.03.2025 19:24 — 👍 30 🔁 12 💬 2 📌 1
New England NLP Meeting Series
If you're in the northeastern US and you're submitting a paper to COLM on March 27, you should absolutely be sending its abstract to New England NLP on March 28.
19.03.2025 19:59 — 👍 8 🔁 3 💬 0 📌 0
+ No system pre-reqs, multi-stage PyTorch workflows in one script, CLI integrations, catching system failures as exceptions, SLURM support, better logging, and so much more!
Additional fine-tuning examples in our docs with:
@pytorch.org, Deepspeed, @lightningai.bsky.social, HF Accelerate
11.03.2025 16:54 — 👍 0 🔁 0 💬 0 📌 0
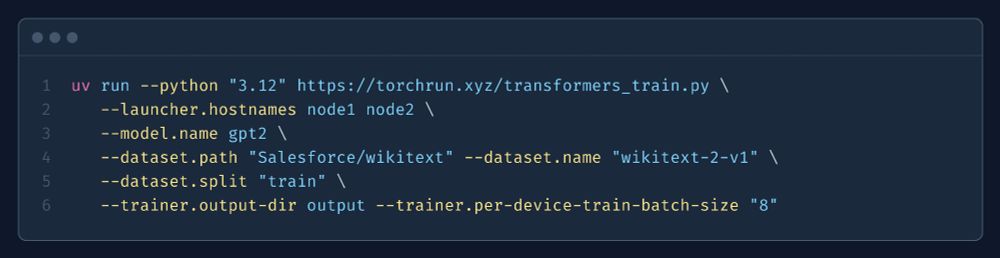
A cool side-effect: fine-tune any LLM (from
@huggingface
transformers) on any text dataset *with multiple nodes* in just *one command*.
torchrun.xyz/examples/tra...
11.03.2025 16:54 — 👍 2 🔁 0 💬 1 📌 0
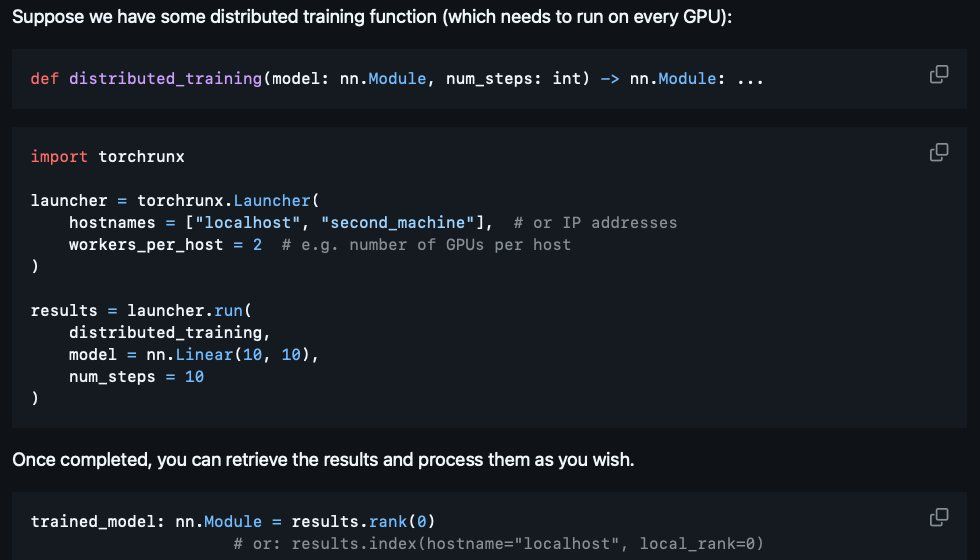
It's a replacement for CLI tools, like "torchrun".
Most basic usage: specify some (SSH-enabled) machines you want to parallelize your code on. Then launch a function onto that configuration.
All from inside your Python script!
11.03.2025 16:54 — 👍 1 🔁 0 💬 1 📌 0
GitHub - apoorvkh/torchrunx: Easily run PyTorch on multiple GPUs & machines
Easily run PyTorch on multiple GPUs & machines. Contribute to apoorvkh/torchrunx development by creating an account on GitHub.
We made a library (torchrunx) to make multi-GPU / multi-node PyTorch easier, more robust, and more modular! 🧵
github.com/apoorvkh/tor...
Docs: torchrun.xyz
`(uv) pip install torchrunx` today!
