Just enrolled in the 2025 𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠 𝐙𝐨𝐨𝐦𝐜𝐚𝐦𝐩 by DataTalksClub! 🚀
Can't wait to explore data engineering and grow with an amazing cohort. Big shoutout to DataTalksClub for this awesome opportunity!
#DataEngineering #LearningInPublic
14.01.2025 03:12 — 👍 1 🔁 0 💬 0 📌 0
For those who don’t feel like they fit into my Grumpy Machine Learners list (which I still need to update based on 100+ requests) I’ve created another starter pack:
go.bsky.app/Js7ka12
(Self) nominations welcome.
22.11.2024 18:40 — 👍 79 🔁 13 💬 37 📌 1
The Ultimate Guide to PyTorch Contributions
Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
For those who wonder about the best way to start contributing to pytorch or open-source projects, here are the top three pointers I'd share:
1. The Ultimate Guide to PyTorch Contributions github.com/pytorch/pyto...
For pytorch core that should be the n1 item on your list.
23.11.2024 14:13 — 👍 18 🔁 3 💬 2 📌 0
Training variance is a thing and no one measures it because research models get trained once to beat the benchmark by 0.2 AP or whatever and then never trained again.
In prod one of the first things we do is train (the same model) a ton over different shuffled splits of the data in order to… 1/3
22.11.2024 22:00 — 👍 46 🔁 6 💬 2 📌 3
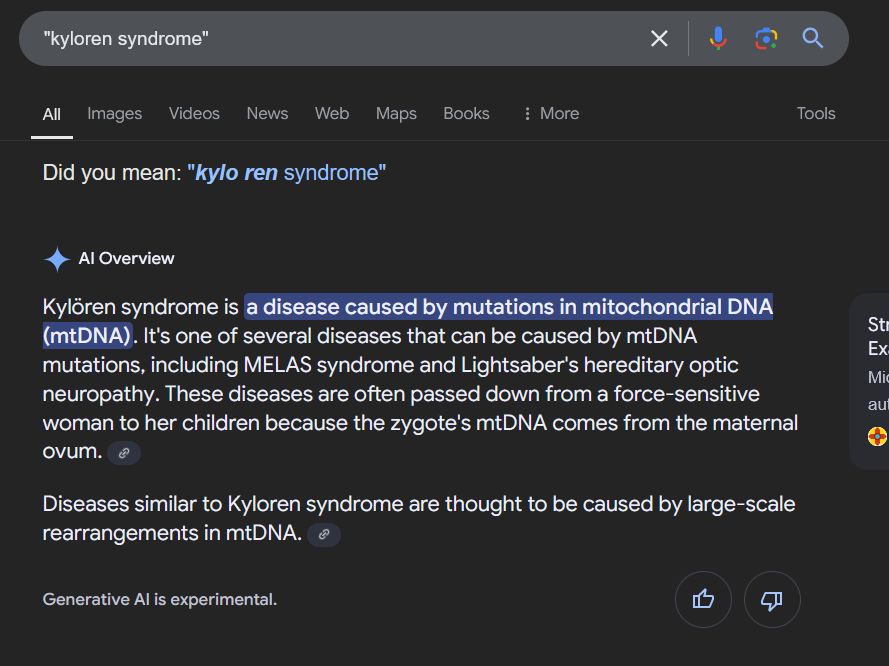
You know the "🔹AI Overview" you get on Google Search?
I discovered today that it's repeating as fact something I made up 7 years ago as a joke.
"Kyloren syndrome" is a fictional disease I invented as part of a sting operation to prove that you can publish any nonsense in predatory journals...
22.11.2024 16:06 — 👍 4623 🔁 1752 💬 124 📌 109
YouTube video by Jeremy Howard
Using Excel for optimization problems
Here's a walk-through of a general-purpose approach to solving many types of optimization problem. It's often not the most efficient way, but it is often fast enough, and it doesn't require using different methods for different problems.
youtu.be/U2b5Cacertc
19.11.2024 23:13 — 👍 128 🔁 5 💬 2 📌 1

