Graf has been belligerent with his own community for nearly as long as GZDoom has existed. This is 20 years of beef reaching a boiling point.
16.10.2025 14:49 — 👍 1 🔁 0 💬 0 📌 0
YouTube video by 東儀秀樹 togi hideki
stairway to heaven by gagaku 雅楽で「天国への階段」covered with Japanese traditional instruments.
youtu.be/RnxI0mgAqgY
03.10.2025 13:02 — 👍 1 🔁 0 💬 0 📌 0
 01.10.2025 19:33 — 👍 54 🔁 16 💬 1 📌 1
01.10.2025 19:33 — 👍 54 🔁 16 💬 1 📌 1
YouTube video by xsonicsd
(High Quality) SpaceBalls (vocal by The Spinners)
youtu.be/hekqzcveud4
If you're living in a bubble and you haven't got a care
Then you're gonna be in trouble cause we're gonna steal your air
Cause what you've got is what we need
And all we do is dirty deeds
We're the SPACEBALLS!
01.10.2025 20:09 — 👍 1 🔁 0 💬 0 📌 0
YouTube video by яша
Beat It but every note is С
youtu.be/OlbmRGvLExY
01.10.2025 17:42 — 👍 1 🔁 0 💬 0 📌 0
19.09.2025 14:17 — 👍 4634 🔁 2236 💬 15 📌 6
Not exactly. Morrowind had a workaround. It checks how much RAM is being used in a loading screen and if it detected too much RAM was being used it soft rebooted the Xbox while pretending it was a very long loading screen you coincidentally couldn't use the Xbox button during.
18.09.2025 00:13 — 👍 2 🔁 0 💬 0 📌 0
YouTube video by JAM Project Official Channel
[Official Music Video]JAM Project「Bloodlines~運命の血統~」
youtu.be/FLlB-Pel_b0
11.09.2025 20:00 — 👍 1 🔁 0 💬 0 📌 0

A randomly generated meme
11.09.2025 14:30 — 👍 23 🔁 6 💬 0 📌 0

Generative AI does not fit the classic software pricing model
One of the classic booster arguments is that we're in the "growth stage" of generative AI, where companies "charge a lower price to get people through the door" before cranking up prices, the so-called "profit-lever" that every lazy journalist claims exist for any product economics they don't want to think about too hard.
The problem, I'm afraid, is that generative AI does not match the traditional pricing model for software, which is predominantly sold at a monthly flat price per month.
In traditional software, a "user" generally doesn't cost the developer that much money. One of the big benefits of selling software at scale is that the costs don't scale with you. A web-based application may have an associated cost, but they run on significantly cheaper and widely-available servers, with operations run across less-demanding CPUs, beefier versions of the ones you'd find in your laptop or desktop computer.
Let me get specific. Microsoft Office 365 — one of Microsoft's most profitable business units — for the most part uses CPU-based architectures for its compute, as a Word user, even using Microsoft's cloud-based apps, doesn't require a massive amount of power, because they’re effectively running cloud-based versions of consumer apps. The same goes for things like Google Workspace. Google makes billions of dollars selling access to software that effectively prints money, because the infrastructural burden is mostly "can I make sure this service is available all the time" rather than "do I have the specialized hardware to do so." Its costs — even with power users — are relatively standardized.

Large Language Models are an entirely different beast for several reasons, chief of which are that very few models actually exist on a single GPU, with instances "sharded" across multiple GPUs (such as eight H100s).
Large Language Models require NVIDIA GPUs, meaning that any infrastructure provider must build specialized servers full of them to provide access to said model reliably regardless of a user's location.
A Large Language Model user's infrastructural burden varies wildly between users and use cases. While somebody asking ChatGPT to summarize an email might not be much of a burden, somebody asking ChatGPT to review hundreds of pages of documents at once — a core feature of basically any $20-a-month subscription — could eat up eight GPUs at once.
To be very clear, a user that pays $20-a-month could run multiple queries like this a month, and there's no real way to stop them.
Unlike most software products, any errors in producing an output from a Large Language Model have a significant opportunity cost. When a user doesn't like an output, or the model gets something wrong, or the user realizes they forgot something, the model must make further generations, and even with caching (which Anthropic has added a toll to), there's a definitive cost attached to any mistake.
Large Language Models, for the most part, lack definitive use cases, meaning that every user is (even with an idea of what they want to do) experimenting with every input and output. In doing so, they create the opportunity to burn more tokens, which in turn creates an infrastructural burn on GPUs, which cost a lot of money to run.
The more specific the output, the more opportunities there are for monstrous token burn, and I'm specifically thinking about coding with Large Language Models. The token-heavy nature of generating code means that any mistakes, suboptimal generations or straight-up errors will guarantee further token burn.
Take a look at r/Cursor or a…

