Recruitment
I'm hiring again! 2 postdoc positions (3-years). Australian citizenship required.
Join my lab to research scalable human-centred AI for decision support in defence, balancing scalable decision support and human control in complex environments.
Details: uqtmiller.github.io/recruitment/
28.11.2025 07:14 — 👍 0 🔁 4 💬 1 📌 1
Visiting San Diego, I can say with confidence that the rest of the world is not up to real taco standards. That thing here rocks
01.12.2025 04:57 — 👍 1 🔁 0 💬 0 📌 0
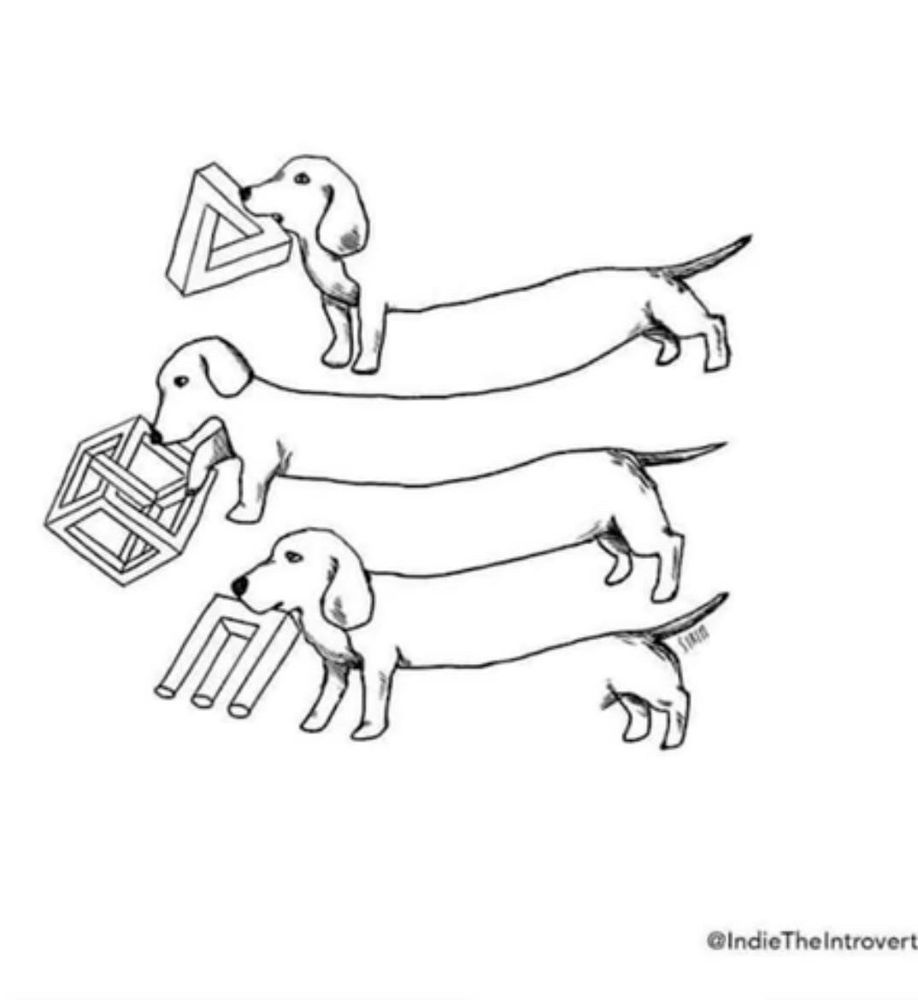
A black and white drawing of three dachshunds arranged vertically, each holding a different optical illusion object in its mouth, and the dogs themselves drawn as if a single line optical illusion. The top dog holds a Penrose triangle, the middle dog holds a Necker cube, and the bottom dog holds a Penrose trident. The dogs’ bodies are elongated in an exaggerated cartoon style. The artwork is signed “@IndieTheIntrovert” in the bottom right corner.
Everyone stop, this is important
07.07.2025 00:31 — 👍 5215 🔁 1615 💬 94 📌 81
Mathematical Understanding and Artificial Intelligence | Bálint Gyevnár
Thoughts and notes from the workshop on the Cognitive Science of Mathematical Understanding
What does it mean when we say we understand mathematics and how will AI change all that?
I recently attended the workshop on the Cognitive Science of Mathematical Understanding organized by Tania Lombrozo and
Akshay Venkatesh, and summarized my experiences on my blog: gbalint.me/blog/2025/ma...
23.11.2025 05:05 — 👍 0 🔁 0 💬 0 📌 0
And now the propaganda rag "Magyar Nemzet" (along with other pro-Orban media) shared - then removed - a map containing the personal data, including the address, of the opposition supporters and activists whose data was stolen. Clear and brazen intimidation tactics.
444.hu/2025/11/07/n...
08.11.2025 02:01 — 👍 19 🔁 13 💬 1 📌 1