(w/ the very talented, Peter Curtin, Brown CS '25)
11.03.2025 16:54 — 👍 4 🔁 2 💬 1 📌 0
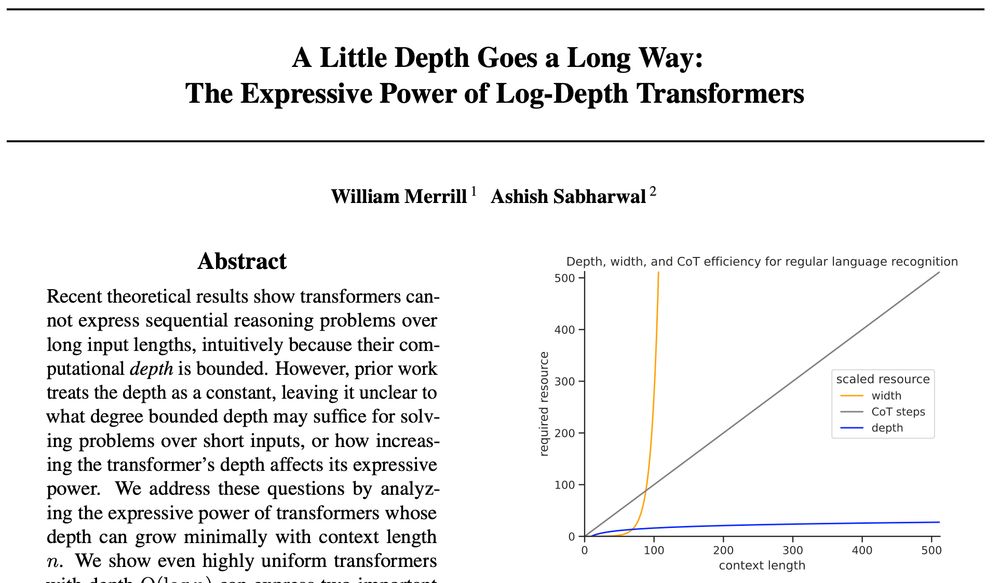
Paper: A Little Depth Goes a Long Way: The Expressive Power of Log-Depth Transformers
✨How does the depth of a transformer affect its reasoning capabilities? New preprint by myself and @Ashish_S_AI shows that a little depth goes a long way to increase transformers’ expressive power
We take this as encouraging for further research on looped transformers!🧵
07.03.2025 16:46 — 👍 12 🔁 2 💬 1 📌 0

(1/9) Excited to share my recent work on "Alignment reduces LM's conceptual diversity" with @tomerullman.bsky.social and @jennhu.bsky.social, to appear at #NAACL2025! 🐟
We want models that match our values...but could this hurt their diversity of thought?
Preprint: arxiv.org/abs/2411.04427
10.02.2025 17:20 — 👍 63 🔁 10 💬 3 📌 4
Managing Project Dependencies
I started a blog! First post is everything I know about setting up (fast, reproducible, error-proof) Python project environments using the latest tools. These methods have saved me a lot of grief. Also a short guide to CUDA in appendix :)
blog.apoorvkh.com/posts/projec...
07.02.2025 15:45 — 👍 3 🔁 0 💬 0 📌 1
I think typing my code and using a linter (ruff) + static type checker (pyright) saves me a lot of grief.
25.01.2025 18:49 — 👍 1 🔁 0 💬 0 📌 0
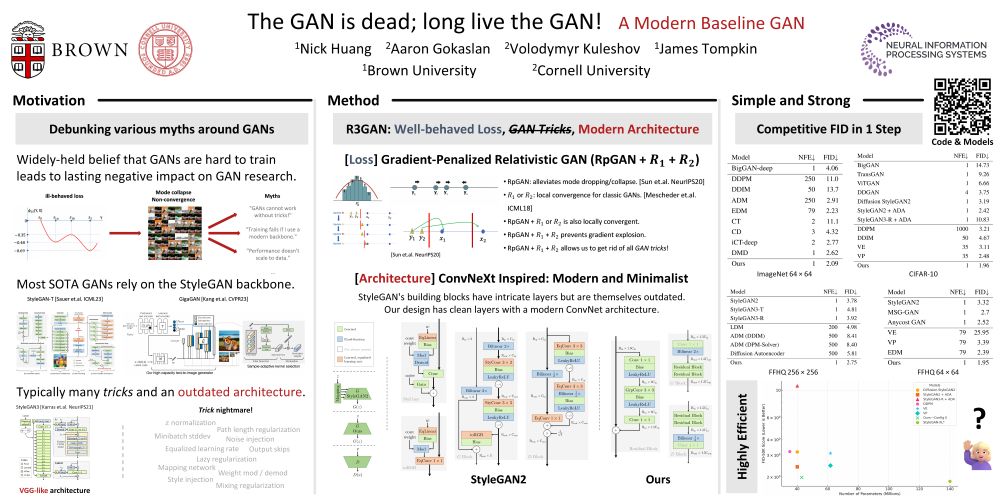
Can GANs compete in 2025? In 'The GAN is dead; long live the GAN! A Modern GAN Baseline', we show that a minimalist GAN w/o any tricks can match the performance of EDM with half the size and one-step generation - github.com/brownvc/r3gan - work of Nick Huang, @skylion.bsky.social, Volodymyr Kuleshov
10.01.2025 19:08 — 👍 69 🔁 14 💬 3 📌 1
Let he who hath not \usepackage[subtle]{savetrees}
18.12.2024 01:27 — 👍 13 🔁 1 💬 1 📌 0
Slides from the tutorial are now posted here!
neurips.cc/media/neurip...
