Nope, it was our Israel team.
06.11.2025 17:55 — 👍 1 🔁 0 💬 0 📌 0

AstaBench with abstract measurement icons
Agent benchmarks don't measure true *AI* advances
We built one that's hard & trustworthy:
👉 AstaBench tests agents w/ *standardized tools* on 2400+ scientific research problems
👉 SOTA results across 22 agent *classes*
👉 AgentBaselines agents suite
🆕 arxiv.org/abs/2510.21652
🧵👇
06.11.2025 17:01 — 👍 7 🔁 1 💬 1 📌 0
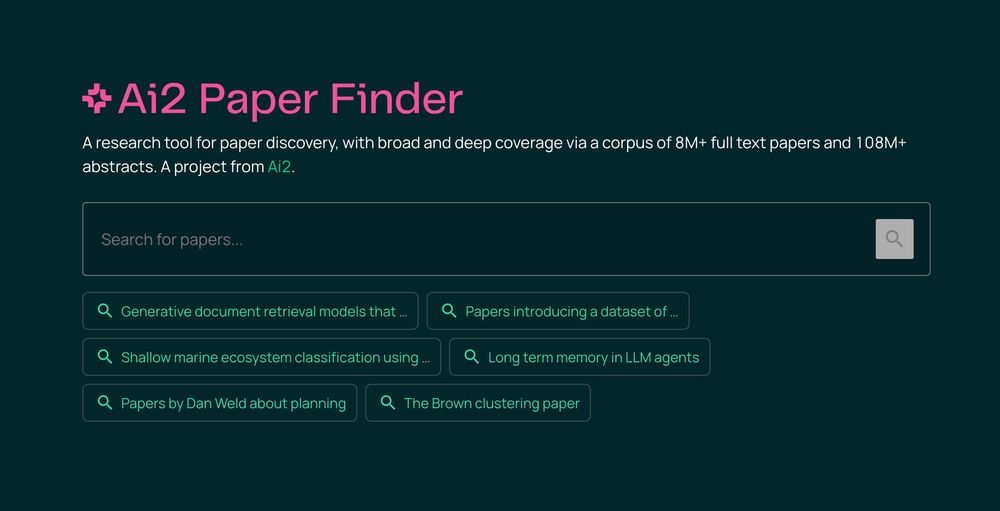
Screenshot of the Ai2 Paper Finder interface
Meet Ai2 Paper Finder, an LLM-powered literature search system.
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
26.03.2025 19:07 — 👍 117 🔁 23 💬 6 📌 9

Ai2 ScholarQA logo, with a red sign that says "Updated!"
Hope you’re enjoying Ai2 ScholarQA as your literature review helper 🥳 We’re excited to share some updates:
🗂️ You can now sign in via Google to save your query history across devices and browsers.
📚 We added 108M+ paper abstracts to our corpus - expect to get even better responses!
More below…
05.03.2025 18:21 — 👍 11 🔁 4 💬 1 📌 0

Ai2 ScholarQA logo
Can AI really help with literature reviews? 🧐
Meet Ai2 ScholarQA, an experimental solution that allows you to ask questions that require multiple scientific papers to answer. It gives more in-depth and contextual answers with table comparisons and expandable sections 💡
Try it now: scholarqa.allen.ai
21.01.2025 19:30 — 👍 33 🔁 12 💬 1 📌 6
 08.01.2025 06:00 — 👍 0 🔁 0 💬 0 📌 0
08.01.2025 06:00 — 👍 0 🔁 0 💬 0 📌 0