GitHub - hadley/genzplyr: dplyr but make it bussin fr fr no cap
dplyr but make it bussin fr fr no cap. Contribute to hadley/genzplyr development by creating an account on GitHub.
Do you teach #rstats? Do your students complain about how lame and old-fashioned dplyr is? Don't worry: I have the solution for you: github.com/hadley/genzp....
genzplyr is dplyr, but bussin fr fr no cap.
06.11.2025 23:25 — 👍 462 🔁 167 💬 42 📌 55
YouTube video by Jay and Mark
Why British cities make no sense
Yeah that is true, although it hasn’t been the case more recently afaik: youtu.be/Whqs8v1svyo?...
27.10.2025 20:59 — 👍 1 🔁 0 💬 0 📌 0
Oh just wait until you see what they call cities in England: en.wikipedia.org/wiki/List_of...
27.10.2025 19:01 — 👍 0 🔁 0 💬 1 📌 0

Pittsburgh left - Wikipedia
Cycling in Pittsburgh is great: the city is beautiful in the autumn colours, I never need to do cardio training again, and one may experience the "Pittsburgh left" which is when oncoming cars cut ahead of you at an unprotected left turn.
en.wikipedia.org/wiki/Pittsbu...
26.10.2025 17:09 — 👍 0 🔁 0 💬 0 📌 0
Oh my god some fucking tech dingdong posted this on Twitter with the caption "AI games are going to be amazing" totally seriously, you have to watch it. You have to. In full screen.
24.10.2025 15:02 — 👍 9515 🔁 2146 💬 1379 📌 2689
yoda-conditions (SIM300) | Ruff
Checks for conditions that position a constant on the left-hand side of the
TIL that the expression: constant == expression, is called a Yoda condition and it makes so much sense.
docs.astral.sh/ruff/rules/y...
23.10.2025 22:19 — 👍 0 🔁 0 💬 0 📌 0
I just saw a recent @nature.com paper that designs parachutes by literally cutting hundreds of holes into a disc.
Inspired by kirigami, which is like origami but instead of folds you make cuts, if you cut a disc the right way, then you might just be able to jump out of a plane and survive.
21.10.2025 20:10 — 👍 0 🔁 0 💬 1 📌 0

Mountains peeking above the clouds in Northwest Scotland
Throw back to a cloud inversion on Beinn Eighe a year ago. If you have the chance, explore the Scottish Highlands!
14.10.2025 15:27 — 👍 1 🔁 0 💬 0 📌 0

Photo of the first question of the recent national consultation in Hungary.
The Hungarian government often mails people “National Consultations” paid for by taxpayers, asking violently condescending questions:
“Do you wanna raise taxes?”
A: “Yes, I like paying more to fund those who don’t work.”
B: “No.”
Then they use the results to fake support for their agenda…
12.10.2025 16:48 — 👍 0 🔁 0 💬 0 📌 0
Cartography of generative AI
Just came across this mesmerising art by Estampa of the components of GenAI interacting with humanity: cartography-of-generative-ai.net
Reminds me a little of Kate Crawford and Vladan Joler's Anatomy of an AI System: anatomyof.ai
11.10.2025 18:29 — 👍 0 🔁 0 💬 0 📌 0

Our CDT is based in the Edinburgh Futures Institute – the University of Edinburgh’s brand new hub for research, innovation and teaching focused on socially just artificial intelligence and data.
Please share!
We have a number of fully funded PhD studentships in "Designing Responsible Natural Language Processing". I'm a possible supervisor & I'd be keen to support projects on sociolinguistics-AI, e.g., accent bias in AI, language+gender/sexuality+AI.
www.responsiblenlp.org
10.10.2025 15:03 — 👍 20 🔁 22 💬 0 📌 0
Ironically, the “AI scientist”-written paper that was accepted to an ICLR workshop was about LSTMs and the paper didn’t cite Schmidhuber. AI scientists should have a Schmidhuber agent that verifies these important details in the future.
07.10.2025 21:23 — 👍 0 🔁 0 💬 0 📌 0