11.12.2024 16:43 — 👍 17 🔁 7 💬 0 📌 0
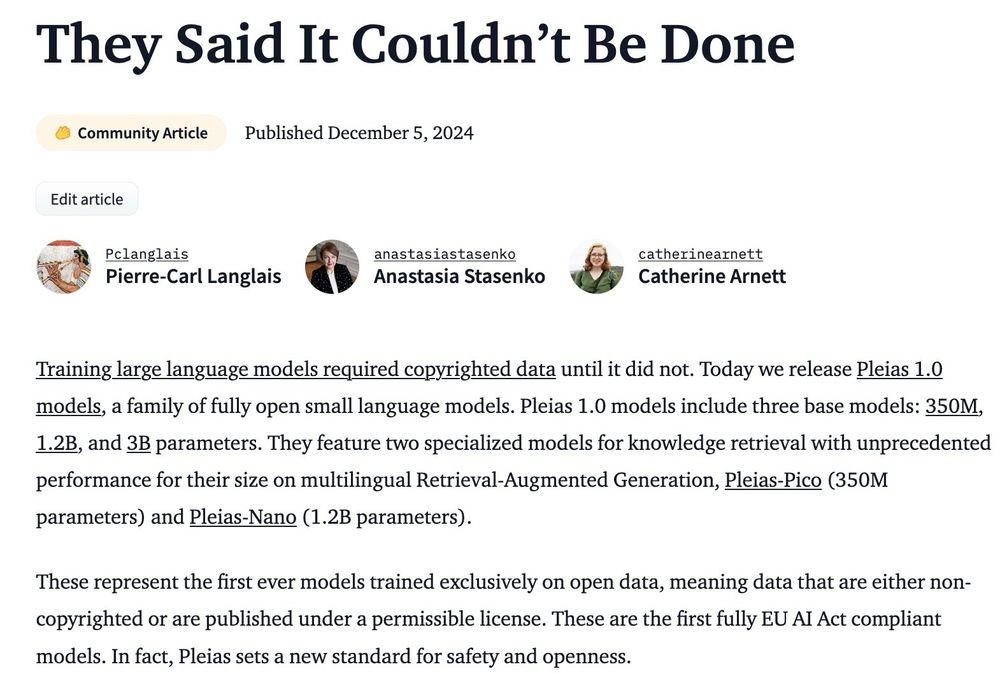
“They said it could not be done”. We’re releasing Pleias 1.0, the first suite of models trained on open data (either permissibly licensed or uncopyrighted): Pleias-3b, Pleias-1b and Pleias-350m, all based on the two trillion tokens set from Common Corpus.
05.12.2024 16:39 — 👍 251 🔁 85 💬 12 📌 19
I am an ex-Paperpile user and am liking Zotero lately! Free storage from the university helps.
27.11.2024 05:15 — 👍 0 🔁 0 💬 0 📌 0
GitHub - benlipkin/decoding: Composable inference algorithms with LLMs and programmable logic
Composable inference algorithms with LLMs and programmable logic - benlipkin/decoding
Lots of folks talking about scaling LLM inference over this last year
Internally, I’ve been developing and using a library that makes this extremely easy, and I decided to open-source it
Meet the decoding library: github.com/benlipkin/de...
1/7
25.11.2024 16:19 — 👍 26 🔁 5 💬 1 📌 0

GitHub - McGill-NLP/llm2vec: Code for 'LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders'
Code for 'LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders' - McGill-NLP/llm2vec
“Turn” a decoder into an encoder with LLM2Vec (github.com/McGill-NLP/l...). Seen at COLM 2024 :)
If you want the naive, training-free / model-agnostic approach: their related work section says it is most common to using the final token’s last hidden state.
26.11.2024 01:37 — 👍 14 🔁 1 💬 0 📌 0
Okay genius idea to improve quality of #nlp #arr reviews. Literally give gold stars to the best reviewers, visible on open review next to your anonymously ID during review process.
