
#VISxAI IS BACK!! 🤖📊
Submit your interactive “explainables” and “explorables” that visualize, interpret, and explain AI. #IEEEVIS
📆 Deadline: July 30, 2025
visxai.io

@angieboggust.bsky.social
MIT PhD candidate in the VIS group working on interpretability and human-AI alignment
#VISxAI IS BACK!! 🤖📊
Submit your interactive “explainables” and “explorables” that visualize, interpret, and explain AI. #IEEEVIS
📆 Deadline: July 30, 2025
visxai.io
I’ll be at #CHI2025 🌸
If you are excited about interpretability and human-AI alignment — let’s chat!
And come see Abstraction Alignment ⬇️ in the Explainable AI paper session on Monday at 4:20 JST

Check out Abstraction Alignment at #CHI2025!
📄Paper: arxiv.org/abs/2407.12543
💻Demo: vis.mit.edu/abstraction-...
🎥Video: www.youtube.com/watch?v=cLi9...
🔗Project: vis.mit.edu/pubs/abstrac...
With Hyemin (Helen) Bang, @henstr.bsky.social, and @arvind.bsky.social
Abstraction Alignment reframes alignment around conceptual relationships, not just concepts.
It helps us audit models, datasets, and even human knowledge.
I'm excited to explore ways to 🏗 extract abstractions from models and 👥 align them to individual users' perspectives.
Abstraction Alignment works on datasets too!
Medical experts analyzed clinical dataset abstractions, uncovering issues like overuse of unspecified diagnoses.
This mirrors real-world updates to medical abstractions — showing how models can help us rethink human knowledge.
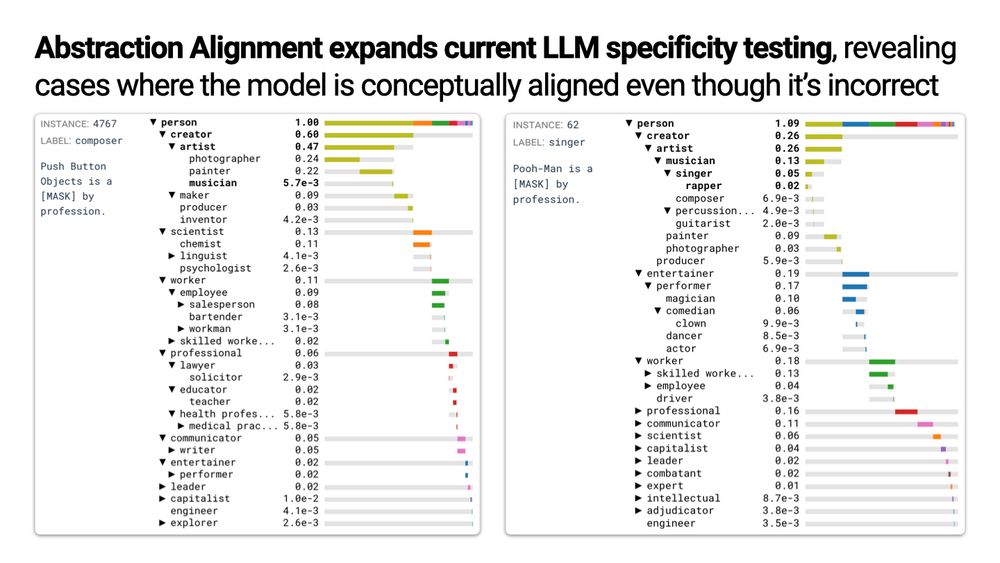
Two examples of Abstraction Alignment applied to a language model.
Language models often prefer specific answers even at the cost of performance.
But Abstraction Alignment reveals that the concepts an LM considers are often abstraction-aligned, even when it’s wrong.
This helps separate surface-level errors from deeper conceptual misalignment.
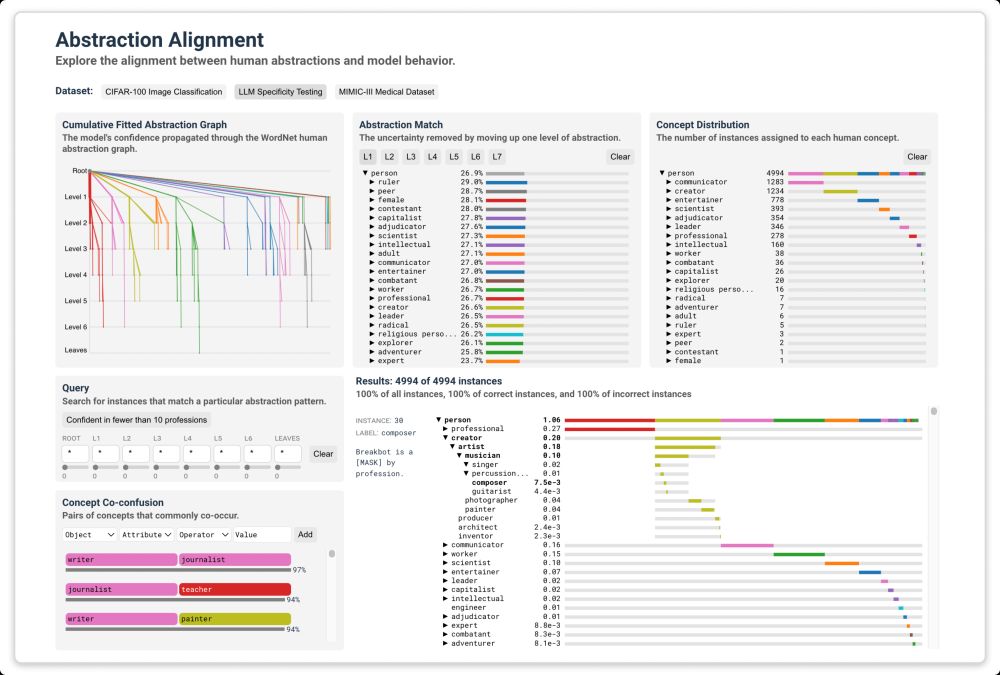
A screenshot of the Abstraction Alignment interface.
And we packaged Abstraction Alignment and its metrics into an interactive interface so YOU can explore it!
🔗https://vis.mit.edu/abstraction-alignment/
Aggregating Abstraction Alignment helps us understand a model’s global behavior.
We developed metrics to support this:
↔️ Abstraction match – most aligned concepts
💡 Concept co-confusion – frequently confused concepts
🗺️ Subgraph preference – preference for abstraction levels
Abstraction Alignment compares model behavior to human abstractions.
By propagating the model's uncertainty through an abstraction graph, we can see how well it aligns with human knowledge.
E.g., confusing oaks🌳 with palms🌴 is more aligned than confusing oaks🌳 with sharks🦈.
Interpretability identifies models' learned concepts (wheels 🛞).
But human reasoning is built on abstractions — relationships between concepts that help us generalize (wheels 🛞→ car 🚗).
To measure alignment, we must test if models learn human-like concepts AND abstractions.

An overview of Abstraction Alignment, including its authors and links to the paper, demo, and code.
#CHI2025 paper on human–AI alignment!🧵
Models can learn the right concepts but still be wrong in how they relate them.
✨Abstraction Alignment✨evaluates whether models learn human-aligned conceptual relationships.
It reveals misalignments in LLMs💬 and medical datasets🏥.
🔗 arxiv.org/abs/2407.12543
Hey Julian — thank you so much for putting this together! My research is on interpretability and I’d love to be added.
24.11.2024 14:21 — 👍 6 🔁 0 💬 1 📌 0



