This is the core problem of "hallucinations" within any Large Language Model. While many (correctly) dislike LLMs for their propensity to authoritatively state things that aren't true, the real hallucination problem is models subtly misunderstanding what a user wants, then subtly misunderstanding how to do it. As the complexity of a request increases, so too do the opportunities for these subtle mistakes, a problem that only compounds with the use of the reasoning models that are a requirement to make any coding LLM function (as they hallucinate more).
Every little "mistake" creates the opportunity for errors, which in turn creates the opportunity for the model to waste tokens generating something the user doesn't want or that will require the user to prompt the model again. And because LLMs do not have "thoughts" and are not capable of learning, there is no way for them to catch these errors.
In simpler terms, it's impossible to guarantee that a model will do anything specific, and any failure of a model to provide exactly what a user wants all but guarantees the user will ask the model to burn more tokens.
While this might be something you can mitigate when charging users based on their actual token consumption, most generative AI companies are charging users by the month, and the majority of OpenAI's revenue comes from selling monthly subscriptions. While one can rate limit a user, these limits are hard to establish in a way that actually mitigates how much a user can burn.
At the heart of gen AI sits a massive economic problem: LLMs are too expensive to charge a monthly fee for, and that is what every single LLM company charges. This will never work.
www.wheresyoured.at/why-everybody-is-losing-money-on-ai/#what-if-it-isnt-possible-to-make-a-profitable-ai-company
05.09.2025 16:56 — 👍 213 🔁 32 💬 8 📌 7
Unlike rocket league its fun
05.09.2025 20:15 — 👍 0 🔁 0 💬 0 📌 0
Probably because people remember Krakoa as the leftovers of weird directives to remove the X Men from the actual goings on back in the Inhumans period, or as the map from Marvel Rivals
02.09.2025 00:29 — 👍 0 🔁 0 💬 1 📌 0
Because paying artists was never the only reason the games were costly to make
25.08.2025 12:02 — 👍 0 🔁 0 💬 1 📌 0
people say bluesky only talks about politics, but that’s not quite right. the issue is that even if they talk about other stuff sometimes, everyone here is political. there are no median voters, no normies, nobody who doesn’t know who the speaker of the house is.
23.08.2025 17:13 — 👍 1584 🔁 113 💬 87 📌 67
For me, it's that no one here is funny
Social media, like it or not, is entertainment for a lot of people, and the old site was funny and interesting and this site is not
24.08.2025 21:13 — 👍 5 🔁 1 💬 4 📌 3

An image of the "Sparkle on! It's Wednesday! Don't forget to be yourself!" meme with an image of Deryk from Final Fantasy 14
HAPPY WEEK 137 AND HAPPY DERYK WEDNESDAY
20.08.2025 18:33 — 👍 4 🔁 1 💬 0 📌 0

A product image for the Ultimate FINAL FANTASY XIV Cookbook, Vol. 2 Gift Set. Text reads Pre-order Now. In the background is a box enclosing the Cookbook and stand. In front of the box is the Final Fantasy 14 Cookbook sitting on a stand with a Namazu design.
Pre-orders for The Ultimate FFXIV Cookbook, Vol. 2 are ongoing! 🌮
Plus, we have a special gift set that includes a splendorous cookbook stand-perfect for aspiring culinarians alike!
Learn more 🎁 sqex.to/eVAbC
15.08.2025 15:02 — 👍 386 🔁 128 💬 6 📌 23
The fact that he gets it and is fine doing it but Waffle House doesn't want to reply to him is so funny
04.08.2025 18:41 — 👍 0 🔁 0 💬 0 📌 0
kill him
01.08.2025 17:35 — 👍 0 🔁 0 💬 0 📌 0