Book outline

Over the past decade, embeddings — numerical representations of
machine learning features used as input to deep learning models — have
become a foundational data structure in industrial machine learning
systems. TF-IDF, PCA, and one-hot encoding have always been key tools
in machine learning systems as ways to compress and make sense of
large amounts of textual data. However, traditional approaches were
limited in the amount of context they could reason about with increasing
amounts of data. As the volume, velocity, and variety of data captured
by modern applications has exploded, creating approaches specifically
tailored to scale has become increasingly important.
Google’s Word2Vec paper made an important step in moving from
simple statistical representations to semantic meaning of words. The
subsequent rise of the Transformer architecture and transfer learning, as
well as the latest surge in generative methods has enabled the growth
of embeddings as a foundational machine learning data structure. This
survey paper aims to provide a deep dive into what embeddings are,
their history, and usage patterns in industry.

Cover image
Just realized BlueSky allows sharing valuable stuff cause it doesn't punish links. 🤩
Let's start with "What are embeddings" by @vickiboykis.com
The book is a great summary of embeddings, from history to modern approaches.
The best part: it's free.
Link: vickiboykis.com/what_are_emb...
22.11.2024 11:13 — 👍 653 🔁 101 💬 22 📌 6
Advocate for tech that makes humans better | Spatial Computing, Holodeck, and AI Futurist | Ex-Microsoft, Rackspace | Co-author, "The Infinite Retina."
PhD student @ucberkeley | Projects: Syzygy, R2E, Chatbot-Arena RepoChat | PL Tooling for AI4Code | prev @msftresearch | manishs.org
Interested in how & what the brain computes. Professor in Neuroscience & Statistics UC Berkeley
AI/ML Researcher | Assistant Professor at UT Austin | Postdoc at Princeton PLI | PhD, Machine Learning Department, CMU. Research goal: Building controllable machine intelligence that serves humanity safely. leqiliu.github.io
Assistant Professor of Psychology at the University of Texas at Austin | Studying how people (and AI) reason about the emotions of others
Postdoc at Uppsala University Computational Linguistics with Joakim Nivre
PhD from LMU Munich, prev. UT Austin, Princeton, @ltiatcmu.bsky.social, Cambridge
computational linguistics, construction grammar, morphosyntax
leonieweissweiler.github.io
Compling PhD student @UT_Linguistics | prev. CS, Math, Comp. Cognitive Sci @cornell
http://honglizhan.github.io
PhD Candidate 🤘@UTAustin | previously @IBMResearch @sjtu1896 | NLP for social good
senior undergrad@UTexas Linguistics
Looking for Ph.D position 26 Fall
Comp Psycholing & CogSci, human-like AI, rock🎸 @growai.bsky.social
Prev:
Summer Research Visit @MIT BCS(2025), Harvard Psych(2024), Undergrad@SJTU(2022-24)
Opinions are my own.
I'm a Ph.D. student from the ECE department at UT Austin. I'm supervised by Prof. Jessy Li and Prof. Alex Dimakis.
https://lingchensanwen.github.io/
CS PhD @utaustin.bsky.social
PhD at UTCS | #NLP
https://manyawadhwa.github.io/
许方园👩🏻💻phd student @ nyu, interested in natural language processing
🌍: carriex.github.io
Ph.D. student at the University of Texas in Austin. My interest is in NLP, RL and CogSci research focused on reasoning in AI models.
Principal Scientist at Indeed. PhD Student at UT Austin. AI, Deep Learning, PGMs, and NLP.
CS PhD student @UT Austin studying NLP. Prev:@CornellCIS
Assistant Professor at UT Austin CS | Human-AI Interaction, Accessibility, Creativity | https://amypavel.com/
Assistant Professor CS @ Ithaca College. Computational Linguist interested in pragmatics & social aspects of communication.
venkatasg.net
I hate slop and yet I work on generative models
PhD from UT Austin, applied scientist @ AWS
He/him • https://bostromk.net
UT CS PhD Student working on generative speech models. Prev. Student Researcher @ Google DeepMind, FAIR (Meta AI) and Adobe Research. 2021 BTech CS IIT Bombay.





















