arxiv.org/abs/2601.11432
I want to share an astonishing result. LLMs can "translate" Jabberwocky' texts like 'He dwushed a ghanc zawk” & even and even 'In the BLANK BLANK, BLANK BLANK has BLANK over any BLANK BLANK’s BLANK' This has profound consequence for thinking about.. 1/2
19.01.2026 03:27 —
👍 137
🔁 33
💬 15
📌 12

The influence of bilingualism on statistical word learning: a registered report
Abstract. While statistical word learning has been the focus of many studies on monolinguals, it has received little attention in bilinguals. The results o
@matildellen.bsky.social bravely decided to do a registered report with @pci-regreports.bsky.social as the first manuscript of her PhD -- 2+ years later, it's out! It's on how bilingualism affects statistical word learning, and the results were quite unexpected. Read more:
17.12.2025 21:08 —
👍 13
🔁 6
💬 0
📌 1
PNAS
Proceedings of the National Academy of Sciences (PNAS), a peer reviewed journal of the National Academy of Sciences (NAS) - an authoritative source of high-impact, original research that broadly spans...
Our paper “The cost of thinking is similar between large reasoning models and humans” is now out in PNAS! 🤖🧠
w/ @fepdelia.bsky.social, @hopekean.bsky.social, @lampinen.bsky.social, and @evfedorenko.bsky.social
Link: www.pnas.org/doi/10.1073/... (1/6)
19.11.2025 20:14 —
👍 35
🔁 10
💬 1
📌 1

Italian blasphemy and German ingenuity: how swear words differ around the world
Once swearwords were dismissed as a sign of low intelligence, now researchers argue the ‘power’ of taboo words has been overlooked
A fascinating read in @theguardian.com on the psycholinguistics of swearing!
Did you know Germans averaged 53 taboo words, while Brits e Spaniards listed only 16?
Great to see the work of our colleague Simone Sulpizio & Jon Andoni Duñabeitia highlighted! 👏
www.theguardian.com/science/2025...
23.10.2025 12:27 —
👍 5
🔁 3
💬 0
📌 0

Compositionality in the semantic network: a model-driven representational similarity analysis
Abstract. Semantic composition allows us to construct complex meanings (e.g., “dog house”, “house dog”) from simpler constituents (“dog”, “house”). Neuroim
Important fMRI/RSA study by @marcociapparelli.bsky.social et al. Compositional (multiplicative) representations of compounds/phrases in left IFG (BA45), mSTS, ATL; left AG encodes constituents, not their composition, weighing the right element more, vice versa IFG 🧠🧩
academic.oup.com/cercor/artic...
26.09.2025 09:29 —
👍 9
🔁 4
💬 0
📌 0
Happy to share that our work on semantic composition is out now -- open access -- in Cerebral Cortex!
With Marco Marelli (@ercbravenewword.bsky.social), @wwgraves.bsky.social & @carloreve.bsky.social.
doi.org/10.1093/cerc...
12.09.2025 09:15 —
👍 12
🔁 3
💬 0
📌 1
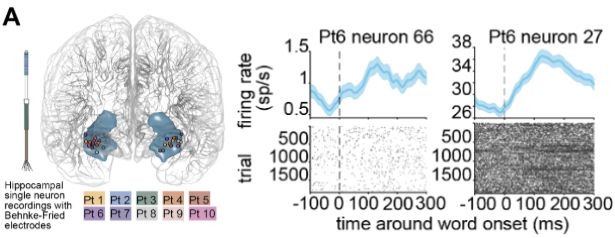
I am incredibly proud to share my first, first-author paper as a postdoc with @benhayden.bsky.social . How does the human hippocampus, known for encoding concepts, represent the meanings of words while listening to narrative speech?
www.biorxiv.org/content/10.1...
27.02.2025 20:17 —
👍 309
🔁 79
💬 12
📌 6

The Neural Consequences of Semantic Composition
Humans can create completely new concepts through semantic composition. These ‘conceptual combinations’ can be created by attributing the features of one concept to another (e.g., a lemon flamingo mig...
Here's a set of new results from my lab asking how the brain combines different ideas (concepts)! Now in press at J of Cog Neuro, we looked at how semantic composition (combining different concepts together) shapes brain activity. Preprint here: www.biorxiv.org/content/10.1... #neuroskyence
26.08.2025 20:24 —
👍 35
🔁 13
💬 2
📌 0