The CEO using AI to fight insurance-claim denials says he wants to remove the 'fearfulness' around getting sick
Claimable has helped patients file hundreds of health-insurance appeals. Its CEO says its success rate of overturning denials is about 85%.
Building off the story I shared yesterday about fighting potential Insurance Company AI with AI: Claimable uses AI to tackle insurance claim denials. With an 85% success rate, it generates tailored appeals via clinical research and policy analysis. 🩺 #HealthPolicy
13.12.2024 16:17 — 👍 15 🔁 6 💬 1 📌 3
(3) they also studied multiple rounds of the above. iterative self improvement. saturation happens after 2 or 3 rounds. I'm surprised it's not 1!
(4) Ensemble Heuristic: Simple verification ensemble heuristics can improve performance
6/6
13.12.2024 03:35 — 👍 0 🔁 0 💬 0 📌 0
(2) CoT Verification is More Stable than MC: "Some MC verification incurs non-positive gap even for medium-sized models such as Qwen-1.5 14/32B, while CoT verification always has a positive gap for medium/large-sized models"
5/n
13.12.2024 03:35 — 👍 0 🔁 0 💬 1 📌 0
Results
(1) Small Models can not Self-improve. Models such as Qwen-1.5, 0.5B, Qwen-2 0.5B and Llama-2 7B, gap(f ) is non-positive for nearly all verification methods, even though the models have non-trivial generation accuracy
4/n
13.12.2024 03:35 — 👍 1 🔁 0 💬 1 📌 0
(3) Then they compute the gap which is the average accuracy diff between the filtered generations (those that are correct after step 2 according to self-verification) and the original 128 responses.
3/n
13.12.2024 03:35 — 👍 0 🔁 0 💬 1 📌 0
(2) For each of the 128, they sample one verification for each response of one of 3 styles: (a) correct vs incorrect, (b) CoT + score 1 to 10, or (c) "Tournament" style, which you can find in the paper.
2/n
13.12.2024 03:35 — 👍 0 🔁 0 💬 1 📌 0
Check out our #NeurIPS2024 poster (presented by my collaborators Jacob Chen and Rohit Bhattacharya) about “Proximal Causal Inference With Text Data” at 5:30pm tomorrow (Weds)!
neurips.cc/virtual/2024...
11.12.2024 01:10 — 👍 12 🔁 4 💬 1 📌 0
Can you imagine how good BESTERSHIRE sauce tastes?!?!
09.12.2024 20:39 — 👍 20 🔁 2 💬 4 📌 0
Windows has issue:
Person: fuck this I'm going to Linux
Narrator: and they quickly learned to hate two operating systems.
26.11.2024 16:48 — 👍 9829 🔁 741 💬 363 📌 90
Thanks!
26.11.2024 02:31 — 👍 0 🔁 0 💬 0 📌 0
If you know papers or blog posts that address these, I'd be happy to have the links. Thanks!
22.11.2024 17:59 — 👍 1 🔁 0 💬 0 📌 0
(7) Others found a good recipe for distilling: first fine-tune the biggest model on small gold data, then use that fine-tuned model to make silver data. Does that work for IR distilling? If we fine-tune a 405b before using it as the silver data source, what should we use as gold? How much do I need?
22.11.2024 17:59 — 👍 1 🔁 0 💬 1 📌 0
(6) You can get better LLM labels if you do all pair comparisons on the passage set (citation needed, but I read a few papers showing this). Obviously much more expensive. Should I spend my fixed computer/money budget on all-pairs O(few_queries * passages^2) or pointwise O(more_queries * passages)?
22.11.2024 17:59 — 👍 0 🔁 0 💬 1 📌 0
(5) Does the type of base model to be distilled matter much? Should I distill roberta-large or some modern 0.5b LM?
22.11.2024 17:59 — 👍 0 🔁 0 💬 1 📌 0
(4) From our experience at AI2, LLM-generated search queries are weirdly out of distribution and non-human in various ways. Does this matter? Do we have to get human queries?
22.11.2024 17:59 — 👍 0 🔁 0 💬 1 📌 0
(3) Can we do better than human labeled data because we have no gaps in the labels? And can get more data at will?
22.11.2024 17:59 — 👍 0 🔁 0 💬 1 📌 0
(2) How to distill well? Do we use the same loss functions that we used when obtaining gold data from human labelers?
22.11.2024 17:59 — 👍 0 🔁 0 💬 1 📌 0
(1) Say I have 10000 queries and 100 passages/docs for each query, labeled or ranked by the best LLM (with optimized prompt or fine-tuning), how close can we get to the LLM's performance? Result is a plot with number of distilled model parameters on the x-axis and NDCG vs LLM on y-axis.
22.11.2024 17:59 — 👍 1 🔁 0 💬 2 📌 0
Here are some research questions I'd like to get answers to. We are using LLMs to make training data for smaller, portable search or retrieval relevance models. (thread)
22.11.2024 17:59 — 👍 2 🔁 0 💬 1 📌 0

