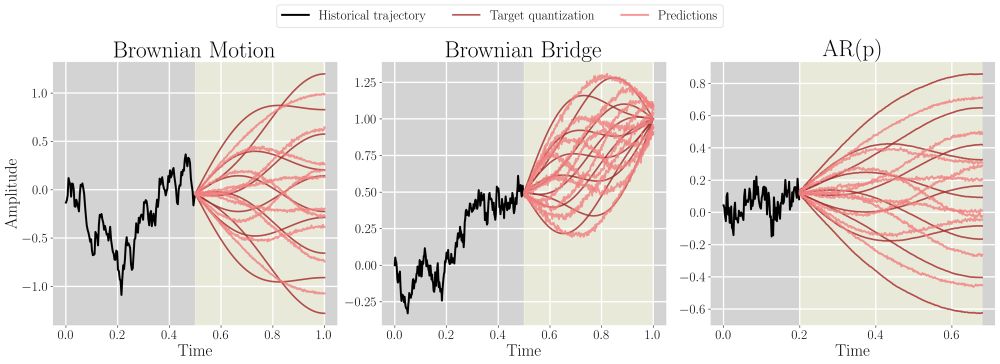
In the Figure below (on synthetic data), you can see how the model learns to align predictions with the target quantization over training steps.
14.07.2025 21:46 — 👍 0 🔁 0 💬 0 📌 0
To ensure the predictions are meaningfully different (not just slight variations), we use a Winner-Takes-All training strategy that updates the best-performing prediction per example. This leads to quantization properties, where the predictions serve as representative prototypes of the future
14.07.2025 21:45 — 👍 0 🔁 0 💬 1 📌 0
In our paper we introduce TimeMCL, a method designed to predict multiple plausible futures for time series data.
TimeMCL builds on a technique called Multiple Choice Learning, which trains a model to generate a diverse set of predictions rather than a single outcome.
14.07.2025 21:45 — 👍 0 🔁 0 💬 1 📌 0
When we try to predict what might happen in the future based on past data, we often find that there isn’t just one “right” answer — there could be several possible future scenarios.
14.07.2025 21:44 — 👍 0 🔁 0 💬 1 📌 0
Interested in time series forecasting or data uncertainty quantification?
Check out our latest paper with Adrien Cortés at @icmlconf !
Paper: arxiv.org/abs/2506.05515
Code: github.com/Victorletzel...
Poster #2211 , Tue 15 Jul 11 a.m. PDT East
#timeseries #quantization #uncertainty #icml2025
14.07.2025 21:40 — 👍 7 🔁 3 💬 1 📌 0

🚗 Ever wondered if an AI model could learn to drive just by watching YouTube? 🎥👀
We trained a 1.2B parameter model on 1,800+ hours of raw driving videos.
No labels. No maps. Just pure observation.
And it works! 🤯
🧵👇 [1/10]
24.02.2025 12:53 — 👍 25 🔁 7 💬 1 📌 2
Inferring 3D human poses from video is highly ill-posed because of depth ambiguity.
Our work accepted to #NeurIPS2024, ManiPose, gets one step closer to solving this, by leveraging prior knowledge about poses topology and cool multiple-choice learning techniques.
04.12.2024 08:00 — 👍 4 🔁 2 💬 1 📌 1
Ph.D. student in Machine Learning and Domain Adaptation for Neuroscience at Inria Saclay/ Mind.
Website: https://tgnassou.github.io/
Skada: https://scikit-adaptation.github.io/
Professor at UT Nuremberg, Germany
I’m 🇫🇷 and I work on RL and lifelong learning. Mostly posting on ML related topics.
full-time ML theory nerd, part-time AI-non enthusiast
The world's leading venue for collaborative research in theoretical computer science. Follow us at http://YouTube.com/SimonsInstitute.
Research Scientist @ Google DeepMind - working on video models for science. Worked on video generation; self-supervised learning; VLMs - 🦩; point tracking.
AI & CV scientist, CEO at @kyutai-labs.bsky.social
🎓 PHD student @ Télécom Paris - ADASP Team
👨💻 Building SSL foundation models for audio and music
Postdoc at Kyutai
http://nicolas-dufour.github.io
Assistant Prof in ML @ KTH 🇸🇪
WASP Fellow
ELLIS Member
Ex: Aalto Uni 🇫🇮, TU Graz 🇦🇹, originally 🇩🇪.
—
https://trappmartin.github.io/
—
Reliable ML | UQ | Bayesian DL | tractability & PCs
Senior Staff Research Scientist @Google DeepMind, former Chair Prof @Oxford Uni
Director, Max Planck Institute for Intelligent Systems; Chief Scientist Meshcapade; Speaker, Cyber Valley.
Building 3D humans.
https://ps.is.mpg.de/person/black
https://meshcapade.com/
https://scholar.google.com/citations?user=6NjbexEAAAAJ&hl=en&oi=ao
Ph.D. student in Machine Learning at Inria.
Website: https://ambroiseodt.github.io/
Blog: https://logb-research.github.io
AI Researcher at valeo.ai
a Ukrainian computer vision researcher escaping Twitter madness 😅
3D Computer Vision & Generative modelling
PhD student @ Inria Paris & @valeoai.bsky.social | Researcher @ Ukrainian Catholic University
https://t-martyniuk.github.io/
AI Research Scientist at Valeo.ai | prev. Sorbonne U | https://yuan-yin.github.io | posts in en/fr/zh
Research Scientist at Valeo.ai.
https://anhquancao.github.io/
Working towards the safe development of AI for the benefit of all at Université de Montréal, LawZero and Mila.
A.M. Turing Award Recipient and most-cited AI researcher.
https://lawzero.org/en
https://yoshuabengio.org/profile/
source: https://arxiv.org/rss/stat.ML
maintainer: @tmaehara.bsky.social



