Compare concept representations across modalities in unimodal models, using the AlexNet convolutional neural network to represent images and an LLM to represent their captions
18.07.2025 13:39 —
👍 0
🔁 0
💬 0
📌 0

Perform representational similarity analysis to compare how the same concepts are represented across languages (in their correponding monolingual models) and in different layers of LLMs
18.07.2025 13:39 —
👍 0
🔁 0
💬 1
📌 0

Replace words with sense-appropriate and sense-inappropriate alternatives in the WiC annotated dataset and look at the effects of context-word interaction on embeddings and surprisal
18.07.2025 13:39 —
👍 0
🔁 0
💬 1
📌 0

Extract word embeddings from BERT and inspect how context can modulate their representation. For example, what happens to "fruitless" when we place it in a sentence that points to its typical metaphorical meaning ("vain") as opposed to one where its meaning is literal ("without fruits")?
18.07.2025 13:39 —
👍 0
🔁 0
💬 1
📌 0

I'm sharing a Colab notebook on using large language models for cognitive science! GitHub repo: github.com/MarcoCiappar...
It's geared toward psychologists & linguists and covers extracting embeddings, predictability measures, comparing models across languages & modalities (vision). see examples 🧵
18.07.2025 13:39 —
👍 11
🔁 4
💬 1
📌 0

hidden state representation during training
I’d like to share some slides and code for a “Memory Model 101 workshop” I gave recently, which has some minimal examples to illustrate the Rumelhart network & catastrophic interference :)
slides: shorturl.at/q2iKq
code (with colab support!): github.com/qihongl/demo...
26.05.2025 11:56 —
👍 31
🔁 10
💬 1
📌 0

Characterizing semantic compositions in the brain: A model-driven fMRI re-analysis
Hosted on the Open Science Framework
7/7 Additional compositional representations emerge in left STS and semantic (but not compositional) representations in the left angular gyrus. Check out the preprint for more!
Link to OSF project repo (includes code & masks used):
osf.io/3dnqg/?view_...
28.04.2025 12:37 —
👍 0
🔁 0
💬 1
📌 0
6/7 We find evidence of compositional representations in left IFG (BA45), even when focusing on a data subset where task didn't require semantic access. We take this to suggest BA45 represents combinatorial info automatically across task demands, and characterize combination as feature intersection
28.04.2025 12:37 —
👍 0
🔁 0
💬 1
📌 0