Image of an email from a student asking if sources "from the late 1900s" are acceptable.
I will never recover from this student email.
27.11.2023 21:48 — 👍 9434 🔁 2346 💬 380 📌 455
#mlsky
20.11.2023 23:22 — 👍 0 🔁 0 💬 0 📌 0
www.semanticscholar.org/paper/Ground...
I really like this paper. They study whether LLMs do reasonable things like ask follow-up questions and acknowledge what the users are saying. The answer is "not really".
20.11.2023 23:22 — 👍 1 🔁 1 💬 1 📌 0
bsky.app/profile/did:...
07.11.2023 23:10 — 👍 1 🔁 0 💬 0 📌 0
Director of the Center for the Advancement of Progress
Machine Learning PhD Student
@ Blei Lab & Columbia University.
Working on probabilistic ML | uncertainty quantification | LLM interpretability.
Excited about everything ML, AI and engineering!
NYU professor, Google research scientist. Good at LaTeX.
Cofounder & CTO @ Abridge, Raj Reddy Associate Prof of ML @ CMU, occasional writer, relapsing 🎷, creator of d2l.ai & approximatelycorrect.com
Postdoc @ai2.bsky.social & @uwnlp.bsky.social
Tenure-track faculty at the Max Planck Institute for Software Systems
Previously postdoc at UW and AI2, working on Natural Language Processing
Recruiting PhD students!
🌐 https://lasharavichander.github.io/
NLP research - PhD student at UW
AI, RL, NLP, Games Asst Prof at UCSD
Research Scientist at Nvidia
Lab: http://pearls.ucsd.edu
Personal: prithvirajva.com
assistant professor, @ltiatcmu.bsky.social. machine learning: LLMs and climate. 🏳️🌈🏳️⚧️ they/them/dad (2 dogs).
pro-AI, anti-capitalist, anti-fascist.
Website: strubell.github.io
Asst Prof @UMD Info College. NLP, computational social science, political communication, linguistics. Past: Data Science Postdoc @UChicago, Info PhD @UMich, CS + Lx @Stanford. Interests: cats, Yiddish, talking to my cats in Yiddish.
Researcher & entrepreneur | Co-founder @cosmik.network | Building @semble.so | collective sensemaking | https://ronentk.me/ | Ecosystem building @atproto.science @cairos.network | Prev- Open Science Fellow @asterainstitute.bsky.social
Senior Lecturer at @CseHuji. #NLPROC
schwartz-lab-huji.github.io
UC Berkeley/BAIR, AI2 || Prev: UWNLP, Meta/FAIR || sewonmin.com
https://ananyahjha93.github.io
Second year PhD at @uwcse.bsky.social with @hanna-nlp.bsky.social and @lukezettlemoyer.bsky.social
🤖 Building AI agents & interactive environments: 🌍 AppWorld (https://appworld.dev) #NLProc PhD @stonybrooku. Past intern Allen AI & visitor CILVR at NYU.
🐦 https://x.com/harsh3vedi
🌐 https://harshtrivedi.me/
https://cs.stanford.edu/~rewang
AI & Education ✨ On academic+industry job market. CS PhD @stanfordnlp
prev: MIT 2020, Google Brain, Google Brain Robotics,
@allen_ai
Ph.D. student at University of Washington CSE. NLP. IBM Ph.D. fellow (2022-2023). Meta student researcher (2023-) . ☕️ 🐕 🏃♀️🧗♀️🍳
Social Reasoning/Cognition + AI, Postdoc at NVIDIA | Previously @ai2.bsky.social | PhD from Seoul Natl Univ.
http://hyunwookim.com
Working on #NLProc for social good.
Currently at LTI at CMU. 🏳🌈
Research Scientist @allen_ai & Affiliate Assistant Prof @UW; Researching on LLM alignment, eval, synthetic data, reasoning, agent. Ex: Google, Meta FAIR;
