#Battlefield6 will avoid crossover skins
“I don’t think it needs Nicki Minaj. Let’s keep it real, keep it grounded"
(via DBLTAP)
01.08.2025 14:43 — 👍 295 🔁 21 💬 16 📌 24
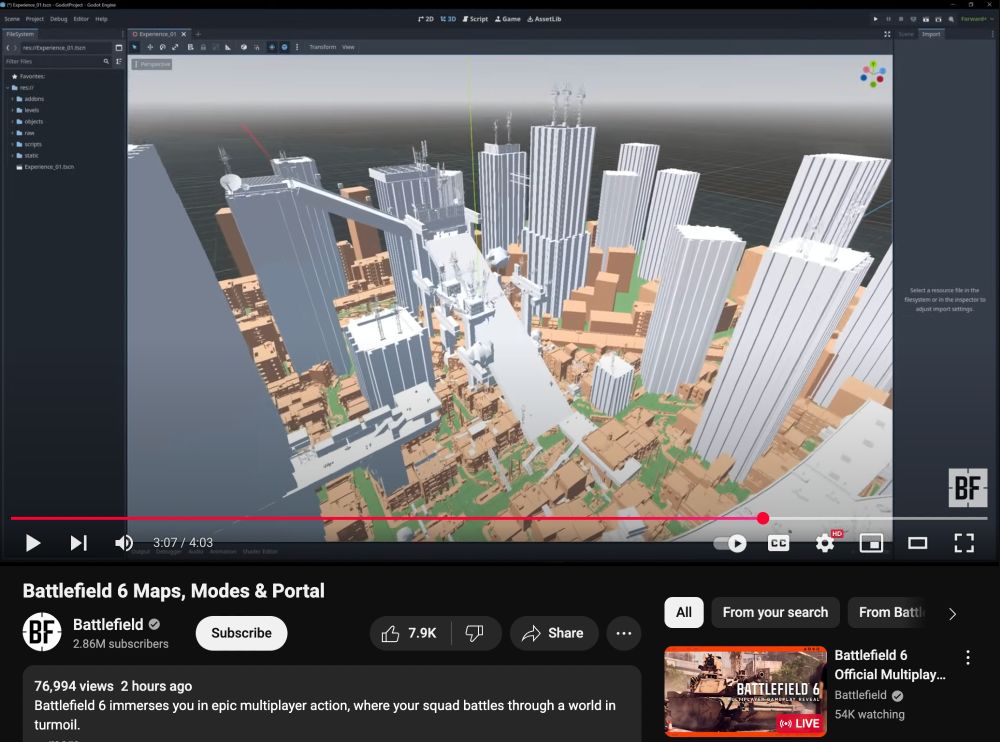
battlefield 6 map editor is... *checks notes*... godot
31.07.2025 20:58 — 👍 816 🔁 130 💬 25 📌 38
I thought I saw this being handled by one of izica's mods but I guess not.
What a pickle. Finding the right way to express info in the shell and the game is such a challenge lol
01.08.2025 14:07 — 👍 0 🔁 0 💬 0 📌 0
I want to have hope but I am fearful
31.07.2025 18:40 — 👍 0 🔁 0 💬 1 📌 0
(Yes, I know there are many technical ways to do it! I use a URL forwarder and udm14.com This is just a lot funnier)
31.07.2025 13:52 — 👍 109 🔁 2 💬 2 📌 0
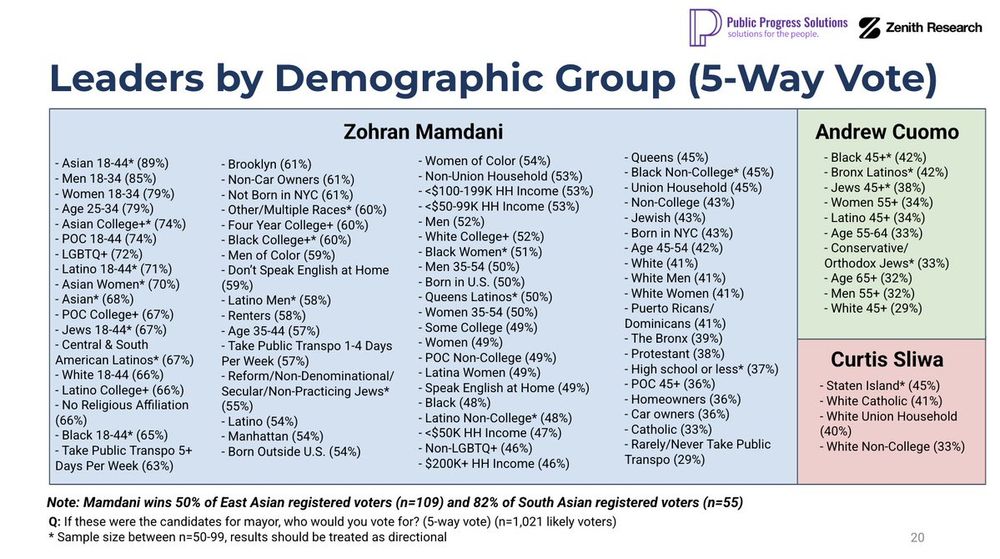
Public Progress Solutions and Zenith Research polling breakdown between Zohran Mamdani, Curtis Sliwa, Eric Adams, Jim Walden, and Andrew Cuomo
85% of young men support Zohran Mamdani.
79% of young women support Zohran Mamdani.
67% of Jewish people aged 18-44 support Zohran Mamdani.
65% of Black people aged 18-44 support Zohran Mamdani.
Would you have guessed *any* of that with how the media has covered all this?
29.07.2025 19:14 — 👍 7901 🔁 2065 💬 145 📌 187
formerly known as thefacebook
Newgrounds is the greatest community of artists, game developers, musicians, voice actors and writers on the web! Banner by PKettles on Newgrounds! Come check out Newgrounds!
The official YMS bluesky account. any/all
youtube.com/@YMS
t.me/YMSTelegram
twitch.tv/YMSPlays
anUnkindness.com
It’s PAYDAY! Buy #PAYDAY3 & #PAYDAY2
Rob banks on PC/VR/PS/Xbox 💰
ESRB: Mature, Blood, Drug Reference, Intense Violence, Strong Language.
http://pd3.link/tree
DC Studios co-CEO, #Superman, #GuardiansoftheGalaxy, #Peacemaker, dog owner, husband, servant to my cat.
