Excited to share that our work on interpretable risk prediction will be at the #NAACL2024 main conference!
17.03.2024 12:41 — 👍 0 🔁 0 💬 0 📌 0

To train our model, we extract future targets using the LLM and validate that these are reliable, signaling that future work on creating labels with LLM-enabled data augmentation is warranted. (6/6)
28.02.2024 18:56 — 👍 0 🔁 0 💬 0 📌 0
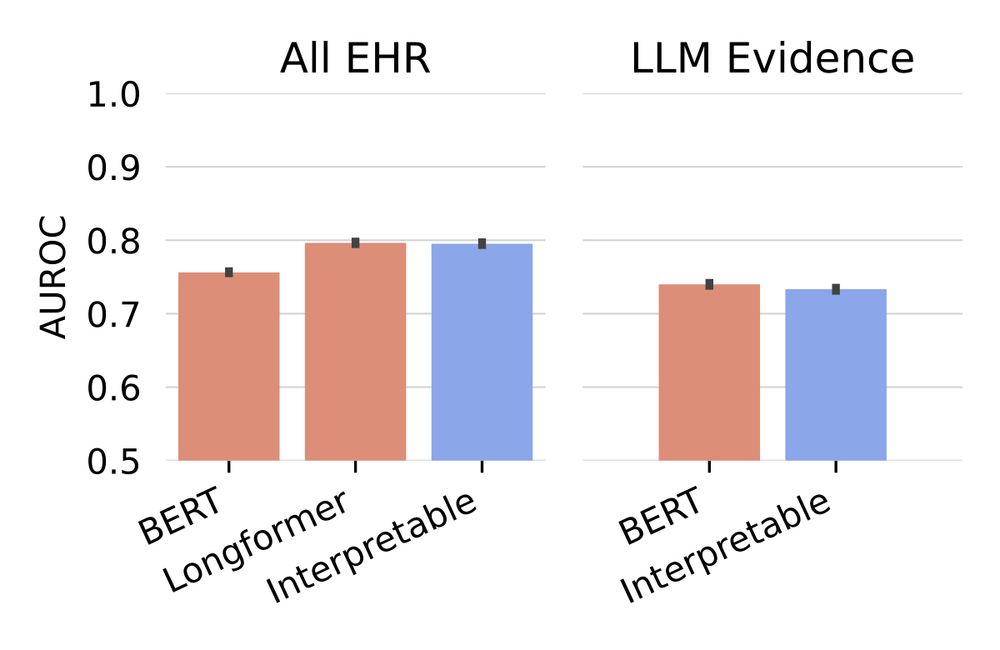
…and achieve reasonable accuracy. In fact, we find that our use of the interpretable Neural Additive Model, which allows us to get individual evidence scores, does not decrease performance at all compared to a blackbox approach. (5/6)
28.02.2024 18:55 — 👍 0 🔁 0 💬 1 📌 0

We also find that the predictions (both per-evidence and aggregated) are intuitive to the clinicians… (4/6)
28.02.2024 18:55 — 👍 0 🔁 0 💬 1 📌 0

Our approach does retrieve useful evidence, and both extracting evidence with an LLM and sorting it via our ranking function are crucial to the model’s success. (3/6)
28.02.2024 18:54 — 👍 0 🔁 0 💬 1 📌 0

Our interface allows a clinician to supplement their review of a patient’s record with our model’s risk predictions and surfaced evidence and then annotate the usefulness of that evidence for actually understanding the patient. (2/6)
28.02.2024 18:53 — 👍 0 🔁 0 💬 1 📌 0

Our work on reducing diagnostic errors with interpretable risk prediction is now on arXiv!
We retrieve evidence from a patient’s record, visualize how it informs a prediction, and test it in a realistic setting. 👇 (1/6)
arxiv.org/abs/2402.10109
w/ @byron.bsky.social and @jwvdm.bsky.social
28.02.2024 18:52 — 👍 2 🔁 1 💬 1 📌 1

we find it makes efficient use of features. (6/6)
25.10.2023 14:21 — 👍 0 🔁 0 💬 0 📌 0