Here’s why it would work, and why would you should RT this fab idea:
24.11.2024 21:01 — 👍 27 🔁 5 💬 3 📌 1
Thanks and great! Hope you are likewise doing well!
21.11.2024 21:29 — 👍 1 🔁 0 💬 1 📌 0
Would be great to join, thanks!
21.11.2024 21:15 — 👍 1 🔁 0 💬 1 📌 0
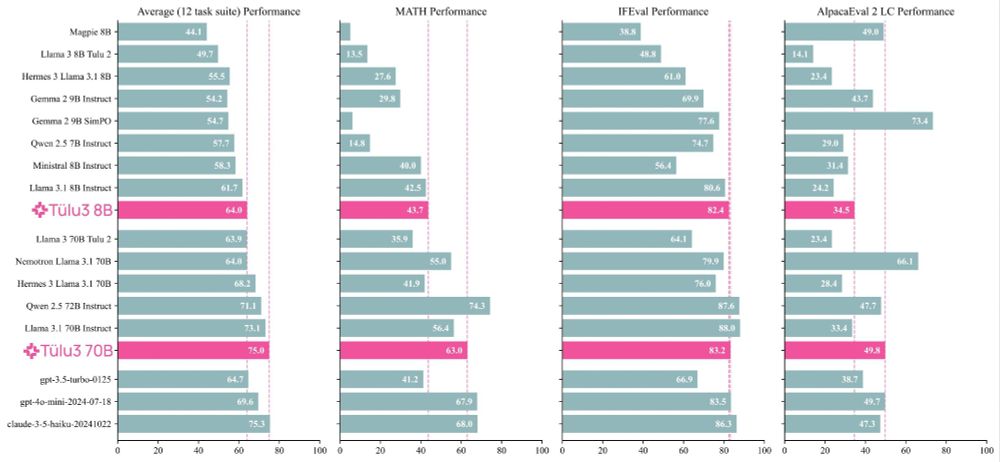
Excited to release Tulu 3! We worked hard to try and make the best open post-training recipe we could, and the results are good!
I was lucky enough to work on almost every stage of the pipeline in one way or another. Some comments + highlights ⬇️
21.11.2024 17:45 — 👍 9 🔁 5 💬 1 📌 0
You can find the “authors’ cut” at: arxiv.org/abs/2410.23261
21.11.2024 16:23 — 👍 1 🔁 0 💬 1 📌 0
"I used to be just like you before I started going to therapy"
Assistant Professor at @cs.ubc.ca and @vectorinstitute.ai working on Natural Language Processing. Book: https://lostinautomatictranslation.com/
CS PhD Candidate at Stanford NeuroAI Lab
The NLP group at the University of Washington.
CS PhD student @ Brown | Multimodal Interpretability
Snowflake AI Research Team, DeepSpeed co-founder, Brown CS PhD, UW CSE alum. @jeffra45 on the other site.
cs phd student and kempner institute graduate fellow at harvard.
interested in language, cognition, and ai
soniamurthy.com
MIT media lab // researching fairness, equity, & pluralistic alignment in LLMs
previously @ mila / mcgill
i like language and dogs and plants and ultimate frisbee and baking and sunsets
https://elinorp-d.github.io
Center for Language and Speech Processing at Johns Hopkins University
#NLProc #MachineLearning #AI http://tinyurl.com/clspy2ube
associate prof at UMD CS researching NLP & LLMs
Professor a NYU; Chief AI Scientist at Meta.
Researcher in AI, Machine Learning, Robotics, etc.
ACM Turing Award Laureate.
http://yann.lecun.com
Studying language in biological brains and artificial ones @MIT.
www.tuckute.com
Human Centered AI, AI for Accessibility 👥🦾
Postdoc at UT Austin ISchool, previously a PhD at UMD CLIP
she/her
The National Deep Inference Fabric, an NSF-funded computational infrastructure to enable research on large-scale Artificial Intelligence.
🔗 NDIF: https://ndif.us
🧰 NNsight API: https://nnsight.net
😸 GitHub: https://github.com/ndif-team/nnsight
@_angie_chen at the other place
PhD student @NYU, formerly at
@Princeton 🐅
Interested in LLMs/NLP, pastries, and running. She/her.
Professor of Computer Science at UT Austin and Visiting Researcher at Google Deepmind, London. Automated Reasoning + Machine Learning + Formal Methods. https://www.cs.utexas.edu/~swarat
PhD student at Brown University working on interpretability. Prev. at Ai2, Google
 28.07.2025 05:13 — 👍 0 🔁 0 💬 0 📌 0
28.07.2025 05:13 — 👍 0 🔁 0 💬 0 📌 0






