Never ask a man his age, a woman her salary, or GPT-5 whether a seahorse emoji exists
06.09.2025 13:08 — 👍 2106 🔁 423 💬 95 📌 79

A Teen Was Suicidal. ChatGPT Was the Friend He Confided In.
Adam Raine, 16, died from suicide in April after months on ChatGPT discussing plans to end his life. His parents have filed the first known case against OpenAI for wrongful death.
Overwhelming at times to work on this story, but here it is. My latest on AI chatbots: www.nytimes.com/2025/08/26/t...
26.08.2025 13:01 — 👍 4656 🔁 1728 💬 110 📌 571
"I have wait a long time for this moment, my little red friend." - Emperor Palpatine, probably
25.08.2025 12:10 — 👍 2 🔁 0 💬 1 📌 0

The Art of Fauna: Cozy Puzzles
Discover the wonders of nature with this cozy puzzle game. Download Now!
Having been playing The Art of Fauna while procrastinating, and it is the most relaxing game with beautiful illustrations of animals. I cannot recommend it enough: theartof.app/fauna/
25.08.2025 12:06 — 👍 3 🔁 0 💬 0 📌 0
For a week, we visited @iyadrahwan.bsky.social's Center for Humans and Machines in Berlin, where we have met an incredible array of interdisciplinary researchers.
Special thanks to @neeleengelmann.bsky.social for hosting us and @alice-ross.bsky.social for organising the trip from the start!
16.08.2025 20:24 — 👍 5 🔁 0 💬 0 📌 0
Have been neglecting Bluesky recently, so I am happy to share a big update 🎉
I will join @cmu.edu as a postdoc in September working with the incomparable @atoosakz.bsky.social and Nihar Shah on understanding risks from LLM co-scientists. If you are in Pittsburgh, I would love to connect!
16.08.2025 20:12 — 👍 6 🔁 0 💬 1 📌 0
Cognitive scientist studying how we see + think @ Johns Hopkins University. 🇨🇦
Lab: https://perception.jhu.edu/
野鳥や風景の写真、独り言などなど…
拙い写真ばかりですがよろしくお願いします。
Data & Society is a nonprofit research institute that studies the social implications of data-centric technologies, automation, and AI.
We bring together the outstanding departments, faculties and schools that make up the University of Oxford's Social Sciences Division.
Associate Professor, Dept of Psychology, UC Berkeley.
PI of @shenhavlab.bsky.social
https://www.shenhavlab.org/
incoming asst professor @ucberkeley psych | cognitive scientist studying mechanisms of discovery @ santa fe institute
mdubova.com
🐾Carnegie Bosch Postdoc @ Carnegie Mellon HCII
🤖Mutual Theory of Mind, Human-AI Interaction, Responsible AI.
👩🏻🎓Ph.D. from 🐝Georgia Tech HCC. Prev Google Research, IBM Research, UW-Seattle. She/Her.
🔗 http://qiaosiwang.me/
Trinity College Dublin’s Artificial Intelligence Accountability Lab (https://aial.ie/) is founded & led by Dr Abeba Birhane. The lab studies AI technologies & their downstream societal impact with the aim of fostering a greater ecology of AI accountability
Explainable AI research from the machine learning group of Prof. Klaus-Robert Müller at @tuberlin.bsky.social & @bifold.berlin
The premier research center for #ComplexSystems #science.
santafe.edu
linktr.ee/sfiscience
researching AI [evaluation, governance, accountability]
Associate Professor in Psychology at Columbia, PI of https://www.dpmlab.org/
To computer scientists Dagstuhl has a special ring: a place to hide away for intensive seminars. The center facilitates research also by its bibliography database dblp and its open access publishing.
Visit https://www.dagstuhl.de to learn more.
AI is not inevitable. We DAIR to imagine, build & use AI deliberately.
Website: http://dair-institute.org
Mastodon: @DAIR@dair-community.social
LinkedIn: https://www.linkedin.com/company/dair-institute/
Rad veep at codebase, chief non technical officer at newstacks.co.
📍Edinburgh
Tech Journalist
Interested in Tech and Human Rights
Professor of philosophy UTAustin. Philosophical logic, formal epistemology, philosophy of language, Wang Yangming.
www.harveylederman.com