This method also shows promise in being data-efficient, and... (5/6)
25.10.2023 14:21 — 👍 0 🔁 0 💬 0 📌 0

Inspection of individual instances with this approach yields insights as to what went right and what went wrong. (4/6)
25.10.2023 14:20 — 👍 0 🔁 0 💬 0 📌 0

We find that most of the coefficients of the linear model align with clinical expectations for the corresponding feature! (3/6)
25.10.2023 14:19 — 👍 0 🔁 0 💬 0 📌 0

Not only do we see decent accuracy at feature extraction itself, but we also see reasonable performance on the downstream tasks in comparison with using ground truth features. (2/6)
25.10.2023 14:18 — 👍 0 🔁 0 💬 0 📌 0

Very excited our “CHiLL” paper was accepted to #EMNLP2023 Findings!
Can we craft arbitrary high-level features without training?👇(1/6)
We ask a doctor to ask questions to an LLM and train an interpretable model on the answers.
arxiv.org/abs/2302.12343
w/ @jwvdm.bsky.social and @byron.bsky.social
25.10.2023 14:18 — 👍 2 🔁 0 💬 5 📌 1
Breakthrough AI to solve the world's biggest problems.
› Join us: http://allenai.org/careers
› Get our newsletter: https://share.hsforms.com/1uJkWs5aDRHWhiky3aHooIg3ioxm
Researcher trying to shape AI towards positive outcomes. ML & Ethics +birds. Generally trying to do the right thing. TIME 100 | TED speaker | Senate testimony provider | Navigating public life as a recluse.
Former: Google, Microsoft; Current: Hugging Face
Abolish the value function!
Research Director, Founding Faculty, Canada CIFAR AI Chair @VectorInst.
Full Prof @UofT - Statistics and Computer Sci. (x-appt) danroy.org
I study assumption-free prediction and decision making under uncertainty, with inference emerging from optimality.
Blog: https://argmin.substack.com/
Webpage: https://people.eecs.berkeley.edu/~brecht/
Associate Professor, School of Information, UC Berkeley. NLP, computational social science, digital humanities.
Associate prof at @UMich in SI and CSE working in computational social science and natural language processing. PI of the Blablablab blablablab.si.umich.edu
LM/NLP/ML researcher ¯\_(ツ)_/¯
yoavartzi.com / associate professor @ Cornell CS + Cornell Tech campus @ NYC / nlp.cornell.edu / associate faculty director @ arXiv.org / researcher @ ASAPP / starting @colmweb.org / building RecNet.io
Asst prof @ University of Utah · NLP · she/her 🇭🇷
Asst Prof @uwischool.bsky.social; #NLP #healthinformatics #accessibility #scholcomm
🚴🏔️🍄❄️⛷️🧶⚫️⚪️📚🍸in Seattle; llwang.net; she/her
The AI community building the future!
AI safety at Anthropic, on leave from a faculty job at NYU.
Views not employers'.
I think you should join Giving What We Can.
cims.nyu.edu/~sbowman
Cofounder & CTO @ Abridge, Raj Reddy Associate Prof of ML @ CMU, occasional writer, relapsing 🎷, creator of d2l.ai & approximatelycorrect.com
asst prof of computer science at cu boulder
nlp, cultural analytics, narratives, communities
books, bikes, games, art
https://maria-antoniak.github.io
Associate professor at IT University of Copenhagen: NLP, language models, interpretability, AI & society. Co-editor-in-chief of ACL Rolling Review. #NLProc #NLP
CS professor at NYU. Large language models and NLP. he/him
Associate professor of computer science at Northeastern University. Natural language processing, digital humanities, OCR, computational bibliography, and computational social sciences. Artificial intelligence is an archival science.
John C Malone Professor, Johns Hopkins Computer Science
Director, Data Science and AI (DSAI) Institute
Center for Language and Speech Processing, Malone Center for Engineering in Healthcare.
Part-time: Bloomberg LP #nlproc




