5/7 We conduct confirmatory RSA in four ROIs for which we have a priori hypotheses of ROI-model correspondence (based on what we know of composition in models and what has been claimed of composition in ROIs), and searchlight RSAs in the general semantic network.
28.04.2025 12:37 —
👍 0
🔁 0
💬 1
📌 0
4/7 To better target composition beyond specific task demands, we re-analyze fMRI data aggregated from four published studies (N = 85), all employing two-word combinations but differing in task requirements.
28.04.2025 12:37 —
👍 0
🔁 0
💬 1
📌 0
3/7 To do so, we use word embeddings to represent single words, multiple algebraic operations to combine word pairs, and RSA to compare representations in models and target regions of interest. Model performance is then related to the specific compositional operation implemented.
28.04.2025 12:37 —
👍 0
🔁 0
💬 1
📌 0
2/7 Most neuroimaging studies rely on high-level contrasts (e.g., complex vs. simple words), useful to identify regions sensitive to composition, but less to know *how* constituents are combined (what functions best describe the composition they carry out)
28.04.2025 12:37 —
👍 0
🔁 0
💬 1
📌 0
![from minicons import scorer
from nltk.tokenize import TweetTokenizer
lm = scorer.IncrementalLMScorer("gpt2")
# your own tokenizer function that returns a list of words
# given some sentence input
word_tokenizer = TweetTokenizer().tokenize
# word scoring
lm.word_score_tokenized(
["I was a matron in France", "I was a mat in France"],
bos_token=True, # needed for GPT-2/Pythia and NOT needed for others
tokenize_function=word_tokenizer,
bow_correction=True, # Oh and Schuler correction
surprisal=True,
base_two=True
)
'''
First word = -log_2 P(word | <beginning of text>)
[[('I', 6.1522440910339355),
('was', 4.033324718475342),
('a', 4.879510402679443),
('matron', 17.611848831176758),
('in', 2.5804288387298584),
('France', 9.036953926086426)],
[('I', 6.1522440910339355),
('was', 4.033324718475342),
('a', 4.879510402679443),
('mat', 19.385351181030273),
('in', 6.76780366897583),
('France', 10.574726104736328)]]
'''](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:njnapclhkbrhe3hsq44q2e4w/bafkreibw7fjs4zeocjmfvpr4fo7wikiqenbdz7b3clwq2rolckpoqwkssu)
from minicons import scorer
from nltk.tokenize import TweetTokenizer
lm = scorer.IncrementalLMScorer("gpt2")
# your own tokenizer function that returns a list of words
# given some sentence input
word_tokenizer = TweetTokenizer().tokenize
# word scoring
lm.word_score_tokenized(
["I was a matron in France", "I was a mat in France"],
bos_token=True, # needed for GPT-2/Pythia and NOT needed for others
tokenize_function=word_tokenizer,
bow_correction=True, # Oh and Schuler correction
surprisal=True,
base_two=True
)
'''
First word = -log_2 P(word | <beginning of text>)
[[('I', 6.1522440910339355),
('was', 4.033324718475342),
('a', 4.879510402679443),
('matron', 17.611848831176758),
('in', 2.5804288387298584),
('France', 9.036953926086426)],
[('I', 6.1522440910339355),
('was', 4.033324718475342),
('a', 4.879510402679443),
('mat', 19.385351181030273),
('in', 6.76780366897583),
('France', 10.574726104736328)]]
'''
another day another minicons update (potentially a significant one for psycholinguists?)
"Word" scoring is now a thing! You just have to supply your own splitting function!
pip install -U minicons for merriment
02.04.2025 03:35 —
👍 21
🔁 7
💬 3
📌 0
How do multiple meanings affect word learning and remapping?
🚀 My first PhD paper is out! 🚀
"How do multiple meanings affect word learning and remapping?" was published in Memory & Cognition!
Big thanks to my supervisors and co-authors (Iring Koch & @troembke.bsky.social).
Curious? Read it here: rdcu.be/eeY9o
#CognitivePsychology #WordLearning #Bilingualism
25.03.2025 10:20 —
👍 14
🔁 4
💬 2
📌 0
Conceptual Combination in Large Language Models: Uncovering Implicit Relational Interpretations in Compound Words with Contextualized Word Embeddings
Hosted on the Open Science Framework
13/n In this context, LLMs flexibility allows to generate representations of possible/implicit meanings, which lead to representational drifts proportional to their plausibility.
Data + code available: osf.io/s5edx/?view_...
19.03.2025 14:09 —
👍 0
🔁 0
💬 0
📌 0
12/n Overall, our approach is consistent with theoretical proposals positing that word (and compound word) meaning should be conceptualized as a set of possibilities that might or might not be realized in a given instance of language use.
19.03.2025 14:09 —
👍 0
🔁 0
💬 1
📌 0
11/n Also, bigger model != better: the best layer of BERT consistently outperformed the best layer of Llama. Results align with NLP/cognitive findings showing that LLMs are viable representational models of compound meaning but struggle with genuinely combinatorial stimuli.
19.03.2025 14:09 —
👍 1
🔁 0
💬 1
📌 0

10/n Expectedly, LLMs vastly outperform DSMs on familiar compounds. Yet, unlike DSMs, LLM performance on novel compounds drops considerably. In fact, looking at novel compounds, some DSMs outperform the best layer of BERT and Llama! (image shows model fit; the lower the better).
19.03.2025 14:09 —
👍 1
🔁 0
💬 1
📌 0
9/n As predicted, the closer a paraphrase CWE is to the original compound CWE, the more it was deemed plausible by participants. This holds for familiar compounds rated in isolation, familiar compounds rated in sentential contexts, and novel compounds rated in sentential contexts.
19.03.2025 14:09 —
👍 1
🔁 0
💬 1
📌 0
8/n We reanalyzed possible relation task datasets using BERT-base (widely studied) and Llama-2-13b (representative of more recent, larger, and performant LLMs). As baselines, we used simpler (compositional) DSMs.
19.03.2025 14:09 —
👍 1
🔁 0
💬 1
📌 0

7/n So, we measured the cosine similarity between the CWEs of “snowman” in its original and paraphrased forms and took the result as an estimate of the interpretation's plausibility. In this way, changes in cosine similarity can be more directly attributed to target relations.
19.03.2025 14:09 —
👍 1
🔁 0
💬 1
📌 0