get your daily dose of funny, cringe, stupid all in once place
follow me for 69 years of good luck
by following you relinquish your rights to a clean feed
Independent gaming news powered by Walmart
Visit us at https://www.restart.run/
Paste Games is now Endless Mode
https://www.endlessmode.com/
like the irl card game but not irl
I wanna show you why fighting games are cool. Podcasts & Let's Plays: http://linktr.ee/wooliewoolz
YouTube.com/@woolieversus
Clips: http://YouTube.com/@woolievsthealgorithm
"He believed that he must, that he could and would recover the good things, the happy things, the easy tranquil things of life. He had made mistakes, but he could overlook these. He had been a fool, but that could be forgiven….Recovery was possible.”
Not affiliated with the SiIvaGunner team. Posts a high quality video game rip roughly once per day.
Open indie game marketplace and DIY game jam host
Account support? Email support@itch.io
❗📢 You can use your itchio URL as your Bluesky username, check here: https://itch.io/user/settings/bluesky
Steam, The Ultimate Online Game Platform.
For support: http://help.steampowered.com/en/
★ i make silly video game comics
★ @ghmofficial.bsky.social community deputy
★ she/her ★ 日本語大体OK
★ twitch partner: http://twitch.tv/othatsraspberry
★ comics: othatsraspberry.com
★ patreon: patreon.com/othatsraspberry
Cataloguing all the secret stars that "gamers" MISSED in the nintendo 64 classic!
RIVALS OF AETHER II is the next generation of platform fighters and launches OCTOBER 23 on Steam! linktr.ee/studiosofaether
automated shitposting bot, more info at https://www.shitpostbot.com/
ran by @botmin.shitpostbot.com






![[Official Music Video]JAM Project「Bloodlines~運命の血統~」](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:lputcykg3ghjgw3ga2r5p2hc/bafkreiblglcnnqd3ff7siakznnh2ytlgl2gzbyztj5mh3mr6cgxlaif2e4@jpeg)





















